数据挖掘十大算法--K近邻算法
k-近邻算法是基于实例的学习方法中最基本的,先介绍基于实例学习的相关概念。
一、基于实例的学习。
1、已知一系列的训练样例,很多学习方法为目标函数建立起明确的一般化描述;但与此不同,基于实例的学习方法只是简单地把训练样例存储起来。
从这些实例中泛化的工作被推迟到必须分类新的实例时。每当学习器遇到一个新的查询实例,它分析这个新实例与以前存储的实例的关系,并据此把一个目标函数值赋给新实例。
2、基于实例的方法可以为不同的待分类查询实例建立不同的目标函数逼近。事实上,很多技术只建立目标函数的局部逼近,将其应用于与新查询实例邻近的实例,而从不建立在整个实例空间上都表现良好的逼近。当目标函数很复杂,但它可用不太复杂的局部逼近描述时,这样做有显著的优势。
3、基于实例方法的不足:
(1)分类新实例的开销可能很大。这是因为几乎所有的计算都发生在分类时,而不是在第一次遇到训练样例时。所以,如何有效地索引训练样例,以减少查询时所需计算是一个重要的实践问题。
(2)当从存储器中检索相似的训练样例时,它们一般考虑实例的所有属性。如果目标概念仅依赖于很多属性中的几个时,那么真正最“相似”的实例之间很可能相距甚远。
二、k-近邻法
基于实例的学习方法中最基本的是k-近邻算法。这个算法假定所有的实例对应于n维欧氏空间Ân中的点。一个实例的最近邻是根据标准欧氏距离定义的。更精确地讲,把任意的实例x表示为下面的特征向量:
a1(x),a2(x),...,an(x)
其中ar(x)表示实例x的第r个属性值。那么两个实例xi和xj间的距离定义为d(xi,xj),其中:
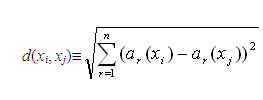
说明:
1、在最近邻学习中,目标函数值可以为离散值也可以为实值。
2、我们先考虑学习以下形式的离散目标函数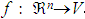 。其中V是有限集合{v1,...vs}。下表给出了逼近离散目标函数的k-近邻算法。
。其中V是有限集合{v1,...vs}。下表给出了逼近离散目标函数的k-近邻算法。
3、正如下表中所指出的,这个算法的返回值f'(xq)为对f(xq)的估计,它就是距离xq最近的k个训练样例中最普遍的f值。
4、如果我们选择k=1,那么“1-近邻算法”就把f(xi)赋给(xq),其中xi是最靠近xq的训练实例。对于较大的k值,这个算法返回前k个最靠近的训练实例中最普遍的f值。
逼近离散值函数f: Ân</sup>V的_k-近邻算法
训练算法:
对于每个训练样例<_x_,_f_(_x_)>,把这个样例加入列表training___examples
分类算法:
给定一个要分类的查询实例xq
在training___examples中选出最靠近xq的k个实例,并用x1....xk表示
返回
其中如果a=b那么d(a,b)=1,否则d(a,b)=0。
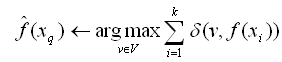
下图图解了一种简单情况下的k-近邻算法,在这里实例是二维空间中的点,目标函数具有布尔值。正反训练样例用“+”和“-”分别表示。图中也画出了一个查询点xq。注意在这幅图中,1-近邻算法把xq分类为正例,然而5-近邻算法把xq分类为反例。

图解说明:左图画出了一系列的正反训练样例和一个要分类的查询实例xq。1-近邻算法把xq分类为正例,然而5-近邻算法把xq分类为反例。
右图是对于一个典型的训练样例集合1-近邻算法导致的决策面。围绕每个训练样例的凸多边形表示最靠近这个点的实例空间(即这个空间中的实例会被1-近邻算法赋予该训练样例所属的分类)。
对前面的k-近邻算法作简单的修改后,它就可被用于逼近连续值的目标函数。为了实现这一点,我们让算法计算k个最接近样例的平均值,而不是计算其中的最普遍的值。更精确地讲,为了逼近一个实值目标函数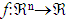 ,我们只要把算法中的公式替换为:
,我们只要把算法中的公式替换为:
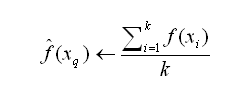
三、距离加权最近邻算法
对k-近邻算法的一个显而易见的改进是对k个近邻的贡献加权,根据它们相对查询点xq的距离,将较大的权值赋给较近的近邻。
例如,在上表逼近离散目标函数的算法中,我们可以根据每个近邻与xq的距离平方的倒数加权这个近邻的“选举权”。
方法是通过用下式取代上表算法中的公式来实现:
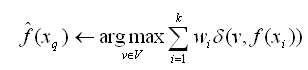
其中
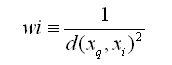
为了处理查询点xq恰好匹配某个训练样例xi,从而导致分母为0的情况,我们令这种情况下的f '(xq)等于f(xi)。如果有多个这样的训练样例,我们使用它们中占多数的分类。
我们也可以用类似的方式对实值目标函数进行距离加权,只要用下式替换上表的公式:

其中wi的定义与之前公式中相同。
注意这个公式中的分母是一个常量,它将不同权值的贡献归一化(例如,它保证如果对所有的训练样例xi,f(xi)=c,那么(xq)<--c)。
注意以上k-近邻算法的所有变体都只考虑k个近邻以分类查询点。如果使用按距离加权,那么允许所有的训练样例影响xq的分类事实上没有坏处,因为非常远的实例对(xq)的影响很小。考虑所有样例的惟一不足是会使分类运行得更慢。如果分类一个新的查询实例时考虑所有的训练样例,我们称此为全局(global)法。如果仅考虑最靠近的训练样例,我们称此为局部(local)法。
四、对k-近邻算法的说明
按距离加权的k-近邻算法是一种非常有效的归纳推理方法。它对训练数据中的噪声有很好的鲁棒性,而且当给定足够大的训练集合时它也非常有效。注意通过取k个近邻的加权平均,可以消除孤立的噪声样例的影响。
1、问题一:近邻间的距离会被大量的不相关属性所支配。
应用k-近邻算法的一个实践问题是,实例间的距离是根据实例的所有属性(也就是包含实例的欧氏空间的所有坐标轴)计算的。这与那些只选择全部实例属性的一个子集的方法不同,例如决策树学习系统。
比如这样一个问题:每个实例由20个属性描述,但在这些属性中仅有2个与它的分类是有关。在这种情况下,这两个相关属性的值一致的实例可能在这个20维的实例空间中相距很远。结果,依赖这20个属性的相似性度量会误导k-近邻算法的分类。近邻间的距离会被大量的不相关属性所支配。这种由于存在很多不相关属性所导致的难题,有时被称为维度灾难(curse of dimensionality)。最近邻方法对这个问题特别敏感。
2、解决方法:当计算两个实例间的距离时对每个属性加权。
这相当于按比例缩放欧氏空间中的坐标轴,缩短对应于不太相关属性的坐标轴,拉长对应于更相关的属性的坐标轴。每个坐标轴应伸展的数量可以通过交叉验证的方法自动决定。
3、问题二:应用k-近邻算法的另外一个实践问题是如何建立高效的索引。因为这个算法推迟所有的处理,直到接收到一个新的查询,所以处理每个新查询可能需要大量的计算。
4、解决方法:目前已经开发了很多方法用来对存储的训练样例进行索引,以便在增加一定存储开销情况下更高效地确定最近邻。一种索引方法是kd-tree(Bentley 1975;Friedman et al. 1977),它把实例存储在树的叶结点内,邻近的实例存储在同一个或附近的结点内。通过测试新查询xq的选定属性,树的内部结点把查询xq排列到相关的叶结点。
机器学习与数据挖掘-K最近邻(KNN)算法的实现(java和python版)
KNN算法基础思想前面文章可以参考,这里主要讲解java和python的两种简单实现,也主要是理解简单的思想。
python版本:
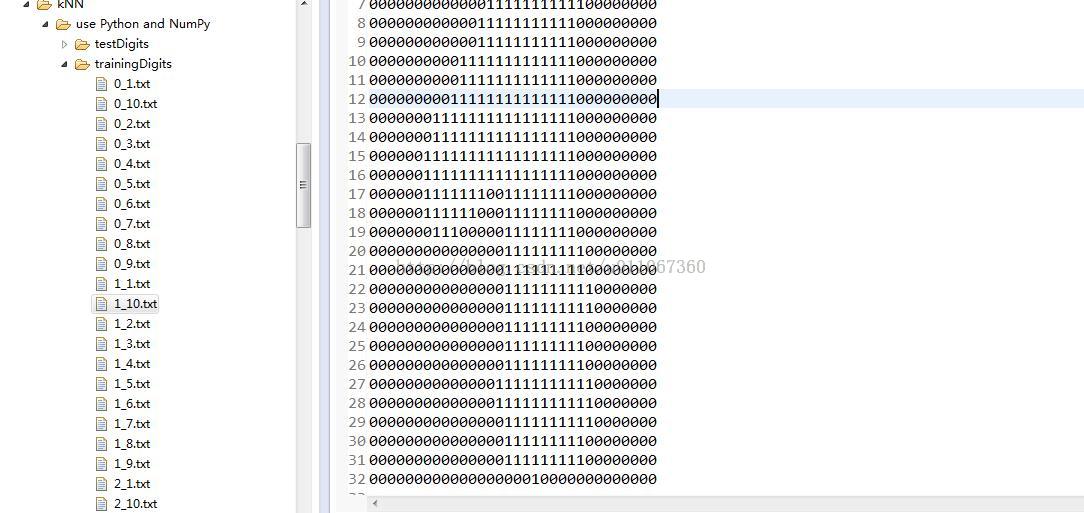
这里实现一个手写识别算法,这里只简单识别0~9熟悉,在上篇文章中也展示了手写识别的应用,可以参考:机器学习与数据挖掘-logistic回归及手写识别实例的实现
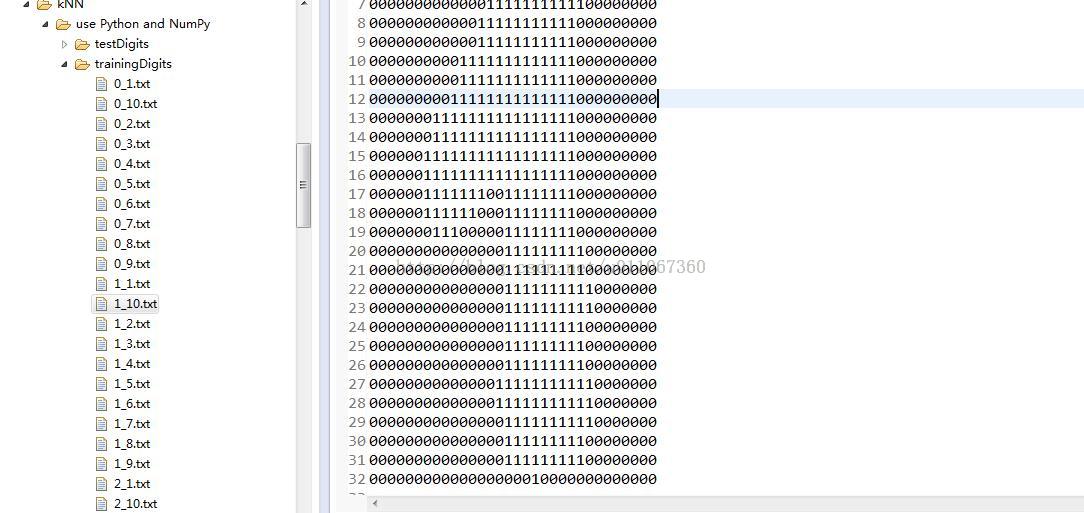
输入:每个手写数字已经事先处理成32*32的二进制文本,存储为txt文件。0~9每个数字都有10个训练样本,5个测试样本。训练样本集如下图:左边是文件目录,右边是其中一个文件打开显示的结果,看着像1,这里有0~9,每个数字都有是个样本来作为训练集。
第一步:将每个txt文本转化为一个向量,即3232的数组转化为11024的数组,这个1*1024的数组用机器学习的术语来说就是特征向量。
def img2vector(filename):
returnVect = zeros((1,1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[0,32*i+j] = int(lineStr[j])
return returnVect
第二步:训练样本中有1010个图片,可以合并成一个1001024的矩阵,每一行对应一个图片,也就是一个txt文档。
def handwritingClassTest():
hwLabels = []
trainingFileList = listdir('trainingDigits')
print trainingFileList
m = len(trainingFileList)
trainingMat = zeros((m,1024))
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
hwLabels.append(classNumStr)
#print hwLabels
#print fileNameStr
trainingMat[i,:] = img2vector('trainingDigits/%s' % fileNameStr)
#print trainingMat[i,:]
#print len(trainingMat[i,:])
testFileList = listdir('testDigits')
errorCount = 0.0
mTest = len(testFileList)
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
vectorUnderTest = img2vector('testDigits/%s' % fileNameStr)
classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3)
print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, classNumStr)
if (classifierResult != classNumStr): errorCount += 1.0
print "\nthe total number of errors is: %d" % errorCount
print "\nthe total error rate is: %f" % (errorCount/float(mTest))
第三步:测试样本中有105个图片,同样的,对于测试图片,将其转化为11024的向量,然后计算它与训练样本中各个图片的“距离”(这里两个向量的距离采用欧式距离),然后对距离排序,选出较小的前k个,因为这k个样本来自训练集,是已知其代表的数字的,所以被测试图片所代表的数字就可以确定为这k个中出现次数最多的那个数字。
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
#tile(A,(m,n))
print dataSet
print "----------------"
print tile(inX, (dataSetSize,1))
print "----------------"
diffMat = tile(inX, (dataSetSize,1)) - dataSet
print diffMat
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort()
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
全部实现代码:
#-*-coding:utf-8-*-
from numpy import *
import operator
from os import listdir
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
#tile(A,(m,n))
print dataSet
print "----------------"
print tile(inX, (dataSetSize,1))
print "----------------"
diffMat = tile(inX, (dataSetSize,1)) - dataSet
print diffMat
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort()
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
def img2vector(filename):
returnVect = zeros((1,1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[0,32*i+j] = int(lineStr[j])
return returnVect
def handwritingClassTest():
hwLabels = []
trainingFileList = listdir('trainingDigits')
print trainingFileList
m = len(trainingFileList)
trainingMat = zeros((m,1024))
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
hwLabels.append(classNumStr)
#print hwLabels
#print fileNameStr
trainingMat[i,:] = img2vector('trainingDigits/%s' % fileNameStr)
#print trainingMat[i,:]
#print len(trainingMat[i,:])
testFileList = listdir('testDigits')
errorCount = 0.0
mTest = len(testFileList)
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
vectorUnderTest = img2vector('testDigits/%s' % fileNameStr)
classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3)
print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, classNumStr)
if (classifierResult != classNumStr): errorCount += 1.0
print "\nthe total number of errors is: %d" % errorCount
print "\nthe total error rate is: %f" % (errorCount/float(mTest))
handwritingClassTest()
运行结果:源码文章尾可下载
java版本
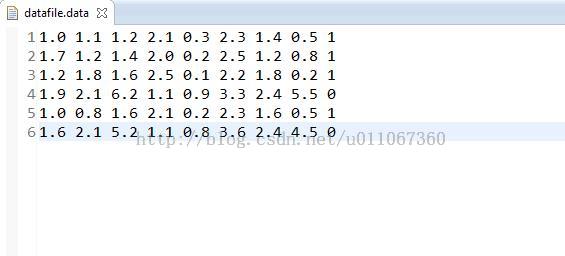
先看看训练集和测试集:
训练集:
测试集:
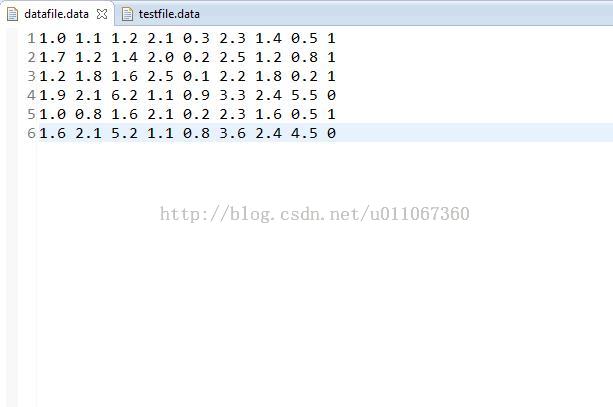
训练集最后一列代表分类(0或者1)
代码实现:
KNN算法主体类:
package Marchinglearning.knn2;
import java.util.ArrayList;
import java.util.Comparator;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.PriorityQueue;
/**
* KNN算法主体类
*/
public class KNN {
/**
* 设置优先级队列的比较函数,距离越大,优先级越高
*/
private Comparator<KNNNode> comparator = new Comparator<KNNNode>() {
public int compare(KNNNode o1, KNNNode o2) {
if (o1.getDistance() >= o2.getDistance()) {
return 1;
} else {
return 0;
}
}
};
/**
* 获取K个不同的随机数
* @param k 随机数的个数
* @param max 随机数最大的范围
* @return 生成的随机数数组
*/
public List<Integer> getRandKNum(int k, int max) {
List<Integer> rand = new ArrayList<Integer>(k);
for (int i = 0; i < k; i++) {
int temp = (int) (Math.random() * max);
if (!rand.contains(temp)) {
rand.add(temp);
} else {
i--;
}
}
return rand;
}
/**
* 计算测试元组与训练元组之前的距离
* @param d1 测试元组
* @param d2 训练元组
* @return 距离值
*/
public double calDistance(List<Double> d1, List<Double> d2) {
System.out.println("d1:"+d1+",d2"+d2);
double distance = 0.00;
for (int i = 0; i < d1.size(); i++) {
distance += (d1.get(i) - d2.get(i)) * (d1.get(i) - d2.get(i));
}
return distance;
}
/**
* 执行KNN算法,获取测试元组的类别
* @param datas 训练数据集
* @param testData 测试元组
* @param k 设定的K值
* @return 测试元组的类别
*/
public String knn(List<List<Double>> datas, List<Double> testData, int k) {
PriorityQueue<KNNNode> pq = new PriorityQueue<KNNNode>(k, comparator);
List<Integer> randNum = getRandKNum(k, datas.size());
System.out.println("randNum:"+randNum.toString());
for (int i = 0; i < k; i++) {
int index = randNum.get(i);
List<Double> currData = datas.get(index);
String c = currData.get(currData.size() - 1).toString();
System.out.println("currData:"+currData+",c:"+c+",testData"+testData);
//计算测试元组与训练元组之前的距离
KNNNode node = new KNNNode(index, calDistance(testData, currData), c);
pq.add(node);
}
for (int i = 0; i < datas.size(); i++) {
List<Double> t = datas.get(i);
System.out.println("testData:"+testData);
System.out.println("t:"+t);
double distance = calDistance(testData, t);
System.out.println("distance:"+distance);
KNNNode top = pq.peek();
if (top.getDistance() > distance) {
pq.remove();
pq.add(new KNNNode(i, distance, t.get(t.size() - 1).toString()));
}
}
return getMostClass(pq);
}
/**
* 获取所得到的k个最近邻元组的多数类
* @param pq 存储k个最近近邻元组的优先级队列
* @return 多数类的名称
*/
private String getMostClass(PriorityQueue<KNNNode> pq) {
Map<String, Integer> classCount = new HashMap<String, Integer>();
for (int i = 0; i < pq.size(); i++) {
KNNNode node = pq.remove();
String c = node.getC();
if (classCount.containsKey(c)) {
classCount.put(c, classCount.get(c) + 1);
} else {
classCount.put(c, 1);
}
}
int maxIndex = -1;
int maxCount = 0;
Object[] classes = classCount.keySet().toArray();
for (int i = 0; i < classes.length; i++) {
if (classCount.get(classes[i]) > maxCount) {
maxIndex = i;
maxCount = classCount.get(classes[i]);
}
}
return classes[maxIndex].toString();
}
}
KNN结点类,用来存储最近邻的k个元组相关的信息
package Marchinglearning.knn2;
/**
* KNN结点类,用来存储最近邻的k个元组相关的信息
*/
public class KNNNode {
private int index; // 元组标号
private double distance; // 与测试元组的距离
private String c; // 所属类别
public KNNNode(int index, double distance, String c) {
super();
this.index = index;
this.distance = distance;
this.c = c;
}
public int getIndex() {
return index;
}
public void setIndex(int index) {
this.index = index;
}
public double getDistance() {
return distance;
}
public void setDistance(double distance) {
this.distance = distance;
}
public String getC() {
return c;
}
public void setC(String c) {
this.c = c;
}
}
KNN算法测试类
package Marchinglearning.knn2;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.util.ArrayList;
import java.util.List;
/**
* KNN算法测试类
*/
public class TestKNN {
/**
* 从数据文件中读取数据
* @param datas 存储数据的集合对象
* @param path 数据文件的路径
*/
public void read(List<List<Double>> datas, String path){
try {
BufferedReader br = new BufferedReader(new FileReader(new File(path)));
String data = br.readLine();
List<Double> l = null;
while (data != null) {
String t[] = data.split(" ");
l = new ArrayList<Double>();
for (int i = 0; i < t.length; i++) {
l.add(Double.parseDouble(t[i]));
}
datas.add(l);
data = br.readLine();
}
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 程序执行入口
* @param args
*/
public static void main(String[] args) {
TestKNN t = new TestKNN();
String datafile = new File("").getAbsolutePath() + File.separator +"knndata2"+File.separator + "datafile.data";
String testfile = new File("").getAbsolutePath() + File.separator +"knndata2"+File.separator +"testfile.data";
System.out.println("datafile:"+datafile);
System.out.println("testfile:"+testfile);
try {
List<List<Double>> datas = new ArrayList<List<Double>>();
List<List<Double>> testDatas = new ArrayList<List<Double>>();
t.read(datas, datafile);
t.read(testDatas, testfile);
KNN knn = new KNN();
for (int i = 0; i < testDatas.size(); i++) {
List<Double> test = testDatas.get(i);
System.out.print("测试元组: ");
for (int j = 0; j < test.size(); j++) {
System.out.print(test.get(j) + " ");
}
System.out.print("类别为: ");
System.out.println(Math.round(Float.parseFloat((knn.knn(datas, test, 3)))));
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
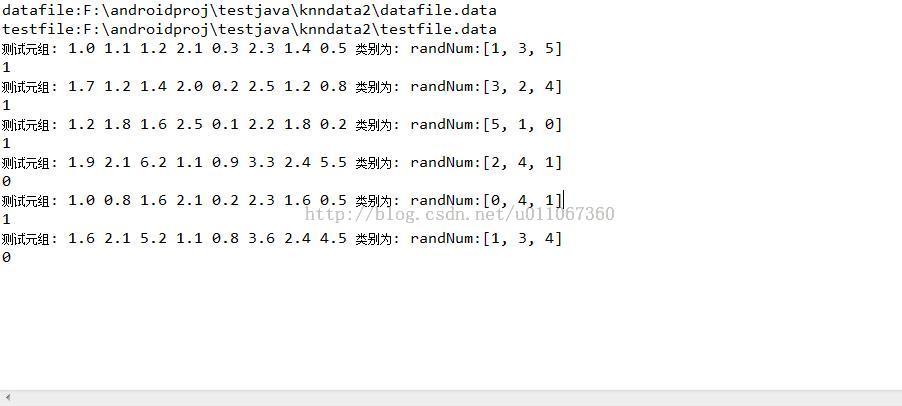
运行结果为:
资源下载: