第5章 设计和概念
本章为后面的3章打下基础,这几章专注于SQLite编程。这几章专注于作为程序员,在编码时你所应该了解的有关SQLite的东西。无论你是用C语言对SQLite进行编程,还是用其它的编程语言,这些内容都是重要的。它不仅帮助你了解API,还包括部分有关SQLite的体系结构和实现方法的内容。具备了这些知识,你就可以编出更好的代码,这些代码执行得更快,且不会产生死锁、不可预知错误等问题。你会看到SQLite如何处理你的代码,你还会变得更加自信,因为你知道自己正前进在解决问题的正确方向上。
你不需要从头到尾地读内部代码才能理解这些内容,你也不必是一个C程序员。SQLite的设计和概念都是非常直观和容易理解的。只有一小部分内容你需要知道,本章就介绍这些内容。
1.明显地,你需要知道API是如何工作的。于是本章从一个对API概念性的介绍开始,图示了主要的数据结构,API的一般设计和它主要的函数。还可以看到SQLite的一些主要的子系统,这些子系统在查询的处理过程中起着重要作用。
2.除了知道什么函数做什么,你还需要从比API高的角度来看问题,看看所有这些函数在事务(transactions)中是如何操作的。SQLite的所有的工作都是在事务中完成的。于是,你需要知道在API之下,事务如何按照锁的约束来工作。如果你不知道锁是如何操作的,这些锁就会导致问题。当对锁有所了解之后,你不仅可以避免潜在的并发问题,还可以通过编程控制它们来优化你的查询。
3.最后,你还必须理解如何将这些内容应用于编码。本章的最后部分会将3个主题结合在一起——API、事务和锁,并且看一看好代码与坏代码的区别。
空注:本章看得还是比较仔细的,翻译的也比较全。
API
从功能的角度来区分,SQLite的API可分为两类:核心API的扩充API。核心API由所有完成基本数据库操作的函数构成,包括:连接数据库、执行SQL和遍历结果集。它还包括一些功能函数,用来完成字符串格式化、操作控制、调试和错误处理等任务。扩充API提供不同的方法来扩展SQLite,它使你能够创建自定义的SQL扩展,并与SQLite本身的SQL相集成。
SQLite版本3的新特性
在开始之前,我们先讨论一下SQLite版本3的新特色:
一、首先,SQLite的API被彻底重新设计了,并具有了许多新特性。由第二版的15个函数增加到88个函数。这些函数包括支持UTF-8和UTF-16编码的功能函数。SQLite3有一个更方便的查询模式,使查询的预处理更容易并且支持新的参数绑定方法。SQLite3还增加了用户定义的排序序列、CHECK约束、64位的键值和新的查询优化。
二、在后端大大地改进了并发性能。加锁子系统引进了一种新的锁升级模型,解决了第二版中的写进程饿死的问题。这种模型保证写进程按照先来先服务的算法得到排它锁(Exclusive Lock)。甚至,写进程通过把结果写入临时缓冲区(Temporary Buffer),可以在得到排它锁之前就开始工作。这对于写要求较高的应用,性能可提高400%。
三、SQLite 3包含一个改进了的B-tree模型。现在对库表使用B+tree,大大提高查询效率,存储大数据字段更有效,并可以从磁盘上删除不用了的字段。其结果是数据库文件的体积减小了25–35%并改善了全面性能。B+tree将在第9章介绍。
四、SQLite 3最重要的改变是它的存储模型。由第二版只支持文本模型,扩展到支持5种本地数据类型,如第4章所介绍的,还增强了弱类型和类型亲和性的概念。每种类型都被优化,以得到更高的查询性能并战用更少的存储空间。例如,整数和浮点数以二进制的形式存储,而不再是以ASCII形式存储,这样,就不必再对WHERE子句中的值进行转换(像第2版那样)。弱类型使你能够在定义一个字段时选择是否预声明类型。亲和性确定一个值存储于字段的格式——基于值的表示法和列的亲和性。类型亲和性与弱类型紧密关联——列的亲和性由其类型的声明确定。
在很多方面,SQLite 3是一个与SQLite 2完全不同的数据库,并且提供了很多在适应性、特色和性能方面的改进。
主要的数据结构
在第1章你看到了很多SQLite组件——分词器、分析器和虚拟机等等。但是从程序员的角度,最需要知道的是:connection、statements、B-tree和pager。它们之间的关系如图5-1所示。这些对象构成了编写优秀代码所必须知道的3个首要内容:API、事务和锁。
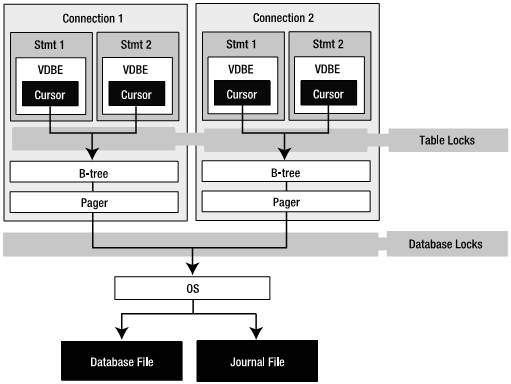
图5-1 SQLite C API对象模型
从技术上来说,B-tree和pager不是API的一部分,但是它们却在事务和锁上起着关键作用。这里只介绍关联的内容,详细内容将在“事务”一节介绍。
连接(Connection)和语句(Statement)
连接(Connection)和语句(Statement)是执行SQL命令涉及的两个主要数据结构,几乎所有通过API进行的操作都要用到它们。连接代表在一个独立的事务环境下的一个单独的数据库连接。每个语句都和一个连接关联,通常表示一个编译过的SQL语句。在内部,它以VDBE字节码表示。语句包括执行一个命令所需要一切,包括保存VDBE程序执行状态所需的资源,指向硬盘记录的B-tree游标,以及参数等等。
B-tree和Pager
一个连接可以有多个database对象——一个主数据库和附加的数据库。每一个数据库对象有一个B-tree对象,一个B-tree有一个pager对象(这里的对象不是面向对象的“对象”,只是为了说清楚问题)。
语句最终都是通过连接的B-tree和pager从数据库读或者写数据,通过B-tree的游标(cursor)遍历存储在页(page)中的记录。在游标访问页之前,页必须从磁盘加载到内存,而这就是pager的任务。任何时候,如果B-tree需要页,它都会请求pager从磁盘读取数据,pager把页加载到页缓冲区(page cache)。之后,B-tree和与之关联的游标就可以访问位于页中的记录了。
如果游标改变了页,为了防止事务回滚,pager必须采取特殊的方式保存原来的页。总的来说,pager负责读写数据库,管理内存缓存和页,以及管理事务、锁和崩溃恢复(这些在“事务”一节会详细介绍)。
总之,关于连接和事务,你必须知道两件事:(1)对数据库的任何操作,一个连接存在于一个事务之下。(2)一个连接绝不会同时存在于多个事务之下。无论何时,一个连接在对数据库做任何操作时,都总是在恰好一个事务之下,不会多,也不会少。
核心API
核心API主要与执行SQL命令有关。有两种方法执行SQL语句:预编译查询和封装查询。预编译查询由三个阶段构成:准备(preparation)、执行(execution)和定案(finalization)。其实封闭装查询只是对预编译查询的三个过程进行了包装而已,最终也会转化为预编译查询来执行。
连接的生命周期(The Connection Lifecycle)
和大多数据库连接相同,其生命周期由三个阶段构成:
1. 连接数据库(Connect to the database)。
2. 处理事务(Perform transactions):如你所知,任何命令都在事务下执行。默认情况下,事务自动提交,也就是每一个SQL语句都在一个独立的事务下运行。当然也可以通过使用BEGIN..COMMIT手动提交事务。
3. 断开连接(Disconnect from the database):关闭数据库文件。还要关闭所有附加的数据库文件。
在查询的处理过程中还包括其它一些行为,如处理错误、“忙”句柄和schema改变等,所有这些都将在utility functions一节中介绍。
连接数据库(Connect to the database):
连接数据库不只是打开一个文件。每个SQLite数据库都存储在单独的操作系统文件中——数据库与文件一一对应。连接、打开数据库的C API为sqlite3_open(),它只是一个简单的系统调用,来打开一个文件,它的实现位于main.c文件中。
SQLite还可以创建内存数据库。如果你使用:memory:或一个空字符串做数据库名,数据库将在RAM中创建。内存数据库将只能被创建它的连接所存取,不能与其它连接共享。另外,内存数据库只能存活于连接期间,一旦连接关闭,数据库就将从内存中被删除。
当连接一个位于磁盘上的数据库时,如果数据库文件存在,则打开该文件;如果不存在,SQLite会假定你想创建一个新的数据库。在这种情况下,SQLite不会立即在磁盘上创建一个文件,只有当你向数据库写入数据时才会创建文件,比如:创建表、视图或者其它数据库对象。如果你打开一个数据库,不做任何事,然后关闭它,SQLite会创建一个文件,但只是一个长度为0的空文件而已。
另外一个不立即创建新文件的原因是,一些数据库的参数,比如:编码,页大小等,只能在数据库创建之前设置。默认情况下,页大小为1024字节,但是你可以选择512-32768字节之间为 2幂数的数字。有些时候,较大的页能更有效地处理大量的数据。你可以使用page_size pragma来设置数据库页大小。
字符编码是数据库的另一个永久设置。你可以使用encoding pragma来设置字符编码,其值可以是UTF-8、UTF-16、UTF-16le (little endian)和UTF-16be (big endian)。
执行预处理查询
前面提到,预处理查询(Prepared Query)是SQLite执行所有SQL命令的方式,包括以下三个步聚:
(1) 准备(preparation):
分词器(tokenizer) 、分析器(parser)和代码生成器(code generator)把SQL语句编译成VDBE字节码,编译器会创建一个语句句柄(sqlite3_stmt),它包括字节码以及其它执行命令和遍历结果集所需的全部资源。相应的C API为sqlite3_prepare(),位于prepare.c文件中。
(2) 执行(execution):
虚拟机执行字节码,执行过程是一个步进(stepwise)的过程,每一步(step)由sqlite3_step()启动,并由VDBE执行一段字节码。当第一次调用sqlite3_step()时,一般会获得一种锁,锁的种类由命令要做什么(读或写)决定。对于SELECT语句,每次调用sqlite3_step()使用语句句柄的游标移到结果集的下一行。对于结果集中的每一行,它返回SQLITE_ROW,当到达结果末尾时,返回SQLITE_DONE。对于其它SQL语句(INSERT、UPDATE、DELETE等),第一次调用sqlite3_step()就导致VDBE执行整个命令。
(3) 定案(finalization):
VDBE关闭语句,释放资源。相应的C API为sqlite3_finalize(),它导致VDBE结束程序运行并关闭语句句柄。如果事务是由人工控制开始的,它必须由人工控制进行提交或回卷,否则sqlite3_finalize()会返回一个错误。当sqlite3_finalize()执行成功,所有与语句对象关联的资源都将被释放。在自动提交模式下,还会释放关联的数据库锁。
每一步(preparation、execution和finalization)都关联于语句句柄的一种状态(prepared、active和finalized)。Pepared表示所有资源都已分配,语句已经可以执行,但还没有执行。现在还没有申请锁,一直到调用sqlite3_step()时才会申请锁。Active状态开始于对sqlite3_step()的调用,此时语句正在被执行并拥有某种锁。Finalized意味着语句已经被关闭且所有相关资源已经被释放。通过图5-2可以更容易地理解该过程:
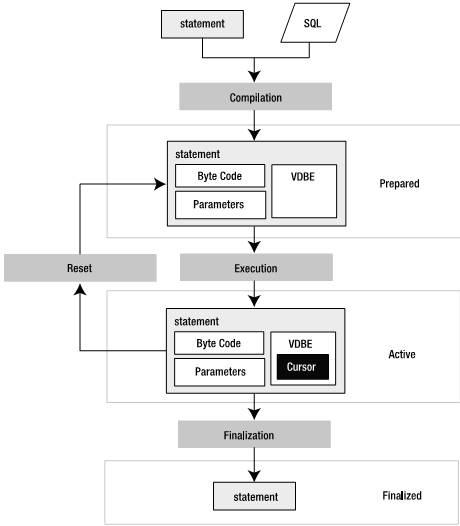
图5-2 语句处理
下面代码例示了在SQLite上执行一个query的一般过程。
#include<stdio.h>
#include<stdlib.h>
#include"sqlite3.h"
#include<string.h>
#pragma comment(lib, "sqlite3.lib")
int main(int argc,char **argv)
{
int rc,i,ncols;
sqlite3 *db;
sqlite3_stmt *stmt;
char *sql;
const char*tail;
//打开数据
rc=sqlite3_open("foods.db",&db);
if(rc){
fprintf(stderr,"Can'topendatabase:%sn",sqlite3_errmsg(db));
sqlite3_close(db);
exit(1);
}
sql="select * from episodes";
//预处理
rc=sqlite3_prepare(db,sql,(int)strlen(sql),&stmt,&tail);
if(rc!=SQLITE_OK){
fprintf(stderr,"SQLerror:%sn",sqlite3_errmsg(db));
}
rc=sqlite3_step(stmt);
ncols=sqlite3_column_count(stmt);
while(rc==SQLITE_ROW){
for(i=0;i<ncols;i++){
fprintf(stderr,"'%s'",sqlite3_column_text(stmt,i));
}
fprintf(stderr,"\n");
rc=sqlite3_step(stmt);
}
//释放statement
sqlite3_finalize(stmt);
//关闭数据库
sqlite3_close(db);
printf("\n");
return(0);
}
空注:
上述代码在VC6++下调试通过,其步骤为:
将上述代码做成一个.cpp文件并为它创建工作空间。
将sqlite3.def和sqlite3.dll文件复制到工作空间所在目录。(这两个文件可由sqlitedll-3_6_18.zip文件解压而得)
进入DOS命令行状态,进入工作空间所在目录,执行如下3条命令:
PATH = D:\Program Files\Microsoft Visual Studio 9.0\VC\bin;%PATH%
PATH = D:\Program Files\Microsoft Visual Studio 9.0\Common7\IDE;%PATH%
LIB /DEF:sqlite3.def /machine:IX86
注:上述命令用于制作.lib文件,用于项目的链接。如果PATH已经设好,前两条命令可能不需要执行;如果执行,可能需要根据VC的安装情况有所改动。
临时存储器:
临时存储器是查询处理的重要组成部分。SQLite有时需要存储命令执行过程中产生的中间结果——如结果集由ORDER BY子句指定需要排序,或进行多表交叉查询时。中间结果存储在临时存储器中。临时存储器或者在内存,或者在文件中。
使用参数化的SQL
SQL语句可以包含参数。参数是SQL命令中的占位符,它们的值会在编译之后提供(称为“绑定”)。下面是带参数的SQL示例语句:
INSERT INTO foods (id, name) VALUES (?,?);
INSERT INTO episodes (id, name) (:id, :name);
上述语句表现了参数的两种绑定方式:按位置和按名称。第1条命令采用了位置参数,第2条命令采用了名称参数。
Positional parameters are defined by the position of the question mark in the statement. The first question mark has position 1, the second 2, and so on. Named parameters use actual variable names, which are prefixed with a colon. When sqlite3_prepare() compiles a statement with parameters, it allocates placeholders for the parameters in the resulting statement handle. It then expects values to be provided for these parameters before the statement is
executed. 如果你没有为参数绑定值,在语句执行时,SQLite 默认为各参数赋NULL值。
使用参数绑定的好处是你可以多次执行相同的语句而不必重新编译它们。You just reset the statement, bind a new set of values, and reexecute. This is where resetting rather than finalizing a statement comes in handy: it avoids the overhead of SQL compilation. By resetting a statement, you are reusing the compiled SQL code. You completely avoid the tokenizing, parsing, and code generation overhead. Resetting a statement is implemented in the API by the sqlite3_reset() function.
使用参数的另一个好处是:SQLite可以对你绑定到参数的字符串值做一定的处理。例如,有一个参数值'Kenny's Chicken',参数绑定过程会自动地将其转化为'Kenny''s Chicken'。下面的伪代码说明了绑定参数的基本方法:
db = open('foods.db')
stmt = db.prepare('INSERT INTO episodes (id, name) VALUES (:id, :name)')
stmt.bind('id', '1')
stmt.bind('name', 'Soup Nazi')
stmt.step()
# Reset and use again
stmt.reset()
stmt.bind('id', '2')
stmt.bind('name', 'The Junior Mint')
# Done
stmt.finalize()
db.close()
执行封装的Query
如前文所述,有两个很有用的函数可以封装查询的预编译过程,允许你在单一的函数调用中执行SQL命令。一个函数是sqlite3_exec(),特别适合执行不需要返回数据的查询。另一个是sqlite3_get_table(),返回一个表格化的结果集。In many language extensions you will see analogs to both functions. Most extensions refer to the first method simply as exec(), and the second as just get_table().
sqlite3_get_table()的函数名起得不太合适,听起来好象是要返回一个表的全部数据。其实它的命名只是表示将会返回一个表格化的结果集。
db = open('foods.db')
table = db.get_table("SELECT * FROM episodes LIMIT 10")
for i=0; i < table.rows; i++
for j=0; j < table.cols; j++
print table[i][j]
end
end
db.close()
错误处理
前面的例子都是极度简化了的,只关注查询的执行。而在实际情况下,你总得关注出错的可能性。你前面所看到的几乎每个函数在某些情况下都可能引发错误。通常你需要对错误代码SQLITE_ERROR、SQLITE_BUSY和SQLITE_SCHEMA进行处理。SQLITE_BUSY在当前连接不能够获得一个锁时触发,SQLITE_SCHEMA在语句的编译与执行之间schema发生了改变时触发。“忙”状态将在本章的事务一节中介绍。Schema错误将在第6章介绍。
很多语言扩展难于处理schema错误。有些透明地报告处于忙状态,有些直接返回实际的错误代码。无论如何,如果你遇到了schema错误,表示有其它的连接在你的读与写之间改变了数据库,你的语句已不再合法。你需要重新编译语句,以便能够重新执行它。Schema错误只会发生在对prepare()的调用和第1次对step()的调用之间。如果你的第1次step()调用成功,那你就不必再担心在后面调用step()时会引发schema错误了,因为你的连接已经锁住了数据库,其它的连接不可能在此期间修改数据库。
对于一般性错误,API提供了sqlite3_errcode()来获取最后一次调用API函数时的返回码。你可以使用sqlite3_errmsg()函数得到更具体的错误信息,该函数提供了对最后错误的文字描述,大多数语言扩展都支持这个函数。
有了这个观念,前面例子中的每个调用都可以用类似下面的代码来检查错误:
# Check and report errors
if db.errcode() != SQLITE_OK
print db.errmsg(stmt)
end
一般情况下,错误处理并不困难。处理错误的方法由你确切地想要做什么决定。
格式化SQL语句
另一个方便的函数是sqlite3_mprintf(),它是标准C库函数sprintf()的一个变体。它有很独特的替换符,特别方便对SQL进行处理。它的替换符是%q和%Q。%q的工作原理像%s,从参数列表中取得一个以NULL结束的字符串。它会将单引号反斜杠都双写,使你更容易防范SQL注入式攻击(参本节下文的“SQL注入式攻击”一段)。例如:
char* before = "Hey, at least %q no pig-man.";
char* after = sqlite3_mprintf(before, "\he's\");
上述程序执行后after的值为'Hey, at least \he''s\ no pig-man'。The single quote in he’s is doubled along with the backslashes around it, making it acceptable as a string literal in a SQL statement. The %Q formatting does everything %qdoes, but it additionally encloses the resulting string in single quotes. Furthermore, if the argument for %Q is a NULL pointer (in C), it produces the string NULL without single quotes. For more information, see the sqlite3_mprintf() documentation in the C API reference in Appendix B.
SQL注入式攻击:
如果你的应用程序依赖用户的输入来构造SQL语句,那么它将很容易受到SQL注入攻击。如果你没有精心地过滤用户输入,有人可能会输入别有用心的内容,注入到你的SQL中,并在其后面构成一个新的SQL语句。例如,你的程序用用户输入来填充下面SQL语句:
SELECT * FROM foods WHERE name='%s';
如果无论用户输入什么都直接来替换%s,如果用户对你的数据库有一定了解,他可以输入如下内容:
nothing' LIMIT 0; SELECT name FROM sqlite_master WHERE name='%
将用户输入替换进原有的SQL语句之后,变成了两个新的语句:
SELECT * FROM foods WHERE name='nothing' LIMIT 0; SELECT name FROM
sqlite_master WHERE name='%';
第1个语句什么都不返回,但第2个将返回表中所有的记录。Granted, the odds of this happening require quite a bit of knowledge on the attacker’s part, but it is nevertheless possible. Some major (commercial) web applications have been known to keep SQL statements embedded in their JavaScript, which can provide plenty of hints about the database being used. In the previous example, all a malicious user has to do now is insert DROP TABLE statements for every table found in sqlite_master and you could find yourself fumbling through backups.
操作控制
API中包含几个命令来监视、控制,或者说限制数据库操作。SQLite使用过滤(或称回叫)函数来完成此功能,你可以注册它们由特定的事件来调用。有3个“hook”函数:sqlite3_commit_hook(),它监视事务的提交;sqlite3_rollback_hook(),它监视事务的回卷;sqlite3_update_hook(),它监视INSERT、UPDATE和DELETE操作。这些函数在运行时被调用——即当命令执行时被调用。Each hook allows you to register a callback function on a connection-by-connection basis, and lets you provide some kind of application-specific data to be passed to the callback as well. The general use of operational control functions is as follows:
def commit_hook(cnx)
log('Attempted commit on connection %x', cnx)
return -1
end
db = open('foods.db')
db.set_commit_hook(rollback_hook, cnx)
db.exec("BEGIN; DELETE from episodes; ROLLBACK")
db.close()
使用线程
SQLite有几个可以在多线程环境下使用的函数。在3.3.1版中,SQLite引入了一种称为共享缓冲区模式的独特的操作模式,就是为多线程的内嵌式服务器设计的。这个模式提供了一种用单线程来处理多连接的方法,可以共享相同的页缓冲区,从而降低了整个服务器的内存需求。这个模式包括多个函数来管理内存和服务器。详见第6章“共享缓冲区模式”一节。
扩充API
SQLite的扩充API用来支持用户定义的函数、聚合和排序法。用户定义函数是一个SQL函数,它对应于你用C语言或其它语言实现的函数的句柄。使用C API时,这些句柄用C/C++实现。
用户定义的扩展必须注册到一个由连接到连接的基础(connection-by-connection basis)之上,存储在程序内存中。也就是说,它们不是存储在数据库中(就像大型数据库的存储过程一样),而是存储在你的程序中。
创建用户自定义函数
实现一个用户自定义的函数分为两步。首先,写句柄。句柄实现一些你想通过SQL完成的功能。然后,注册句柄,为它提供SQL名称、参数的数量和一个指向句柄的指针。
例如,你想创建一个叫做hello_newman()的SQL函数,它返回文本'Hello Jerry'。在SQLite C API中,先创建一个C函数来实现此功能,如:
void hello_newman(sqlite3_context* ctx, int nargs, sqlite3_value** values)
{
/* Create Newman's reply */
const char *msg = "Hello Jerry";
/* Set the return value. Have sqlite clean up msg w/ sqlite_free(). */
sqlite3_result_text(ctx, msg, strlen(msg), sqlite3_free);
}
不了解C和C API也没关系。这个句柄仅返回'Hello Jerry'。下面是实际使用它。使用sqlite3_create_function()函数注册这个句柄:
sqlite3_create_function(db, "hello_newman", 0, hello_newman);
第1个参数(db)是数据库连接。第2个参数是函数的名称,这个名称将出现在SQL中。第3个参数表示这个函数有0个参数(如果该参数值为-1,表示该函数接受可变数量的参数)。最后一个参数是C函数hello_newman()的指针,当SQL函数被调用时,通过这个指针来调用实际的函数。
一旦进行了注册,SQLite就知道了当遇到SQL函数调用hello_newman()时,它需要调用C函数hello_newman()来得到结果。现在,你可以在程序中执行SELECT hello_newman()语句,它将返回单行单列的文本'Hello Jerry'。
如前所述,很多语言扩展允许用各自的语言来实现用户自定义的函数。例如,Java、Perl等。不同的语言扩展用不同的方法注册函数,有些使用其本身语言的函数来完成此项工作,例如,在Ruby中使用block—one。
创建用户自定义聚合
所谓聚合函数,就是那些在结果集中应用于全部记录,并从中计算一些聚合值的函数。SUM()、COUNT()和AVG()都是SQLite标准聚合函数的例子。
创建用户自定义聚合需要三步:注册聚合、实现步进函数(对结果集中的每条记录调用)、实现定案函数(在所有记录处理完后调用)。在定案函数中计算最终的聚合值,并做一些必要的清理工作。
创建用户自定义排序法
事务
现在,你应该已经对API有了一个较好的了解。你知道了执行SQL命令的不同方法和一些有用的功能函数。但是,只知道API还不够,事务和锁与查询的处理过程是紧密关联的。查询永远只能在事务中完成,事务包含锁,而如果不清楚自己到底在做什么,锁则可能会导致问题。根据你是如何使用SQL及如何编码,你可以控制锁的类型和持续时间。
第4章图示了一个特殊的假想:两个独立的连接同时执行时导致了死锁。作为程序员,你还可以从代码的角度来看待问题,代码中可能包括处于多种状态的多个连接,带有多个语句句柄,而你的代码可能在你不知情的情况下就持有了EXCLUSIVE锁,从而使其它连接不能做任何事情。
这就是为什么掌握下面知识很重要:事务和锁如何工作,它们如何与API结合来处理查询。理想的目标是,你应该能够看着你写的代码并说出事务处于什么状态,或者至少能够发现潜在的问题。本节将介绍事务和锁背后的运行机制,下一节将介绍如何实际地编码。
事务的生命周期
有一些关于代码和事务的问题需要关注。首先需要知道哪个对象运行在哪个事务之下。另一个问题是持续时间——一个事务何时开始,何时结束,从哪一点开始影响其它连接?第一个问题与API直接关联,第二个与SQL的一般概念及SQLite的特殊实现关联。
一个连接(connection)可以包含多个语句(statement),而且每个连接有一个与数据库关联的B-tree和一个pager。Pager在连接中起着很重要的作用,因为它管理事务、锁、内存缓冲以及负责崩溃恢复(crash recovery)。当你进行数据库写操作时,记住最重要的一件事:在任何时候,只在一个事务下执行一个连接。这回答了第一个问题。
关于第二个问题,一般来说,一个事务的生命周期和语句差不多,你也可以手动结束它。默认情况下,事务自动提交,当然你也可以通过BEGIN..COMMIT手动提交。接下来的问题是事务如何与锁关联。
锁的状态
大多数情况下,锁的生命周期在事务的生命周期之中。它们不一定同时开始,但总时同时结束。当你结束一个事务时,也会释放它相关的锁。或者说,锁直到事务结束或系统崩溃时才会释放。如果系统在事务没有结束的情况下崩溃,那么下一个访问数据库的连接会处理这种情况,详见“锁与崩溃恢复”一节。
在SQLite中有5种不同的锁状态,连接(connection)任何时候都处于其中的一个状态。图5-3显示了锁的状态以及状态的转换。
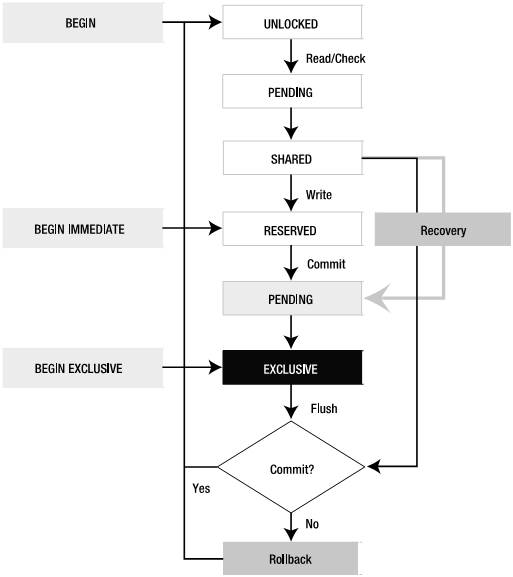
图5-3 SQLite锁转换
关于这个图有以下几点值得注意:
(1)一个事务可以在UNLOCKED、RESERVED或EXCLUSIVE三种状态下开始。默认情况下在UNLOCKED时开始。
(2)白色框中的UNLOCKED、PENDING、SHARED和 RESERVED可以在一个数据库的同一时刻存在。
(3)从灰色的PENDING开始,事情就变得严格起来,意味着事务想得到排它锁(EXCLUSIVE)(注意与白色框中的区别)。
虽然锁有这么多状态,但是从体质上来说,只有两种情况:读事务和写事务。
读事务
我们先来看看SELECT语句执行时锁的状态变化过程,非常简单:一个连接执行SELECT语句,触发一个事务,从UNLOCKED到SHARED,当事务COMMIT时,又回到UNLOCKED,就这么简单。
那么,当你运行两个语句时会发生什么呢?这时如何加锁呢?这依赖于你是否运行在自动提交状态。考虑下面的例子(为了简单,这里用了伪码):
db = open('foods.db')
db.exec('BEGIN')
db.exec('SELECT * FROM episodes')
db.exec('SELECT * FROM episodes')
db.exec('COMMIT')
db.close()
由于显式地使用了BEGIN和COMMIT,两个SELECT命令在一个事务下执行。第一个exec()执行时,连接处于SHARED,然后第二个exec()执行。当事务提交时,连接又从SHARED回到UNLOCKED状态,状态变化如下:
UNLOCKED→PENDING→SHARED→UNLOCKED
如果没有BEGIN和COMMIT两行,两个SELECT都运行于自动提交状态,状态变化如下:
UNLOCKED→PENDING→SHARED→UNLOCKED→PENDING→SHARED→UNLOCKED
仅仅是读数据,但在自动提交模式下,却会经历两个加解锁的循环,太麻烦。而且,一个写进程可能插到两个SELECT中间对数据库进行修改,这样,你就不能保证第二次能够读到同样的数据了,而使用BEGIN..COMMIT就可以有此保证。
写事务
下面我们来考虑写数据库,比如UPDATE。和读事务一样,它也会经历UNLOCKED→PENDING→SHARED的变化过程,但接下来就会看到PENDING锁是如何起到关口作用的了。
保留(RESERVED)状态
当一个连接(connection)要向数据库写数据时,从SHARED状态变为RESERVED状态。如果它得到RESERVED锁,也就意味着它已经准备好进行写操作了。即使它没有把修改写入数据库,也可以把修改保存到位于pager的缓冲区中(page cache)了。
当一个连接进入RESERVED状态,pager就开始初始化回卷日志(rollback journal)。回卷日志是一个文件,用于回卷和崩溃恢复,见图5-1。在RESERVED状态下,pager管理着三种页:
(1)已修改的页:包含被B-tree修改的记录,位于page cache中。
(2)未修改的页:包含没有被B-tree修改的记录。
(3)日志页:这是修改页以前的版本,日志页并不存储在page cache中,而是在B-tree修改页之前写入日志。
Page cache非常重要,正是因为它的存在,一个处于RESERVED状态的连接可以真正的开始工作,而不会干扰其它的(读)连接。所以,SQLite可以高效地处理在同一时刻的多个读连接和一个写连接。
未决(PENDING)状态
当一个连接完成修改,需要真正开始提交事务时,执行该过程的pager进入EXCLUSIVE状态。从RESERVED状态开始,pager试着获取PENDING锁,一旦得到,就独占它,不允许任何其它连接获得PENDING锁。既然写操作持有PENDING锁,其它任何连接都不能从UNLOCKED状态进入SHARED状态,即不会再有新的读进程,也不会再有新的写进程。只有那些已经处于SHARED状态的连接可以继续工作。而处于PENDING状态的写进程会一直等到所有这些连接释放它们的锁,然后对数据库加EXCUSIVE锁,进入EXCLUSIVE状态,独占数据库。
排它状态
在EXCLUSIVE状态下,主要的工作是把修改的页从page cache写入数据库文件,这是真正进行写操作的地方。
在pager将修改页写到文件之前,还必须先处理日志。它检查是否所有的日志都写入了磁盘,因为它们可能还位于操作系统的缓冲区中。所以pager得告诉OS把所有的文件写入磁盘,这与synchronous pragma所做的工作相同,如第4章所述。
日志是数据库进行恢复的惟一方法,所以日志对于DBMS非常重要。如果日志页没有完全写入磁盘而发生崩溃,数据库就不能恢复到它原来的状态,此时数据库就处于不一致状态。日志写盘完成后,pager就把所有的修改页写入数据库文件。接下来做什么取决于事务提交的模式,如果是自动提交,那么pager清理日志、page cache,然后由EXCLUSIVE进入UNLOCKED。如果是手动提交,那么pager继续持有EXCLUSIVE锁和回卷日志,直至遇到COMMIT或者ROLLBACK。
总之,出于性能方面的考虑,进程占有排它锁的时间应该尽可能的短,所以DBMS通常都是在真正写文件时才会占有排它锁,这样能大大提高并发性能。
自动提交与效率
调整页缓冲区
回到前面的例子,事务从BEGIN开始,跟着UPDATE。如果在写盘之前,修改操作将缓冲区用完了(也就是说修改操作需要比预设的更多的缓冲区),这时会发生什么呢?
转换为排它
真正的问题是:到底在哪个(精确的)时刻,到底为什么,pager 从RESERVED转换为EXCLUSIVE。这会发生在两种情况下:当连接到达提交点主动进入排它状态;或页缓冲区已满不得不进入排它状态。
前面我们仅看到了第1种情况,那么,在第2种情况下会发生什么呢?此时pager已不能再存储更多的已修改页,也就不能再做任何修改操作。它必须转换为排它状态,以使工作能够继续进行。实际上也不完全是这样,实际上有软限制和硬限制的区别。
调整页缓冲区的大小
如何决定需要多大的缓冲区尺寸呢?这由你想做什么而定。假设你想修改episodes表的所有记录,那么该表的所有页都会被修改,因此,你就可以计算出episodes表总共需要多少个页并对缓冲区做出调整。可以用sqlite_analyzer到得所有关于episodes表的需要的信息。对每一个表,它都可以做出完备的统计,包括总页数。例如,对于foods数据库,可以得到关于episodes表的如下信息:
*** Table EPISODES ***************************************************
Percentage of total database.......... 20.0%
Number of entries..................... 181
Bytes of storage consumed............. 5120
Bytes of payload...................... 3229 63.1%
Average payload per entry............. 17.84
Average unused bytes per entry........ 5.79
Average fanout........................ 4.00
Maximum payload per entry............. 38
Entries that use overflow............. 0 0.0%
Index pages used...................... 1
Primary pages used.................... 4
Overflow pages used................... 0
Total pages used...................... 5
Unused bytes on index pages........... 990 96.7%
Unused bytes on primary pages......... 58 1.4%
Unused bytes on overflow pages........ 0
Unused bytes on all pages............. 1048 20.5%
总页数是5,但实际上表只用了4页,还有1页是索引。因为默认的缓冲区大小是2000个页,所以你没有必要担心。在episodes表中有400条记录,也就是说每页可存放约100条记录。所以,在修改所有记录之前你不需要考虑调整页缓冲区,除非episodes中至少有了196000条记录。还要记住,你只需要在有其它连接并发使用数据库的情况下才需要考虑这些,如果只有你自己使用数据库,这些就都不需要考虑了。
等待加锁
我们前面谈到过pager等待从PENDING状态进入EXCLUSIVE状态,那么在这个期间到底发生了什么呢?首先,任何exec()或step()的调用都可能进入等待。当SQLite遇到不能获得锁的情况时,它的默认表现总是向函数返回一个SQLITE_BUSY并使函数继续寻求锁。无论你执行什么命令,都有可能遇到SQLITE_BUSY,包括SELECT命令,都有可能因为有其它的写进程处于未决状态而遇到SQLITE_BUSY。当遇到SQLITE_BUSY时,最简单的选择是重试。但是,下面我们就会看到这并不一定是最好的选择。
使用“忙”句柄
你可以使用一个忙句柄,而不是一遍遍地重试。忙句柄是一个函数,你创建它用来消磨时间或做其它任何事情——如给岳母发一封邮件(?)。它仅在SQLite不能获得锁时被调用。忙句柄必须做的唯一的事是返回一个值,告诉SQLite下一步该做什么。如果它返回TRUE,SQLite将会继续尝试获得锁;如果它返回FALSE,SQLite将向申请锁的函数返回SQLITE_BUSY。看下面的例子:
counter = 1
def busy()
counter = counter + 1
if counter == 2
return 0
end
spam_mother_in_law(100)
return 1
end
db.busy_handler(busy)
stmt = db.prepare('SELECT * FROM episodes;')
stmt.step()
stmt.finalize()
spam_mother_in_law()完成一个发邮件功能。
step()函数必须获得一个SHARED锁以完成SELECT操作。如果此时有一个写进程活动,正常情况下step()会返回SQLITE_BUSY。但是,在上面程序中却不是这样,而是由pager调用busy()函数,因为它已经被注册队忙句柄。busy()函数增加计数,给你岳母发一封邮件,并且返回1,在pager中会被翻译成true——继续申请锁。Pager再次申请获得SHARED锁,但数据库仍然被锁着,于是pager再次调用busy()函数。只有此时,busy()函数返回0,在pager中会被翻译成false——返回SQLITE_BUSY。
使用正确的事务
编码
现在,你对API、事务和锁已经有了很好的了解了。最后,我们把这3个内容在代码中结合到一起。
使用多个连接
如果你曾经为其它的关系型数据库编写过程序,你就会发现有些适用于那些数据库的方法不一定适用于SQLite。使用其它数据库时,经常会在同一个代码块中打开多个连接,典型的例子就是在一个连接中返复遍历一个表而在另一个连接中修改它的记录。
在SQLite中,在同一个代码块中使用多个连接会引起问题,必须小心地对待这种情况。请看下面代码:
c1 = open('foods.db')
c2 = open('foods.db')
stmt = c1.prepare('SELECT * FROM episodes')
while stmt.step()
print stmt.column('name')
c2.exec('UPDATE episodes SET …)
end
stmt.finalize()
c1.close()
c2.close()
问题很明显,当c2试图执行UPDATE时,c1拥有一个SHARED锁,这个锁只有等stmt.finalize()之后才会释放。所以,是不可能成功写数据库的。最好的办法是在一个连接中完成工作,并且在同一个BEGIN IMMEDIATE事务中完成。新程序如下:
c1 = open('foods.db')
# Keep trying until we get it
while c1.exec('BEGIN IMMEDIATE') != SQLITE_OK
end
stmt = c1.prepare('SELECT * FROM episodes')
while stmt.step()
print stmt.column('name')
c1.exec('UPDATE episodes SET …)
end
stmt.finalize()
c1.exec('COMMIT')
c1.close()
在这种情况下,你应该在单独的连接中使用语句(statement)来完成读和写,这样,你就不必担心数据库锁会引发问题了。但是,这个特别的示例仍然不能工作。如果你在一个语句(statement)中返复遍历一个表而在另一个语句中修改它的记录,还有一个附加的锁问题你需要了解,我们将在下面介绍。
表锁
即使只使用一个连接,在有些边界情况下也会出现问题。不要认为一个连接中的两个语句(statements)就能协调工作,至少有一个重要的例外。
当在一个表上执行了SELECT命令,语句对象会在表上创建一个B-tree游标。如果表上有一个活动的B-tree游标,即使是本连接中的其它语句也不能够再修改这个表。如果做这种尝试,将会得到SQLITE_BUSY。看下面的例子:
c = sqlite.open("foods.db")
stmt1 = c.compile('SELECT * FROM episodes LIMIT 10')
while stmt1.step() do
# Try to update the row
row = stm1.row()
stmt2 = c.compile('UPDATE episodes SET …')
# Uh oh: ain't gonna happen
stmt2.step()
end
stmt1.finalize()
stmt2.finalize ()
c.close()
这里我们只使用了一个连接。但当调用stmt2.step()则不会工作,因为stmt1拥有episodes表的一个游标。在这种情况下,stmt2.step()有可能成功地将锁升级到EXCLUSIVE,但仍会返回SQLITE_BUSY,因为episodes的游标会阻止它修改表。完成这种操作有两种方法:
遍历一个语句的结果集,在内存中保存需要的信息。定案这个读语句,然后执行修改操作。
将SELECT的结果存到一个临时表中并用读游标打开它。这时同时有一个读语句和一个写语句,但它们在不同的表上,所以不会影响主表上的写操作。写完成后,删掉临时表就是了。
当表上打开了一个语句,它的B-tree游标在两种情况下会被移除:
到达了语句结果集的尾部。这时step()会自动地关闭语句的游标。从VDBE的角度,当到达结果集的尾部时,CDBE遇到Close命令,这将导致所有相关游标的关闭。
程序显式地调用了finalize(),所有相关游标将关闭。
在很多编程语言扩展中,statement对象的close()函数会自动调用sqlite3_finalize()。
有趣的临时表
临时表使你可以做到不违反规则。如果你确实需要在一个代码块中使用两个连接,或者使用两个语句(statement)操作同一个表,你可以安全地在临时表上如此做。当一个连接创建了一个临时表,不需要得到RESERVED锁,因为临时表存在于数据库文件之外。有两种方法可以做到这一点,看你想如何管理并发。请看如下代码:
c1 = open('foods.db')
c2 = open('foods.db')
c2.exec('CREATE TEMPORARY TABLE temp_epsidodes as SELECT * from episodes')
stmt = c1.prepare('SELECT * FROM episodes')
while stmt.step()
print stmt.column('name')
c2.exec('UPDATE temp_episodes SET …')
end
stmt.finalize()
c2.exec('BEGIN IMMEDIATE')
c2.exec('DELETE FROM episodes')
c2.exec('INSERT INTO episodes SELECT * FROM temp_episodes')
c2.exec('COMMIT')
c1.close()
c2.close()
上面的例子可以完成功能,但不好。episodes表中的数据要全部删除并重建,这将丢失episodes表中的所有完整性约束和索引。下面的方法比较好:
c1 = open('foods.db')
c2 = open('foods.db')
c1.exec('CREATE TEMPORARY TABLE temp_episodes as SELECT * from episodes')
stmt = c1.prepare('SELECT * FROM temp_episodes')
while stmt.step()
print stmt.column('name')
c2.exec('UPDATE episodes SET …') # What about SQLITE_BUSY?
end
stmt.finalize()
c1.exec('DROP TABLE temp_episodes')
c1.close()
c2.close()
定案的重要性
使用SELECT语句必须要意识到,其SHARED锁(大多数时候)直到finalize()被调用后才会释放,请看下面代码:
stmt = c1.prepare('SELECT * FROM episodes')
while stmt.step()
print stmt.column('name')
end
c2.exec('BEGIN IMMEDIATE; UPDATE episodes SET …; COMMIT;')
stmt.finalize()
如果你用C API写了与上例等价的程序,它实际上是能够工作的。尽管没有调用finalize(),但第二个连接仍然能够修改数据库。在告诉你为什么之前,先来看第二个例子:
c1 = open('foods.db')
c2 = open('foods.db')
stmt = c1.prepare('SELECT * FROM episodes')
stmt.step()
stmt.step()
stmt.step()
c2.exec('BEGIN IMMEDIATE; UPDATE episodes SET …; COMMIT;')
stmt.finalize()
假设episodes中有100条记录,程序仅仅访问了其中的3条,这时会发生什么情况呢?第2个连接会得到SQLITE_BUSY。
在第1个例子中,当到达语句结果集尾部时,会释放SHARED锁,尽管还没有调用finalize()。在第2个例子中,没有到达语句结果集尾部,SHARED锁没有释放。所以,c2不能执行UPDATE操作。
这个故事的中心思想是:不要这么做,尽管有时这么做是可以的。在用另一个连接进行写操作之前,永远要先调用finalize()。
共享缓冲区模式
现在你对并发规则已经很清楚了,但我还要找些事来扰乱你。SQLite提供一种可选的并发模式,称为共享缓冲区模式,它允许在单一的线程中操作多个连接。
在共享缓冲区模式中,一个线程可以创建多个连接来共享相同的页缓冲区。进而,这组连接可以有多个“读”和一个“写”同时工作于相同的数据库。缓冲区不能在线程间共享,它被严格地限制在创建它的线程中。因此,“读”和“写”就需要准备处理与表锁有关的一些特殊情况。
当 readers读表时, SQLite自动在这些表上加锁,writer就不能再改这些表了。如果writer试图修改一个有读锁的表,会得到SQLITE_LOCKED。如果readers运行在read-uncommitted模式(通过read_uncommitted pragma来设置),则当readers读表时,writer也可以写表。在这种情况下,SQLite不为readers所读的表加读锁,结果就是readers和writer互不干扰。也因此,当一个writer修改表时,这些readers可能得到不一致的结果。