第一章 最低限度的ruby知识
为了方便第一部分的解说,在这里简单介绍一下ruby的基本知识。这里不会系统介绍编程的技巧方面的东西,读完这章节也不会让你掌握ruby的编程方法。如果读者已经有ruby的经验,那就可以直接跳过本章节。
另外我们会在第二部分不厌其烦地讲解语法,于是在这一章节我们尽量不涉及语法相关内容。关于hash,literal之类的表示方法我们会采用经常使用的方式。可以省略的东西原则上我们不会省略。这样才会使语法看起来简单,但是我们不会重复提醒"这里可以省略"。
对象
字符串
ruby程序造作的所有东西都是对象。在ruby里面没有如java里面的 int 或者 long一样的基本数据类型。比如,如下面的例子一样书写的话,就会生成一个内容是"content"的字符串(String)对象。
"content"
刚才说这个只是个字符串的对象,其实正确来讲这个是生成字符串对象的表达式。所以每写一次,都会有新的字符串对象生成。
"content"
"content"
"content"
这里就生成了三个内容是"content"的对象。
但是单纯有对象程序是看不到的。下面教你如何在终端显示对象。
p("content") #显示"content"
"#"之后的东西是注释。接下这个都表示注释。
"p(……)"是调用了函数p。它能够较逼真的表示对象的状态,基本上是一个debug用的函数。
虽然严格意义上讲,ruby里面并不存在函数这个概念。但是现在请先把它当作函数来理解。函数无论在哪里都可以使用。
各种各样的序列
接下来我们来说明一下直接生成对象的序列(literal)。先从一般的整数和小数说起。
# 整数
1
2
100
9999999999999999999999999 # 无论多大的数都可以使用
# 小数
1.0
99.999
1.3e4 # 1.3×10^4
请记住,这些也全部是生成对象的表达式。在这里我们不厌其烦得重复强调,ruby里面是没有基本类型的。
下面是生成数组对象的表达式。
[1,2,3]
这个程序会按顺序生成包含1 2 3 三个元素的数组。数组的元素可以是任何对象。于是也可以有这种表达式。
[1, "string", 2, ["nested", "array"]]
甚至,下面的用法可以来生成哈希表。
{"key"=>"value", "key2"=>"value2", "key3"=>"value3"}
所谓哈希表,是指任何的所有对象之间的一对一的数据结构。按照上述写法会构造出包含下面所示关系的一张表。
"key" → "value"
"key2" → "value2"
"key3" → "value3"
这样生成了哈希表之后,当我们向此对象询问"key对应的值是什么"的时候,它就会告诉我们结果是"value"。那该怎么询问呢?那就要用到方法了。
方法的调用
对象可以调用方法。用c++的话说就是调用成员函数。至于什么是方法,我觉得没有必要说明,还是看一下下面这个简单的例子吧。
"content".upcase()
这里调用了字符串(字符串的内容为"content")的upcase方法。upcase是返回一个将所有小写字母全部变成大写的字符串。于是会有下面的效果。
p("content".upcase()) # 输出"CONTENT"
方法可以连续调用
"content".upcase().downcase()
这个时候调用的是"content".upcase()的返回值对象的downcase方法。
另外,ruby里面没有像Java和C++一样的全局概念。于是所有对象的接口都是通过方法来实现。
程序
顶层
在ruby里面写上一个式子就已经算是一个程序了。没有像C++或者Java一样需要定义main()。
p("content")
仅仅就这样已经算是一个完整的ruby程序。把这个东西复制到first.rb这个文件中然后在命令行执行
% ruby first.rb
"content"
使用选项-e可以不需要创建文件就可以执行代码。
% ruby -e 'p("content")'
"content"
然而要注意到的是,上面p的位置是程序中最外层的东西,也就是说在程序上属于最上层,于是被称作顶层。有层顶是ruby脚本语言的最大特征。
ruby基本上一行就是一句。不需要在句尾加上分号。所以下面的内容实际上是三个语句。
p("content")
p("content".upcase())
p("CONTENT".downcase())
执行结果如下
% ruby second.rb
"content"
"CONTENT"
"content"
局部变量
ruby中所有的变量和常量都仅仅是对对象的引用(reference)。所以仅仅是带入其他变量的话并不会发生复制之类的行为。 这个可以联想到Java中的对象型变量,以及C++中的指向对象的指针。但是指针的值无法改变。
ruby仅看变量的首字母就可以分别出变量的种类。小写阿拉伯字母或者下划线开始的变量属于局部变量。使用等于号=代入赋值。
str = "content"
arr = [1,2,3]
一开始代入的时候不需要声明变量,另外无论变量是什么类型,代入方法都没有区别。下面的写法都是合法的。
lvar = "content"
lvar = [1,2,3]
lvar = 1
当然,虽然可以这么写但是完全没有必要故意写成这样。把种类各样的对象放在一个变量中会使得代码变得晦涩难懂。现实中很少有如此的写法,在这里我们仅仅是举个例子。
变量内容查询也是常用的。
str = "content"
p(str) # 结果显示"content"
下面我们从变量持有对象的引用的观点来看下面的例子。
a = "content"
b = a
c = b
执行这个程序之后,变量a,b,c三个局部变量指向的都是同一个对象,也就是第一行生成的"content"这个字符串对象。
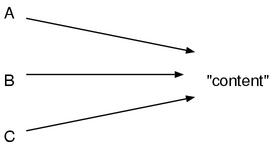
图1: Ruby的变量拥有对对象的引用
这里我们注意到,一直在说的局部变量,那么这个局部必然是针对某个范围的局部。但是请稍等片刻我们再做解释。总之我们先可以说顶层也是一个局部的作用域。
常量
名称首字母是大写的称作常量。所谓常量就是只能代入赋值一次。
Const = "content"
PI = 3.1415926535
p(Const) # 输出"content"
带入两次的话会发生错误。虽然按道理是这样,但是实际运行的时候却不会有错误例外发生。这个是为了保证执行ruby程序的应用程序,比如说在同一个开发环境下,读入两个同样的文件的时候不至于产生错误。也就是说是为了实用性而不得不做出的牺牲,万不得已才取消了错误提示。实际上在Ruby1.1之前是会报错的。
C = 1
C = 2 # 实际上只会给出警告,最理想的还是要做成会显示错误
接下来,被常量这个称呼欺骗的人肯定有很多。常量指的是"一旦保存了所要指向的对象就不再会改变"这个意思。而常量指向的对象并不是不会发生变化。如果用英语来说,比起constant这个意思,还是read only来的比较贴切。(图2)。顺带一提,如果要使对象自身不发生变化可以用freeze这个方法来实现。
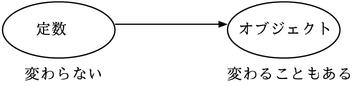
图2: 常量是read only的意思
另外这里还没有提到常量的作用域。我们会在下一节的类的话题中来说明。
流程控制
Ruby的流程控制结构很多要列举的话举不胜举。总之就介绍一下基本的if和while。
if i < 10 then
# 内容
end
while i < 10 do
# 内容
end
在条件语句中只有false和nil两个对象是假,其他所有对象的都属于真。当然0和空字符串也是真。
顺带一提,只有false的话感觉不怎么美观,于是当然也有true,当然true是属于真。
最纯粹的面向对象的系统中,方法都是对象的附属物。但是那毕竟只是一个理想。在普通的程序中会有大量的拥有相同方法集合的对象。如果还傻傻的以对象为单位来调用方法那就会造成内存的大大的浪费。于是一般的方法是使用类或者multi-method来避免重复定义。
ruby采用了传统上来连接方法和对象的结构,类。也就是所有的对象都必须属于唯一的一个类,这个对象能够调用的方法也友这个类来决定。这个时候对象通常被叫做“某某类的实例”。
例如"str"就是类String的实例。另外,String这个类还定义了upcase,downcase,strip等一系列其他方法,仿佛就是在说所有的字符串对象都可以利用这些方法一样。
# 大家都属于同一个String类于是拥有相同的方法。
"content".upcase()
"This is a pen.".upcase()
"chapter II".upcase()
"content".length()
"This is a pen.".length()
"chapter II".length()
那么,如果调用的方法没有事前定义会发生什么呢?在静态的语言中,编译器会报错,而在ruby中,执行的时候会抛出例外。我们来实际尝试一下。这点长度的话直接在命令行用-e就好了。
% ruby -e '"str".bad_method()'
-e:1: undefined method `bad_method' for "str":String (NoMethodError)
找不到方法的时候会发生NomethodError这个错误。
另外最后,每次都说一遍类似“String的upcase方法”太烦了,于是我们下面就用“String#upcase”来表示“在String的类中定义好的upcase方法”。
顺带一提,如果写成“String.upcase”在ruby中就又是另一个意思了。
类的定义
到目前为止都是针对已经定义好的类。当然我们也可以自己来定义类。定义类的时候使用class关键字。
class C
end
这样就定义了C这个类。定义好之后可以有以下的使用。
class C
end
c = C.new() # 生成类C的实例带入c中。
注意生成实例的写法不是new C。恩,好像C.new这个写法在调用方法一样呢。如果你这样想,那说明你很聪明。Ruby生成对象的时候仅仅是调用了方法而已。
首先在Ruby里面类名和常量名是一个概念。那么类名和同名的常量的内容到底是什么呢?实际上里面是类。在Ruby中一切都是对象,那么当然类也是对象了。我们姑且将其称作类对象。所有的类对象都是Class这个类的实例。
也就是说class这个写法,完成的是生成新的类对象的实例,并且将类名带入和它同名的常量中这一系列操作。同时,生成实例,实际上是参照常量名,对该类对象调用方法(通常是new方法)的操作。看完下面的例子你就应该会明白生成实例和普通的调用方法根本就是一回事。
S = "content"
class C
end
S.upcase() # 获取常量S所指的对象并调用upcase方法。
C.new() # 获取常量C所指的对象并调用new方法。
因此,在Ruby里面new并不是保留词。 另外我们也可以用p来显示刚刚生成的类的实例。
class C
end
c = C.new()
p(c) # #<C:0x2acbd7e4>
当然不可能像字符串和整数那样漂亮地显示出来,显示出来的是类内部的ID。顺带一提这个ID其实是指向对象的指针的值。
对了。差点忘了说明一下方法名的写法。Object.new是类对象Object调用自己的方法new的意思。Object#new和Object.new完全是两码事情,必须严格区分。
obj = Object.new() # Object.new
obj.new() # Object#new
在刚刚的例子中因为还没定义Object#new方法所以第二行会报错。我们就当是一个写法的例子来理解就好了。
方法定义
就算定义了类如果不定义方法的话一般没有什么太大意义。我们继续定义类C的方法。
class C
def myupcase( str )
return str.upcase()
end
end
定义类用的是def。这个例子中定义了myupcase这个方法。这个方法带一个参数str。和变量同样,没有必要写明返回值的类型和参数的类型。另外参数的个数是没有限制的。
我们来使用一下定义好的方法。方法默认可以从外部调用。
c = C.new()
result = c.myupcase("content")
p(result) # 输出"CONTENT"
当然习惯了之后也没必要每次都带入。下面的写法也是同样的效果。
p(C.new().myupcase("content")) # 同样输出"CONTENT"
self
在执行方法的过程中经常要保存自己是谁(调用方法的实例)这个信息。self可以取得这个信息。在C++或者Java中就是this。我们来确认一下。
class C
def get_self()
return self
end
end
c = C.new()
p(c) # #<C:0x40274e44>
p(c.get_self()) # #<C:0x40274e44>
如上所示,两个语句返回的是用一个对象。也就是说对实例c调用方法的时候slef就是c自身。
那么要如何才能对自身的方法进行调用呢?首先可以考虑通过self。
class C
def my_p( obj )
self.real_my_p(obj) # 调用自身的方法。
end
def real_my_p( obj )
p(obj)
end
end
C.new().my_p(1) # 输出1
但是调用自身的方法每次都要这么表示一下实在是太麻烦。于是可以省略掉self,调用自身的方法的时候直接就可以省略掉调用方法的对象(receiver)。
class C
def my_p( obj )
real_my_p(obj) # 无需指定receiver
end
def real_my_p( obj )
p(obj)
end
end
C.new().my_p(1) # 输出1
实例变量
对象的实质就是数据+代码。这个说法表明,仅仅定义了方法还是不够的。我们需要以对象为单位来保存数据。也就是说我们需要实例变量。在C++里面就是成员变量。
Ruby的变量命名规则很简单,是由第一个字符决定的。实例变量以@开头。
class C
def set_i(value)
@i = value
end
def get_i()
return @i
end
end
c = C.new()
c.set_i("ok")
p(c.get_i()) # 显示"ok"
实例变量和之前的所介绍的变量稍微有点区别,不用代入(也无需定义)也可以可以引用。这个时候会是什么情形呢……我们在之前代码的基础上来试试看。
c = C.new()
p(c.get_i()) # 显示nil
在没有set的情况下调用get,会显示nil。nil是表示什么都没有的对象。明明自身是个对象却表示什么都没有这个的确有点奇怪,但是它就是这么一个玩意儿。
nil也可以用序列来表示。
p(nil) # 显示nil
初始化
到目前为止,正如所见,就算是刚定义好的类只要调用new方法就可以生成实例。的确是这样,但是有时候类也需要特殊的初始化吧。这个时候我们就不是去改变new,而是应该定义initialize这个方法。这样的话,在new中就会调用这个方法。
class C
def initialize()
@i = "ok"
end
def get_i()
return @i
end
end
c = C.new()
p(c.get_i()) # 显示"ok"
严格意义上来说这个初始化只是new这个方法的特殊设计而不是语言层次上的特殊设计。
继承
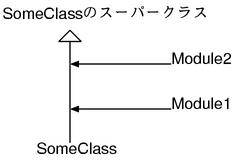
类可以继承其他类。比如说String类就是继承的Object这个类。在本书中将用下图的箭头来表示。

上图的情况下,被继承的类(Object)叫做父类或者上层类,继承的类(String)叫做下层类或者子类。注意这个叫法和C++有所区别。但和Java是一样的喊法。
总之我们来尝试一下,我们来定义一个继承别的类的类。要定义一个继承其他类的类的时候有以下写法。
class C < SuperClassName
end
到目前为止,我们凡是没有标明父类的类的定义,其实继承的都是Object这个父类。
接下来我们考虑一下为什么要继承,当然继承是为了继承方法了。所谓继承,仿佛就是再次重复了一下在父类中第一的方法。
class C
def hello()
return "hello"
end
end
class Sub < C
end
sub = Sub.new()
p(sub.hello()) # 输出"hello"
虽然hello方法是在类C中定义的,但是Sub这个类的实例可以调用这个方法。当然这次不需要带入变量。下面的写法也是同样的效果。
p(Sub.new().hello())
只要在子类中定义相同名字的方法就可以重载。在C++,Object Pascal(Delphi)使用virtual之类的保留字明示除了指定的方法之外无法重载,而在Ruby中所有的方法都可以无条件地重载。
class C
def hello()
return "Hello"
end
end
class Sub < C
def hello()
return "Hello from Sub"
end
end
p(Sub.new().hello()) # 显示"Hello from Sub"
p(C.new().hello()) # 显示"Hello"
另外类可以多层次继承。如图4所示。这个时候Fixnum继承了Object和Numeric以及Integer的所有方法。如果有同名的方法则以最近的类的方法为优先。不存在因类型不同而发生的重载所以使用条件非常简单。
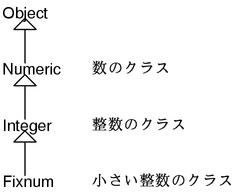
另外C++中可以定义没有继承任何类的类,但是Ruby的类必然是直接或者间接继承Object类的。也就是说继承关系是以Object在最顶端的一棵树。比如说,基本库中的重要的类的继承关系树如图5所示。
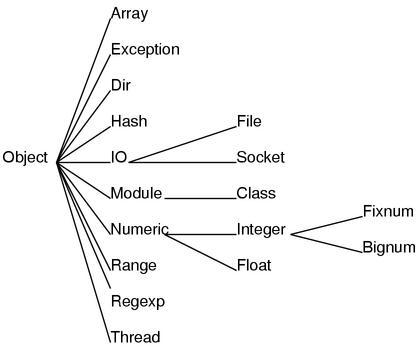
父类被定义之后绝对不会被改变,也就是说在类树中添加新的类的时候,类的位置不会发生变化也不会被删除。
变量的继承……?
Ruby中不继承变量(实例变量)。因为就算想继承,也无法获取类中使用的变量的情报。
但是只要是继承了方法那么调用继承的方法的时候(以子类的实例)会发生实例变量的带入。也就是说会被定义。这样的话实例变来那个的命名空间在各个实例中是完全平坦的,无论是哪个类的方法都可以获取。
class A
def initialize() # 在new的时候被调用
@i = "ok"
end
end
class B < A
def print_i()
p(@i)
end
end
B.new().print_i() # 显示"ok"
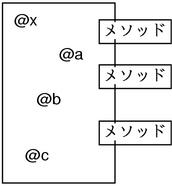
如果无法理解这个行为那么干脆别去考虑类和继承。就想象一下如果类C存在实例obj,那么C的父类的所有方法都在C中有定义。当然也要考虑到重载的罪责。然后现在把C的方法和obj衔接在一起。(图6)
这种强烈的真实感正是Ruby的面向对象的特征。
模块
父类只能指定一个,也就是说Ruby表面上是单一继承的。实际上因为存在模块所以Ruby拥有多重继承的能力。下面我们就来介绍一下模块。
module M
end
这样就定义了模块。在模块里定义方法和类中定义完全一样。
module M
def myupcase( str )
return str.upcase()
end
end
但是因为模块无法生成对象所以是无法直接调用模块里面定义的方法的。那么该怎么办?恩将模块包含进其他的类里面就是了。这样的话模块就仿佛继承了类一样可以被操作了。
module M
def myupcase( str )
return str.upcase()
end
end
class C
include M
end
p(C.new().myupcase("content")) # 显示"CONTENT"
虽然类C根本没有定义任何方法但是可以调用myupcase这个方法。也就是说它继承了模块M的方法。包含的机能和继承完全是一样的,无论是定义方法还是获取实例变量都不受限制。
模块无法指定父类。但是却可以包含其它模块。
module M
end
module M2
include M
end
也就是说这个机能去其实和指定父类是一样的。但是模块上边是不会有类的,模块可以包含的只能是模块。
下面的例子包含了方法继承。
module OneMore
def method_OneMore()
p("OneMore")
end
end
module M
include OneMore
def method_M()
p("M")
end
end
class C
include M
end
C.new().method_M() # 输出"M"
C.new().method_OneMore() # 输出"OneMore"

话说类C如果本身已经存在父类,那么这下子和模块的关系会变成什么样呢?请试着考虑下面的例子。
# modcls.rb
class Cls
def test()
return "class"
end
end
module Mod
def test()
return "module"
end
end
class C < Cls
include Mod
end
p(B.new().test()) # "class"? "module"?
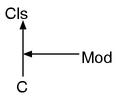
类C继承了类Cls,并且引入了Mod模块。这个时候应该表示"class"呢还是表示"module"呢?换句话说,模块和类哪一个距离更近呢?Ruby的一切都可以向Ruby询问。于是我们来执行看一下结果。
% ruby modcls.rb
"module"
比起父类模块的优先度更高呢!
一般来说,在Ruby中引入模块的话,会在类和父类之间夹带产生一个继承关系,如下图所示。
程序(2)
注意,在本节中出现的内容非常重要,并且主要讲的是一些习惯静态语言思维的人很难习惯的部分。其他的内容可以一眼扫过,而这里请格外注意。我会比较详细地说明。
常量的嵌套
首先复习一下常量。以大写字母开头的是常量。可以以如下方法定义。
Const = 3
要调用这个参数的时候可以如下。
p(Const) # 输出3
其实写成这样也可以。
p(::Const) # 同样输出3
在开头添加::表示是在顶层定义的常量。你可以类比一下文件系统的路径的表示方法。在root目录下有vmunix这个文件。如果是在"/"目录下的话直接输入vmunix就可以获取文件。当然也可以用完整的路径"/vmunix"来表示。Const和::Const也是同样道理。如果是在顶层的话直接用Const就ok,当然使用完整路径版本的::Const也是可以的。
那么类比文件系统目录的东西,在Ruby中是什么呢?那就是类的定义和模块的定义了。因为每次都这么说一遍的话太烦了于是下面统一就用类的定义语句来代替。在类的定义语句中常量的等级会随之上升。(类比进入文件系统的目录)
class SomeClass
Const = 3
end
p(::SomeClass::Const) # 输出3
p( SomeClass::Const) # 同样输出3
SomeClass是在顶层定义的类,也是常量。于是写成SomeClass和::SomeClass都可以。在其中签到的常量Const的路径就变成了::SomeClass::Const
就像在目录中可以继续创建目录一样,在类中也可以继续定义类。例如
class C # ::C
class C2 # ::C::C2
class C3 # ::C::C2::C3
end
end
end
那么问题是,在类定义语句中定义的常量就必须要用完整的路径表示吗?当然不是了。就像文件系统一样,只要在同一层的类定义语句中,就不需要::来获取。如下所示。
class SomeClass
Const = 3
p(Const) # 输出3
end
也许你会感到奇怪。居然在类的定义语句中可以直接书写执行语句。这个也是习惯动态语言的人相当不习惯的部分了。作者当初也是大吃一惊。
姑且再补充说明一点,在方法中也可以获取常量。获取的规则和在类的定义语句中(方法之外)是一样的。
class C
Const = "ok"
def test()
p(Const)
end
end
C.new().test() # 输出"ok"
全部执行
这里从整体出发来写一段代码吧。Ruby中程序的大部分都是会被执行的。常量定义,类定义语句,方法定义语句以及其他几乎所有的东西都会以你看到的顺序依次执行。
例如,请看下面的代码。这段代码使用了目前为止说到的很多结构。
1: p("first")
2:
3: class C < Object
4: Const = "in C"
5:
6: p(Const)
7:
8: def myupcase(str)
9: return str.upcase()
10: end
11: end
12:
13: p(C.new().myupcase("content"))
这个代码将会按照以下的顺序执行。
1: p("first") 输出"first"
3: < Object 通过常量Object获取Object类对象。
3: class C 生成以Object为父类的新的类对象,并将其代入C
4: Const = "in C" 定义::C::Const。值为"in C"
6: p(Const) 输出::C::Const的值。输出结果为"in C"。
8: def myupcase(...)...end 定义方法C#myupcase。
13: C.new().myupcase(...) 通过常量C调用其new方法,并且调用其结果的myupcase方法。
9: return str.upcase() 返回"CONTENT"。
13: p(...) 输出"CONTENT"。
局部常量的作用域
终于说道了局部变量的作用域。
顶层,类定义语句内部,模块定义语句内部,方法自身都各自拥有完全独立的局部变量作用域。也就是说在下面的程序中Ivar这个变量都不一样,也没有相互往来。
lvar = 'toplevel'
class C
lvar = 'in C'
def method()
lvar = 'in C#method'
end
end
p(lvar) # 输出"toplevel"
module M
lvar = 'in M'
end
p(lvar) # 输出"toplevel"
表示上下文的self
以前执行方法的时候自己自身(调用方法的对象)会成为self。虽然这个是正确的说法,但是话只说了一半。实际上不管是在Ruby程序执行到哪里,self总会被具体赋值。也就是说在顶层和在类定义语句中都会有self存在。
顶层是存在self的,顶层的self就是main。没有什么奇怪的规则,main就是Object的实例。其实main也仅仅是为了self而存在的,并没有什么深入的含义。
也就是说顶层的self是main,main则是Object的实例,从顶层也可以直接调用Object的方法。另外在Object中引入了Kernel这个模块,里面存在着诸如p和puts一样函数风格的方法。于是在顶层也可以调用p和puts。
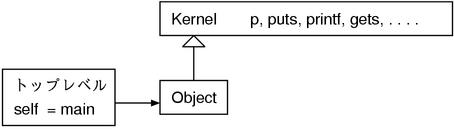
当然p本来就不是函数而是方法。只是因为其定义在Kernel中,无论在哪里,换句话说无论self的类是什么,都可以被当作"自己的"方法来像函数一样被调用。所以Ruby在真正意义上不存在函数。存在的只有方法。
顺带一提,出了p和puts之外,带有函数风格的方法还有print puts printf
sprintf gets forks exec等等等等。大多数都是仿佛曾经在哪里见过的名字。从这个命名中大概也可以想象得出Ruby的性格了吧。
接下来,既然self在那里都会被设定那么在类的定义语句里面也是一样的。在类的定义中self就是类自身(类对象)。于是就会变成这样。
class C
p(self) # C
end
这样设计有什么好处?实际上有个使其好处突出得十分明显的例子。请看。
module M
end
class C
include M
end
实际上这个include是针对类对象C的调用。虽然我们还没有提及,但是很明显Ruby可以省略调用方法的括号。由于到目前还没有结束类定义语句的内容,所以作者为了尽量使其看起来不像方法的调用,而把括号给去掉了。
载入
Ruby中载入库的过程也是在执行中进行。通常这样写。
require("library_name")
为了不被看到的假象所欺骗这里再说一句,require其实是方法,甚至都不是保留语句。这样写的话在写的地方被执行,库里面的代码得以被执行。因为Ruby中不存在像Java里面的包的概念,如果想要将库的命名空间分开来的话,可以建立一个文件夹然后将库放到文件夹里面。
require("somelib/file1")
require("somelib/file2")
于是在库中也可以定义普通的类和模块。顶层的常量作用域和文件并没有多大关联,而是平坦的,于是从一开始就可以获取在其他文件中定义的类。如果想要用命名空间来区分类的名字,可以用下面的方法来显式嵌入模块。
# net 库的例子来使用模块命名空间来区分类
module Net
class SMTP
# ...
end
class POP
# ...
end
class HTTP
# ...
end
end
就类的话题继续深入
还是关于常量
到目前为止用文件系统的例子来类比了常量的作用域。现在请你完全忘掉刚才的例子。
常量里面还有各种各样的陷阱。首先,我们可以获取"外层"类的常量。
Const = "ok" class C p(Const) # 输出"ok" end
为什么要这样?因为可以方便使用命名空间来调用模块。到底怎么回事?我们来用之前Net库的类来做进一步说明。
module Net
class SMTP
# 在方法中可以使用Net::SMTPHelper
end
class SMTPHelper # 辅助Net::SMTP的类
end
end
在这种场合,在SMTP类中只需要写上Net::SMTPHelper就可以进行调用。于是就有了"外层类如果可以调用的话就很方便了"这个结论。
不管外层的类进行了多少层嵌套都可以调用。在不同的嵌套层次中如果定义了同名的常量,会调用从内而外最先找到的变量。
Const = "far"
class C
Const = "near" # 这里的Const比最外层的Const更近一些
class C2
class C3
p(Const) # 输出"near"
end
end
end
真是太特么复杂了。
我们来总结一下吧。在探索常量的时候,首先探索的是外层的类,然后探索父类。例如看下面这个故意写成这么扭曲的例子。
class A1
end
class A2 < A1
end
class A3 < A2
class B1
end
class B2 < B1
end
class B3 < B2
class C1
end
class C2 < C1
end
class C3 < C2
p(Const)
end
end
end
在C3内部想要获取Const的话,会按照下图的顺序进行探索。

注意一点,外层的类的父类,例如A1和B2是不会被探索的。探索的时候所谓的外层仅仅是向外层,父类的话也仅仅是朝着父类的方向。如果不这样的话,会造成探索的类过多,而无法正确预测这个复杂的行为。
meta类
我们说过对象可以调用方法。调用的方法则是对象的类所决定的。那么类对象也一定存在自己所属的类。

这个时候直接和Ruby确认是最好的方法。返回自己所属的类的方法是Object#class。
p("string".class()) # 输出String
p(String.class()) # 输出Class
p(Object.class()) # 输出Class
String貌似属术语Class这个类的。那么进一步Class所属的类是什么呢?
p(Class.class()) # 输出Class
又是Class。也就是说不管是什么对象, 沿着.class().class().class()……总会到达Class,然后陷入循环以致最后。

Class是类的类。我们称拥有"xx的xx"的这种递归构造的的东西"meta xx"。所以Class也被叫做"meta class(类)"。
meta对象
接下来我们改变目标,来考察一下模块。模块也是对象,当然会有其所属的类了。我们来调查一下。
module M
end
p(M.class()) # 输出Module
模块对象的类貌似是Module。那么Module类对象类是什么呢?
p(Module.class()) # Class
答案又是Class。
接下来还个方向继续调查其中的继承关系。Class和Module的父类到底是什么?Ruby中可以通过Class#superclass来进行查看。
p(Class.superclass()) # Module
p(Module.superclass()) # Object
p(Object.superclass()) # nil
Class居然是Module下层的类。根据以上事实可以得到Ruby中重要类的关系图。
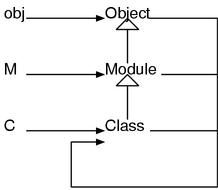
到目前为止我们没有做任何说明就是用了new和include这些东西。现在终于可以解释清楚他们的真实面貌了。new实际上是Class类定义的方法。所以无论是什么类(因为都是Class类的实例)都可以使用new。但是Module里面没有定义new所以无法生成实例。同样,include被定义在Module类中,所以不管是类还是模块都可以调用include。
奇异方法
对象可以调用方法,能调用的方法由对象所属的类来决定,到目前为止我们都这么说。但是作为设计理念我们还是希望方法都是属于对象的。说到底只是因为同样的类定义同样的方法可以省去不少麻烦。
于是实际上在Ruby中是存在不通过类而直接给对象定义的方法的机制的。可以这样写。
obj = Object.new()
def obj.my_first()
puts("My first singleton method")
end
obj.my_first() # My first singleton method
正如你已了解到,Object是所有类的根目录。这么重要的类里面是不会轻易让你定义my_first这种奇怪名字的方法的。另外obj是Object的实例。但是却可以通过obj这个实例来调用my_first这个方法。也就是说,我们定义了和所属类完全无关的方法。这种给对象定义的方法我们称为奇异方法(singleton method)。
那么什么时候使用奇异方法呢?首先是像Java和C++一样定义静态方法的时候。也就是说不需要生成实例就可以使用的方法。这种方法在Ruby里面作为Class类对象的奇异方法而存在。
例如UNIX中存在unlink这种系统调用来删除文件的别名。Ruby中这个方法作为File类的奇异方法可以直接被使用。我们来试一试。
File.unlink("core") # 消去core名称的dump。
每次提到都说一遍"这个是File对象的奇异方法unlink"实在是太麻烦了,下面用"File.unlink"代替。注意不要写成"File#unlink"或者是将"在File类中定义的方法write"错写成"File.write"。
下面是写法的总结
| 写法 | 调用的对象 | 调用的实例 |
|---|---|---|
| File.unlink | File类自身 | File.unlink("core") |
| File#write | File的实例 | f.write("str") |
类变量
类变量是Ruby1.6新增的内容。类变量和变量属于同一个类,可以被类以及类的实例代入,引用。来看一下例子。开头是"@@"就是类变量。
class C
@@cvar = "ok"
p(@@cvar) # 输出"ok"
def print_cvar()
p(@@cvar)
end
end
C.new().print_cvar() # 输出"ok"
类变量也是由最初的定义来赋值代入的,所以在代入之前引用出错。仿佛多加了个"@"就和一般的实例变量不一样了。
% ruby -e '
class C
@@cvar
end
'
-e:3: uninitialized class variable @@cvar in C (NameError)
在这里直接用"-e"命令执行了程序。"'"之间三行是程序正文。
另外类变量是可以继承的。换句话说,子类可以代入,引用父类的类变量。
class A
@@cvar = "ok"
end
class B < A
p(@@cvar) # "ok"
def print_cvar()
p(@@cvar)
end
end
B.new().print_cvar() # "ok"
全局变量
最后姑且说一句,全局变量也是存在的。无论在程序的哪里都可以代入,引用。在变量前加上"$"就成了全局变量。
$gvar = "global variable"
p($gvar) # "global variable"
全局变量和实例变量一样,我们可以看作所有的名称都是在代入之前就被定义好的。所以就算是代入前我们引用这个变量,只会返回nil而不会发生错误。
(第一章完)