ElasticSearch的工作原理
启动过程
当ElasticSearch的节点启动后,它会利用多播(multicast)(或者单播,如果用户更改了配置)寻找集群中的其它节点,并与之建立连接。这个过程如下图所示
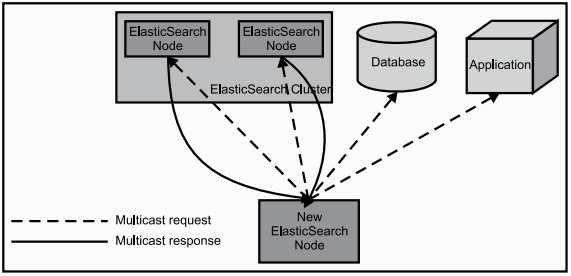
在集群中,一个节点被选举成主节点(master node)。这个节点负责管理集群的状态,当群集的拓扑结构改变时把索引分片分派到相应的节点上。


需要注意的是,从用户的角度来看,主节点在ElasticSearch中并没有占据着重要的地位,这与其它的系统(比如数据库系统)是不同的。实际上用户并不需要知道哪个节点是主节点;所有的操作需求可以分发到任意的节点,ElasticSearch内部会完成这些让用户感到不明觉历的工作。在必要的情况下,任何节点都可以并发地把查询子句分发到其它的节点,然后合并各个节点返回的查询结果。最后返回给用户一个完整的数据集。所有的这些工作都不需要经过主节点转发(节点之间通过P2P的方式通信)。
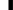
主节点会去读取集群状态信息;在必要的时候,会进行恢复工作。在这个阶段,主节点会去检查哪些分片可用,决定哪些分片作为主分片。处理完成后,集群就会转入到黄色状态。
这意味着集群已经可以处理搜索请求了,但是还没有火力全开(这主要是由于所有的主索引分片(primary shard)都已经分配好了,但是索引副本还没有)。接下来需要做的事情就是找到复制好的分片,并设置成索引副本。当一个分片的副本数量太少时,主节点会决定将缺少的分片放置到哪个节点中,并且依照主分片创建副本。所有工作完成后,集群就会变成绿色的状态(表示所有的主分片的索引副本都已经分配完成)。
探测失效节点
在正常工作时,主节点会监控所有的节点,查看各个节点是否工作正常。如果在指定的时间里面,节点无法访问,该节点就被视为出故障了,接下来错误处理程序就会启动。集群需要重新均衡——由于该节点出现故障,分配到该节点的索引分片丢失。其它节点上相应的分片就会把工作接管过来。换句话说,对于每个丢失的主分片,新的主分片将从剩余的分片副本(Replica)中选举出来。重新安置新的分片和副本的这个过程可以通过配置来满足用户需求。更多相关信息可以参看 第4章 分布式索引架构。
由于只是展示ElasticSearch的工作原理,我们就以下图三个节点的集群为例。集群中有一个主节点和两个数据节点。主节点向其它的节点发送Ping命令然后等待回应。如果没有得到回应(实际上可能得不到回复的Ping命令个数取决于用户配置),该节点就会被移出集群。
与ElasticSearch进行通信
我们已经探讨了ElasticSearch是如何构建起来的,但是归根到底,最重要的是如何往ElasticSearch中添加数据以及如何查询数据。为了实现上述的需求,ElasticSearch提供了精心设计的API。这些主要的API都是基于REST风格(参看http://en.wikipedia.org/wiki/Pepresentational_state_transfer )。而且这些API非常容易与其它能够处理HTTP请求的系统进行集成。
ElasticSearch认为数据应该伴随在URL中,或者作为请求的主体(request body),以一种JSON格式(http://en.wikipedia.org/wiki/JSON )的文档发送给服务器。如果读者用Java或者其它运行在JVM虚拟机上的语言,应该关注一下Java API,它除了是群集中内置的REST风格API外,功能与URL请求是一样的。
值得一提的是在ElasticSearch内部,节点之间的通信也是用相关的Java API。如果想了解关于Java API更多的内容,可以阅读 第8章 ElasticSearch Java API ,但是现在还是简要了解一下本章提供的一些API的功能和使用方法。注意本章仅仅是对相关知识的简单提点(作者会假定读者已经使对这些知识有所了解)。如果事先没有了解相关知识,强烈建议读者去学习一下。比如本书就覆盖了所有的知识点。
索引数据
ElasticSearch提供了4种索引数据的办法。最简单的是使用索引API,索引API。通过它可以将文档添加到指定的索引中去。比如,通过curl工具(访问http://curl.haxx.se/ ),我们可以通过如下的命令创建一个新的文档:
curl -XPUT http://localhost:9200/blog/article/1 -d '{"title": "New version of Elastic Search released!", "content": "...",}'
"tags": ["announce", "elasticsearch", "release"]
第2种和第3种办法可以通过bulk API和UDP bulk API批量添加文档。通常的bulk API采用HTTP协议,UDP bulk API采用非连接的数据包协议。UDP协议传输速度会更快,但是可靠性要差一点。最后一种办法就是通过river插件。river运行在ElasticSearch集群的节点上,能够从外部系统中获取数据。
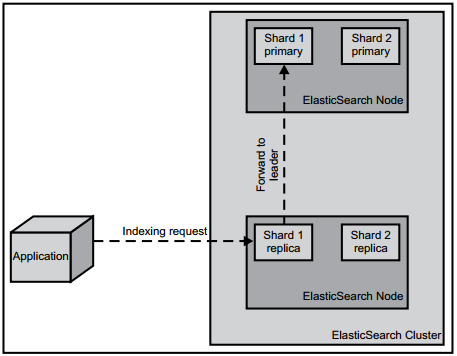
有一点需要注意,索引数据的操作只会发生在主分片(primary shard)上,而不会发生在分片副本(Replica) 上。如果索引数据的请求发送到的节点没有合适的分片或者分片是副本,那么请求会被转发到含有主分片的节点。
数据查询
查询API在ElasticSearch中有着很大的比重。通过使用Query DSL(基于JSON,用来构建复杂查询的语言) ,我们能够:
- 使用各种类型的查询方式,包括:简单的关键词查询(termquery) ,短语(phrase)、区间(range)、布尔(boolean)、模糊(fuzzy)、跨度(span)、通配符(wildcard)、地理位置(spatial)等其它类型的查询方式。
- 通过组合简单查询构建出复杂的查询。
- 过滤文档,去除不符合标准的文档而且不影响打分排序。
- 查找给定文档的相似文档。
- 查找给定短语的搜索建议和查询短语修正。
- 通过faceting构建动态的导航和数据统计
- 使用prospective search而且找到匹配写定文档的查询语句。(关于prospective search,似乎是一种推送方式。即把用户的查询语句存储到索引中,如果新的文档添加到索引中,就把文档关联到匹配的查询语句中。这种查询适合于新闻、博客等会定时更新的应用场景)
关于数据查询,其核心点在于查询过程不是一个简单、单一的流程。通常这个过程分为两个阶段:查询分发阶段和结果汇总阶段。在查询分发阶段,会从各个分片中查询数据;在结果汇总阶段,会把从各个分片上查询到的结果进行合并、排序等其它处理过程,然后返回给用户。
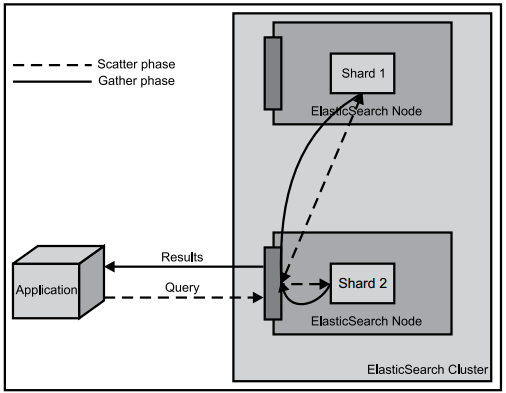
用户可以通过指定搜索类型来控制查询的分发和汇总过程,目前搜索类型只有6种可选值。在Packt的出版的《ElasticSearch Server》一书中,已经讲述了查询范围(query scope)这一知识点.
索引参数设置
前面已经提到ElasticSearch索引参数的自动化配置和文档结构及域类型的自动识别。当然,ElasticSearch也允许用户自行修改默认配置。用户可以自行配置很多参数,比如通过mapping配置索引中的文档结构,设置分片(shard)和副本(replica)的的个数,设置文本分析组件……
集群管理和监控
通过管理和监控部分的API,用户可以更改集群的设置。比如调整节点发现机制(discovery mechanism) 或者更改索引的分片策略。用户可以查看集群状态信息,或者每个节点和索引和统计信息。集群监控的API非常广泛,相关的使用案例将会在 第5章 管理ElasticSearch。