第08章 数据清理
In[1]: import pandas as pd
import numpy as np
1. 用stack清理变量值作为列名
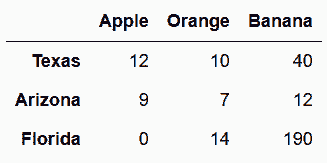
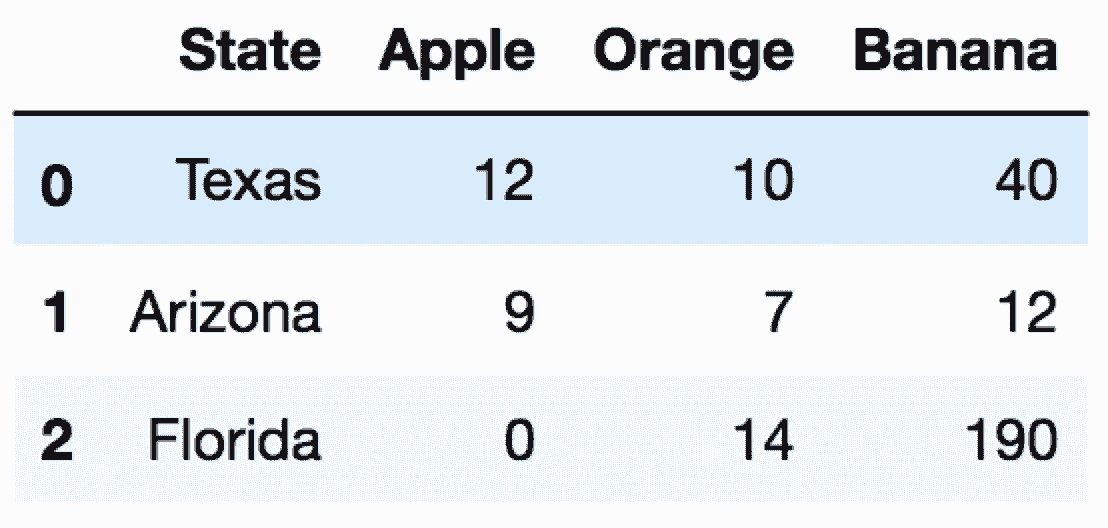
In[2]: state_fruit = pd.read_csv('data/state_fruit.csv', index_col=0)
state_fruit
out[2]:
In[3]: state_fruit.stack()
out[3]: Texas Apple 12
Orange 10
Banana 40
Arizona Apple 9
Orange 7
Banana 12
Florida Apple 0
Orange 14
Banana 190
dtype: int64
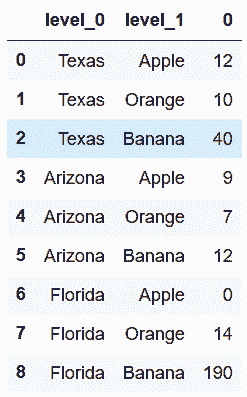
In[4]: state_fruit_tidy = state_fruit.stack().reset_index()
state_fruit_tidy
out[4]:
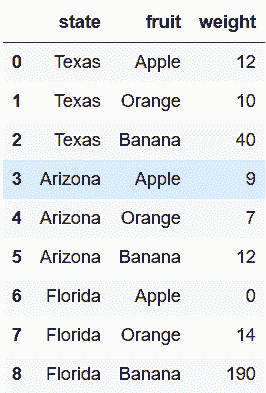
In[5]: state_fruit_tidy.columns = ['state', 'fruit', 'weight']
state_fruit_tidy
out[5]:
In[6]: state_fruit.stack()\
.rename_axis(['state', 'fruit'])\
out[6]: state fruit
Texas Apple 12
Orange 10
Banana 40
Arizona Apple 9
Orange 7
Banana 12
Florida Apple 0
Orange 14
Banana 190
dtype: int64
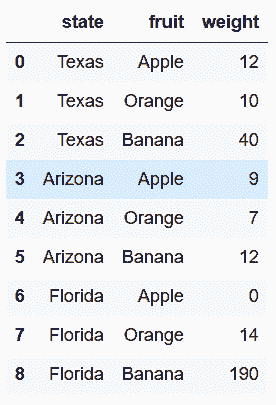
In[7]: state_fruit.stack()\
.rename_axis(['state', 'fruit'])\
.reset_index(name='weight')
out[7]:
更多
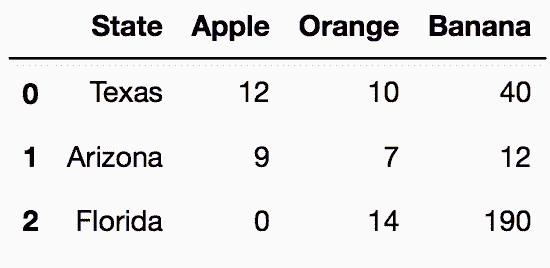
In[8]: state_fruit2 = pd.read_csv('data/state_fruit2.csv')
state_fruit2
out[8]:
In[9]: state_fruit2.stack()
out[9]: 0 State Texas
Apple 12
Orange 10
Banana 40
1 State Arizona
Apple 9
Orange 7
Banana 12
2 State Florida
Apple 0
Orange 14
Banana 190
dtype: object
In[10]: state_fruit2.set_index('State').stack()
out[10]: 0 State Texas
Apple 12
Orange 10
Banana 40
1 State Arizona
Apple 9
Orange 7
Banana 12
2 State Florida
Apple 0
Orange 14
Banana 190
dtype: object
2. 用melt清理变量值作为列名
In[11]: state_fruit2 = pd.read_csv('data/state_fruit2.csv')
state_fruit2
out[11]:
In[12]: state_fruit2.melt(id_vars=['State'],
value_vars=['Apple', 'Orange', 'Banana'])
out[12]:

In[13]: state_fruit2.index=list('abc')
state_fruit2.index.name = 'letter'
In[14]: state_fruit2
out[14]:

In[15]: state_fruit2.melt(id_vars=['State'],
value_vars=['Apple', 'Orange', 'Banana'],
var_name='Fruit',
value_name='Weight')
out[15]:

In[16]: state_fruit2.melt()
out[16]:

In[17]: state_fruit2.melt(id_vars='State')
out[17]:

3. 同时stack多组变量
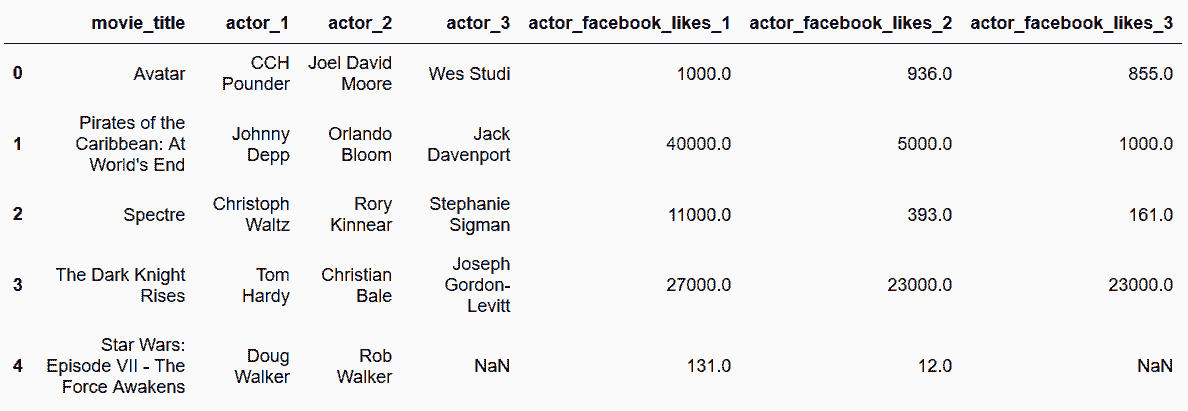
In[18]: movie = pd.read_csv('data/movie.csv')
actor = movie[['movie_title', 'actor_1_name', 'actor_2_name', 'actor_3_name',
'actor_1_facebook_likes', 'actor_2_facebook_likes', 'actor_3_facebook_likes']]
actor.head()
out[18]:

In[19]: def change_col_name(col_name):
col_name = col_name.replace('_name', '')
if 'facebook' in col_name:
fb_idx = col_name.find('facebook')
col_name = col_name[:5] + col_name[fb_idx - 1:] + col_name[5:fb_idx-1]
return col_name
In[20]: actor2 = actor.rename(columns=change_col_name)
actor2.head()
out[20]:
In[21]: stubs = ['actor', 'actor_facebook_likes']
actor2_tidy = pd.wide_to_long(actor2,
stubnames=stubs,
i=['movie_title'],
j='actor_num',
sep='_').reset_index()
actor2_tidy.head()
out[21]:
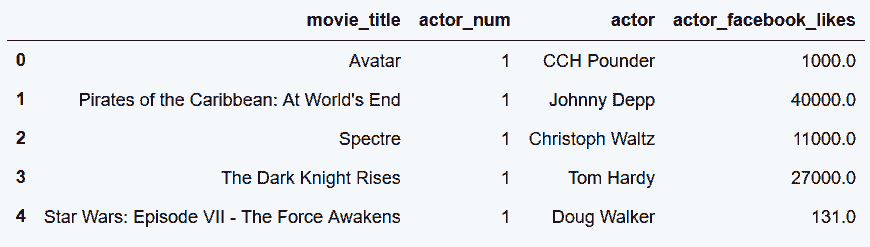
更多
In[22]: df = pd.read_csv('data/stackme.csv')
df
out[22]:
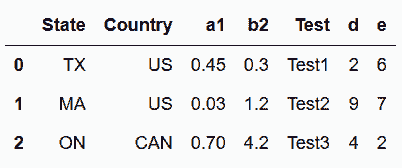
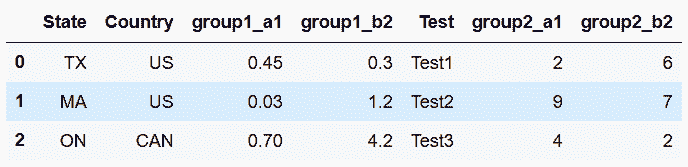
In[23]: df2 = df.rename(columns = {'a1':'group1_a1', 'b2':'group1_b2',
'd':'group2_a1', 'e':'group2_b2'})
df2
out[23]:
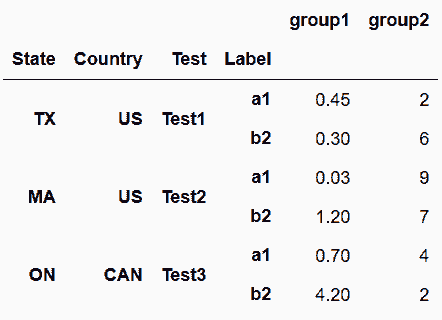
In[24]: pd.wide_to_long(df2,
stubnames=['group1', 'group2'],
i=['State', 'Country', 'Test'],
j='Label',
suffix='.+',
sep='_')
out[24]:
4. 反转stacked数据
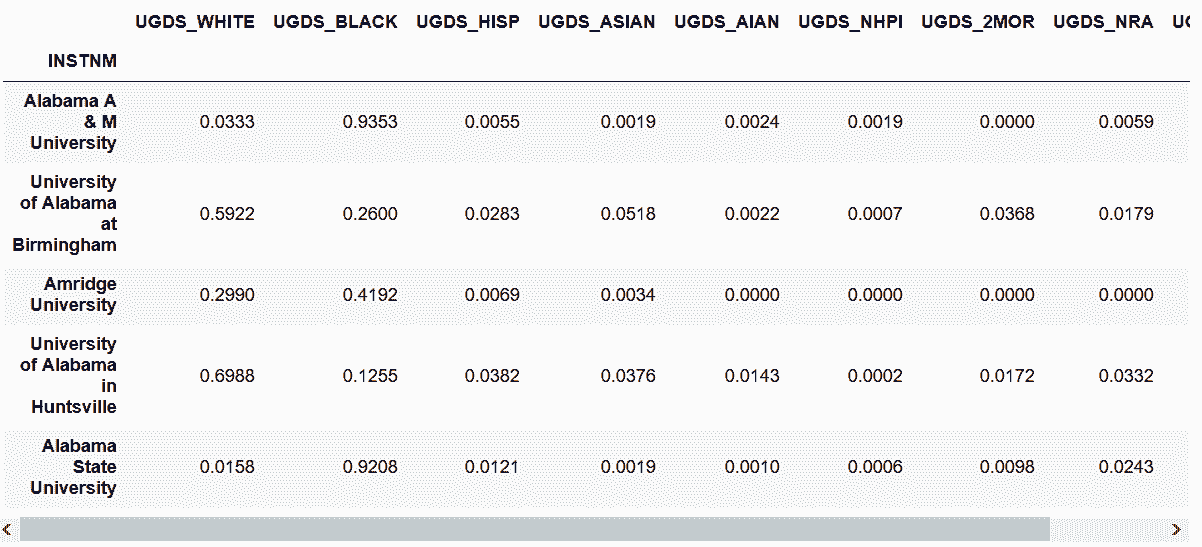
In[25]: usecol_func = lambda x: 'UGDS_' in x or x == 'INSTNM'
college = pd.read_csv('data/college.csv',
index_col='INSTNM',
usecols=usecol_func)
college.head()
out[25]:
In[26]: college_stacked = college.stack()
college_stacked.head(18)
out[26]: INSTNM
Alabama A & M University UGDS_WHITE 0.0333
UGDS_BLACK 0.9353
UGDS_HISP 0.0055
UGDS_ASIAN 0.0019
UGDS_AIAN 0.0024
UGDS_NHPI 0.0019
UGDS_2MOR 0.0000
UGDS_NRA 0.0059
UGDS_UNKN 0.0138
University of Alabama at Birmingham UGDS_WHITE 0.5922
UGDS_BLACK 0.2600
UGDS_HISP 0.0283
UGDS_ASIAN 0.0518
UGDS_AIAN 0.0022
UGDS_NHPI 0.0007
UGDS_2MOR 0.0368
UGDS_NRA 0.0179
UGDS_UNKN 0.0100
dtype: float64
In[27]: college_stacked.unstack().head()
out[27]:
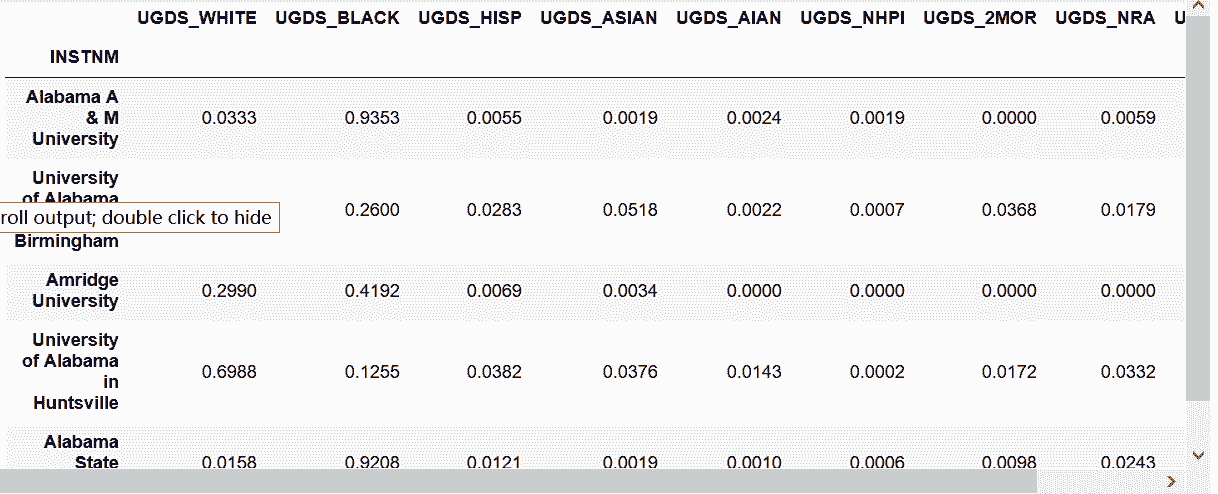
In[28]: college2 = pd.read_csv('data/college.csv',
usecols=usecol_func)
college2.head()
out[28]:

In[29]: college_melted = college2.melt(id_vars='INSTNM',
var_name='Race',
value_name='Percentage')
college_melted.head()
out[29]:

In[30]: melted_inv = college_melted.pivot(index='INSTNM',
columns='Race',
values='Percentage')
melted_inv.head()
out[30]:

In[31]: college2_replication = melted_inv.loc[college2['INSTNM'],
college2.columns[1:]]\
.reset_index()
college2.equals(college2_replication)
out[31]: True
更多
In[32]: college.stack().unstack(0)
out[32]:
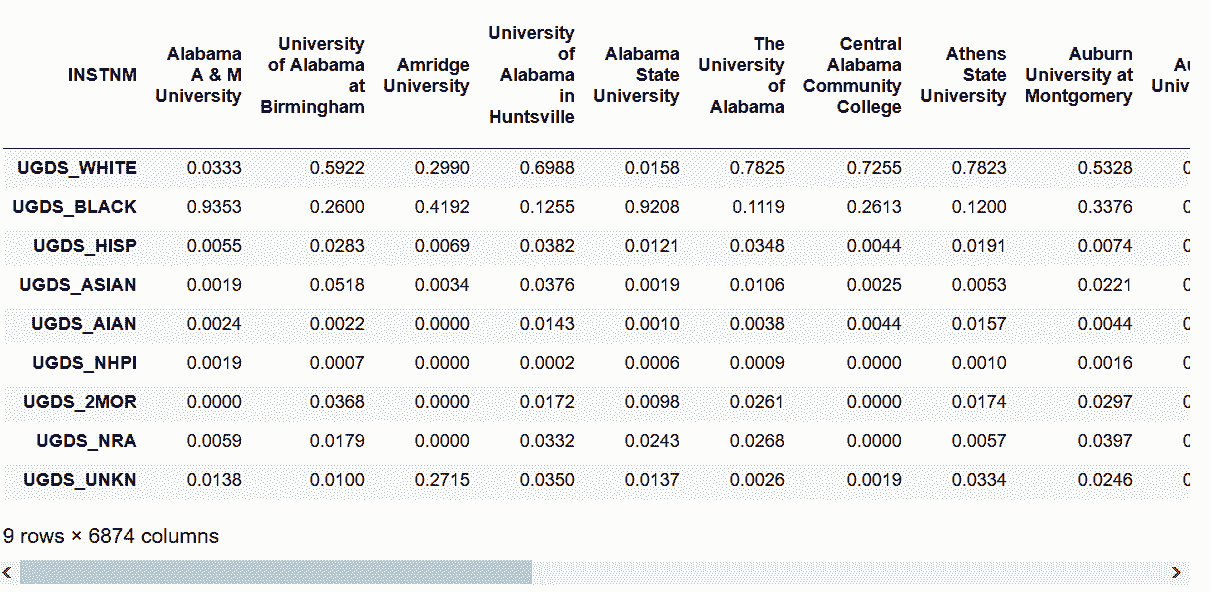
In[33]: college.T
out[33]:
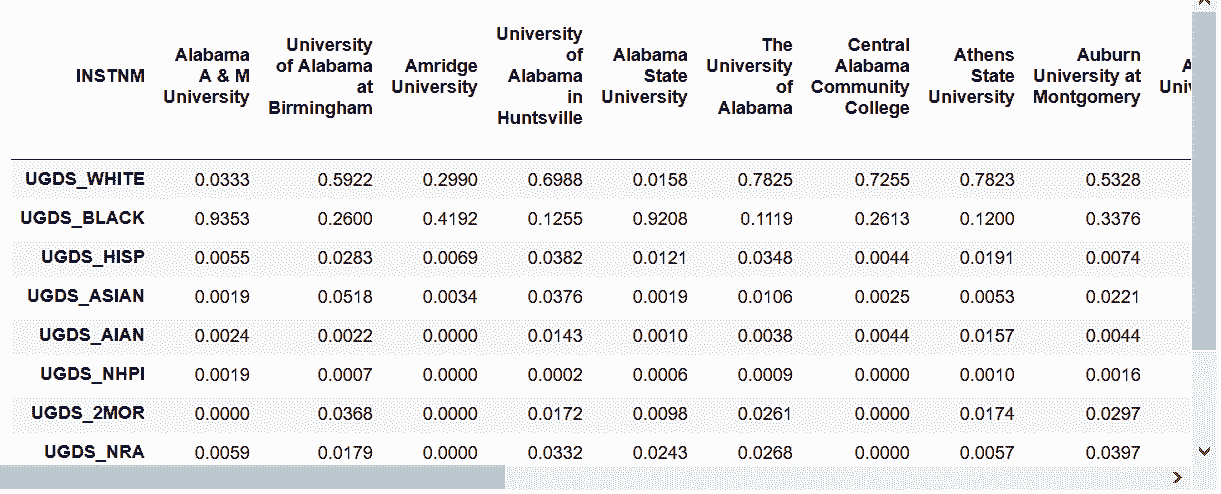
5. 分组聚合后unstacking
In[34]: employee = pd.read_csv('data/employee.csv')
In[35]: employee.groupby('RACE')['BASE_SALARY'].mean().astype(int)
out[35]: RACE
American Indian or Alaskan Native 60272
Asian/Pacific Islander 61660
Black or African American 50137
Hispanic/Latino 52345
Others 51278
White 64419
Name: BASE_SALARY, dtype: int64
In[36]: agg = employee.groupby(['RACE', 'GENDER'])['BASE_SALARY'].mean().astype(int)
agg
out[36]: RACE GENDER
American Indian or Alaskan Native Female 60238
Male 60305
Asian/Pacific Islander Female 63226
Male 61033
Black or African American Female 48915
Male 51082
Hispanic/Latino Female 46503
Male 54782
Others Female 63785
Male 38771
White Female 66793
Male 63940
Name: BASE_SALARY, dtype: int64
In[37]: agg.unstack('GENDER')
out[37]:

In[38]: agg.unstack('RACE')
out[38]:

更多
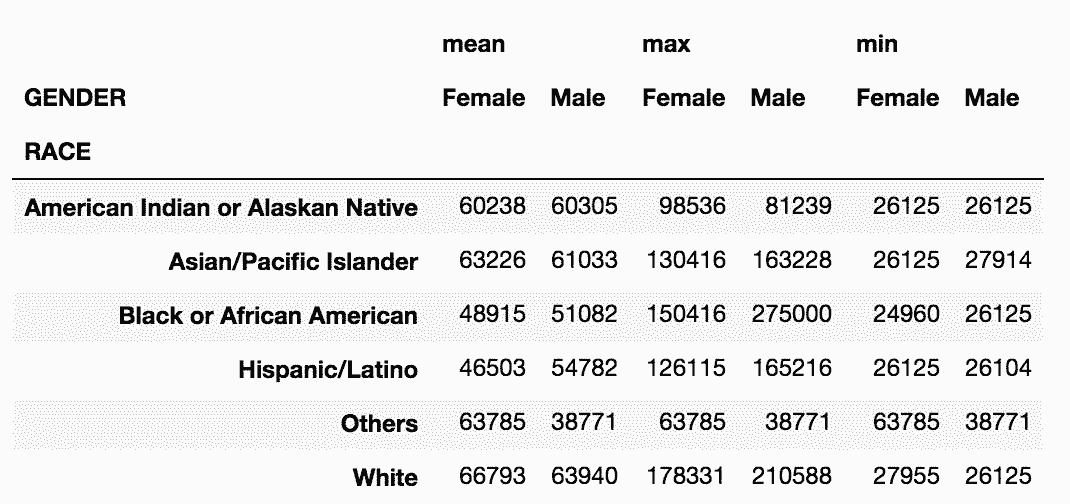
In[39]: agg2 = employee.groupby(['RACE', 'GENDER'])['BASE_SALARY'].agg(['mean', 'max', 'min']).astype(int)
agg2
out[39]:
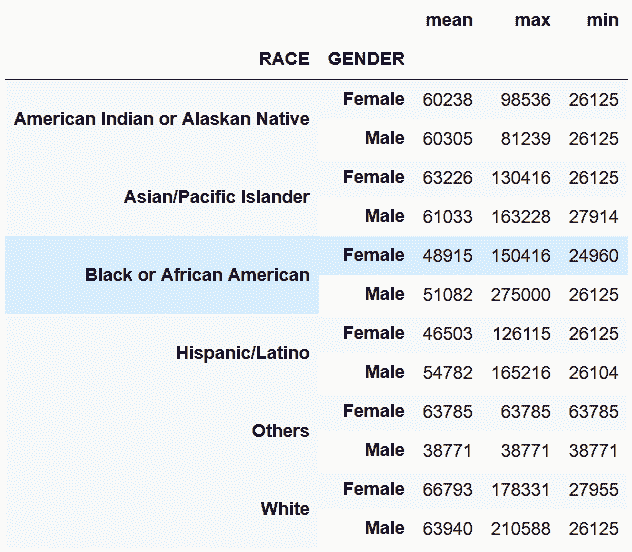
agg2.unstack('GENDER')
6. 用分组聚合实现透视表
In[40]: flights = pd.read_csv('data/flights.csv')
flights.head()
out[40]:
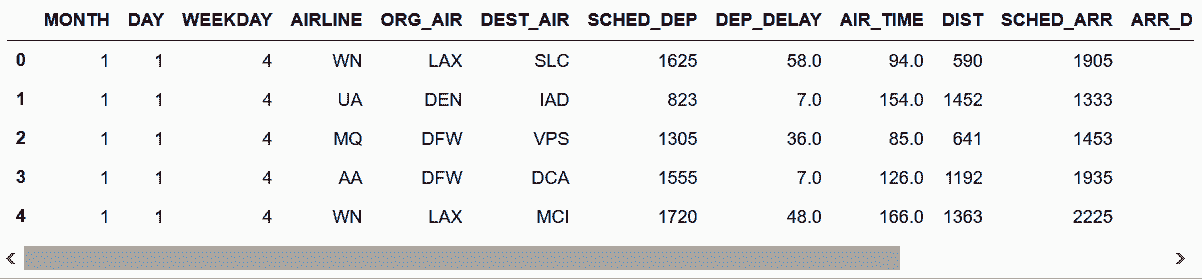
In[41]: fp = flights.pivot_table(index='AIRLINE',
columns='ORG_AIR',
values='CANCELLED',
aggfunc='sum',
fill_value=0).round(2)
fp.head()
out[41]:
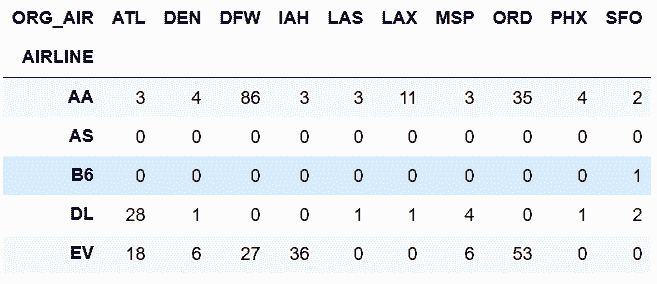
In[42]: fg = flights.groupby(['AIRLINE', 'ORG_AIR'])['CANCELLED'].sum()
fg.head()
out[42]: AIRLINE ORG_AIR
AA ATL 3
DEN 4
DFW 86
IAH 3
LAS 3
Name: CANCELLED, dtype: int64
In[43]: fg_unstack = fg.unstack('ORG_AIR', fill_value=0)
fg_unstack.head()
out[43]:
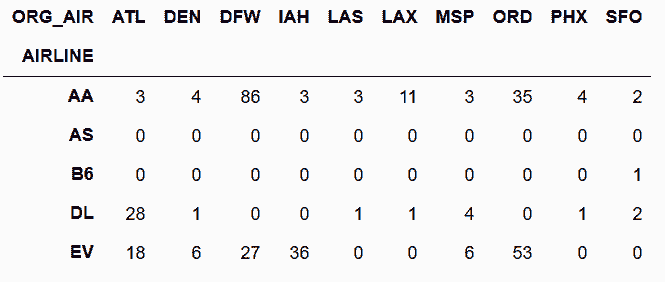
In[44]: fg_unstack = fg.unstack('ORG_AIR', fill_value=0)
fp.equals(fg_unstack)
out[44]: True
更多
In[45]: fp2 = flights.pivot_table(index=['AIRLINE', 'MONTH'],
columns=['ORG_AIR', 'CANCELLED'],
values=['DEP_DELAY', 'DIST'],
aggfunc=[np.mean, np.sum],
fill_value=0)
fp2.head()
out[45]:
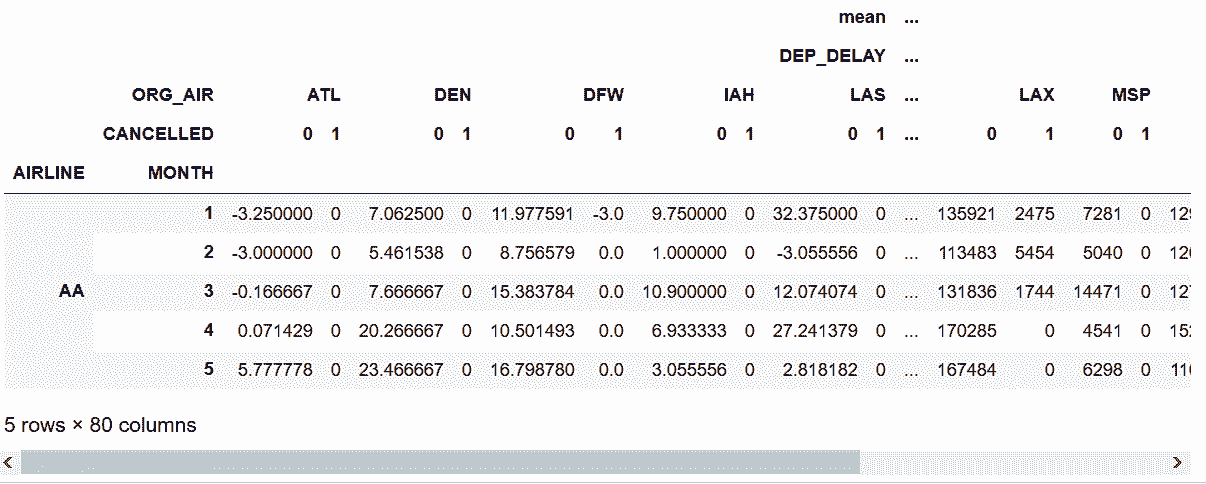
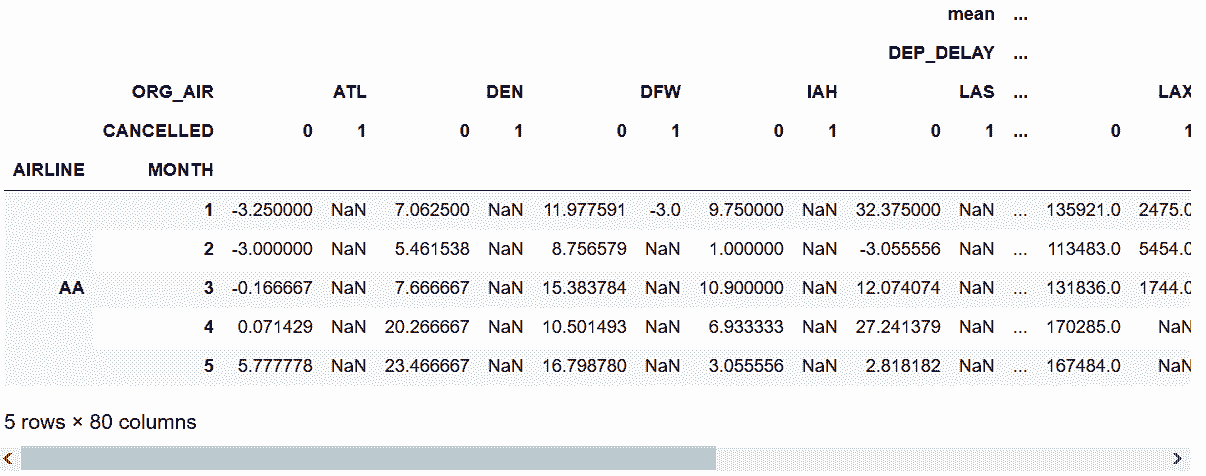
In[46]: flights.groupby(['AIRLINE', 'MONTH', 'ORG_AIR', 'CANCELLED'])['DEP_DELAY', 'DIST'] \
.agg(['mean', 'sum']) \
.unstack(['ORG_AIR', 'CANCELLED'], fill_value=0) \
.swaplevel(0, 1, axis='columns') \
.head()
out[46]:
7. 为了更容易reshaping,重新命名索引层
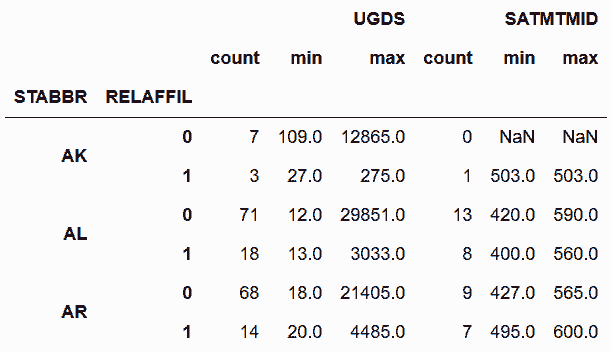
In[47]: college = pd.read_csv('data/college.csv')
In[48]: cg = college.groupby(['STABBR', 'RELAFFIL'])['UGDS', 'SATMTMID'] \
.agg(['count', 'min', 'max']).head(6)
In[49]: cg
out[49]:
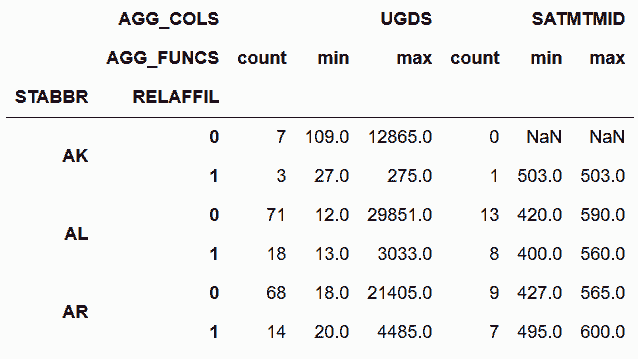
In[50]:cg = cg.rename_axis(['AGG_COLS', 'AGG_FUNCS'], axis='columns')
cg
out[50]:
In[51]:cg.stack('AGG_FUNCS').head()
out[51]:

In[52]:cg.stack('AGG_FUNCS').swaplevel('AGG_FUNCS', 'STABBR', axis='index').head()
out[52]:
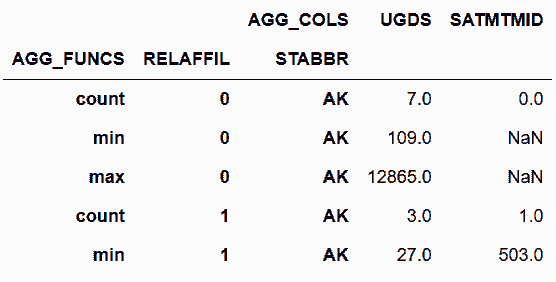
In[53]:cg.stack('AGG_FUNCS') \
.swaplevel('AGG_FUNCS', 'STABBR', axis='index') \
.sort_index(level='RELAFFIL', axis='index') \
.sort_index(level='AGG_COLS', axis='columns').head(6)
out[53]:
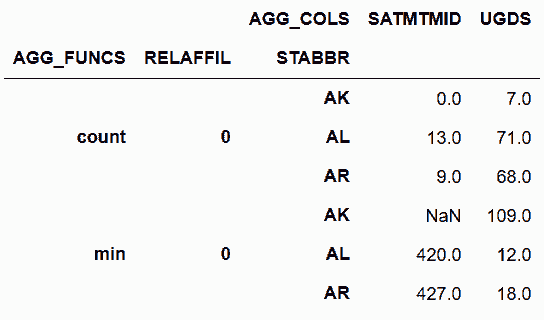
In[54]:cg.stack('AGG_FUNCS').unstack(['RELAFFIL', 'STABBR'])
out[54]:
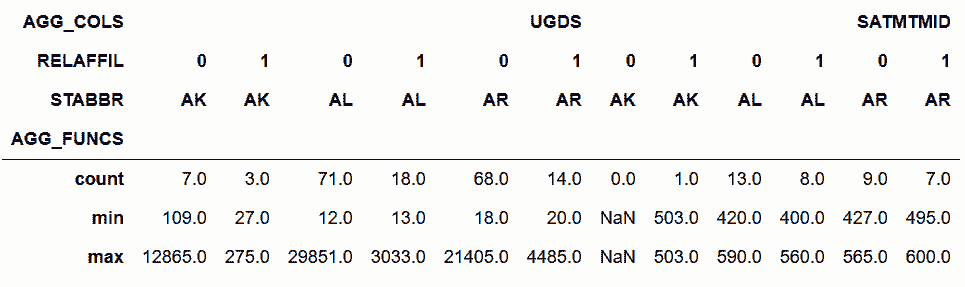
In[55]:cg.stack(['AGG_FUNCS', 'AGG_COLS']).head(12)
out[55]:

更多
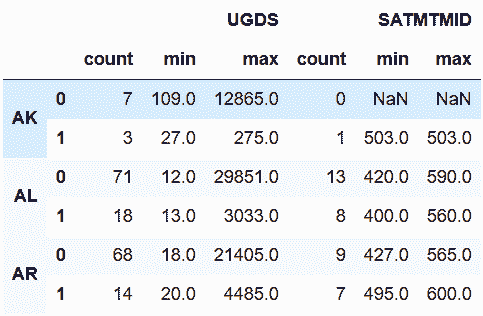
In[56]:cg.rename_axis([None, None], axis='index').rename_axis([None, None], axis='columns')
out[56]:
8. 当多个变量被存储为列名时进行清理
In[57]:weightlifting = pd.read_csv('data/weightlifting_men.csv')
weightlifting
out[57]:
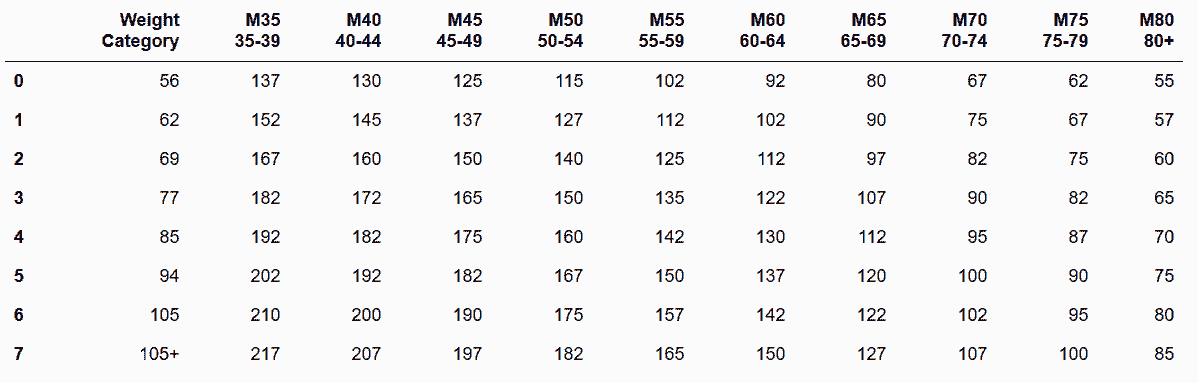
In[58]:wl_melt = weightlifting.melt(id_vars='Weight Category',
var_name='sex_age',
value_name='Qual Total')
wl_melt.head()
out[58]:
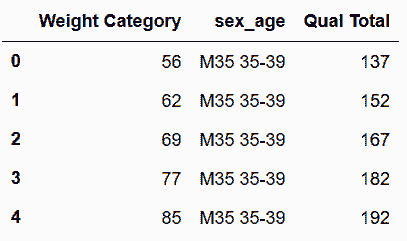
In[59]:sex_age = wl_melt['sex_age'].str.split(expand=True)
sex_age.head()
out[59]: 0 1
0 M35 35-39
1 M35 35-39
2 M35 35-39
3 M35 35-39
4 M35 35-39
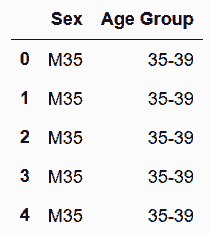
In[60]:sex_age.columns = ['Sex', 'Age Group']
sex_age.head()
out[60]:
In[61]:sex_age['Sex'] = sex_age['Sex'].str[0]
sex_age.head()
out[61]:
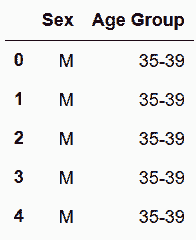
In[62]:wl_cat_total = wl_melt[['Weight Category', 'Qual Total']]
wl_tidy = pd.concat([sex_age, wl_cat_total], axis='columns')
wl_tidy.head()
out[62]:
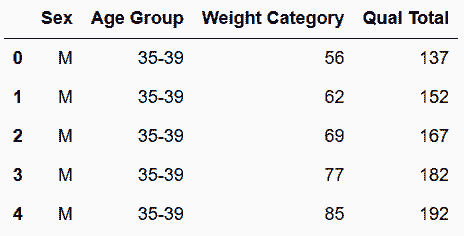
In[63]:cols = ['Weight Category', 'Qual Total']
sex_age[cols] = wl_melt[cols]
更多
In[64]: age_group = wl_melt.sex_age.str.extract('(\d{2}[-+](?:\d{2})?)', expand=False)
sex = wl_melt.sex_age.str[0]
new_cols = {'Sex':sex,
'Age Group': age_group}
In[65]: wl_tidy2 = wl_melt.assign(**new_cols).drop('sex_age', axis='columns')
wl_tidy2.head()
out[65]:
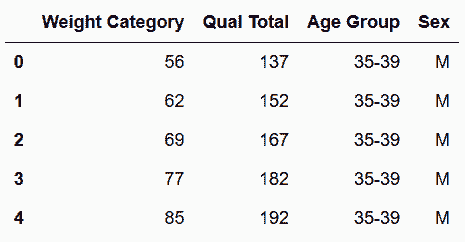
In[66]: wl_tidy2.sort_index(axis=1).equals(wl_tidy.sort_index(axis=1))
out[66]: True
9. 当多个变量被存储为列的值时进行清理
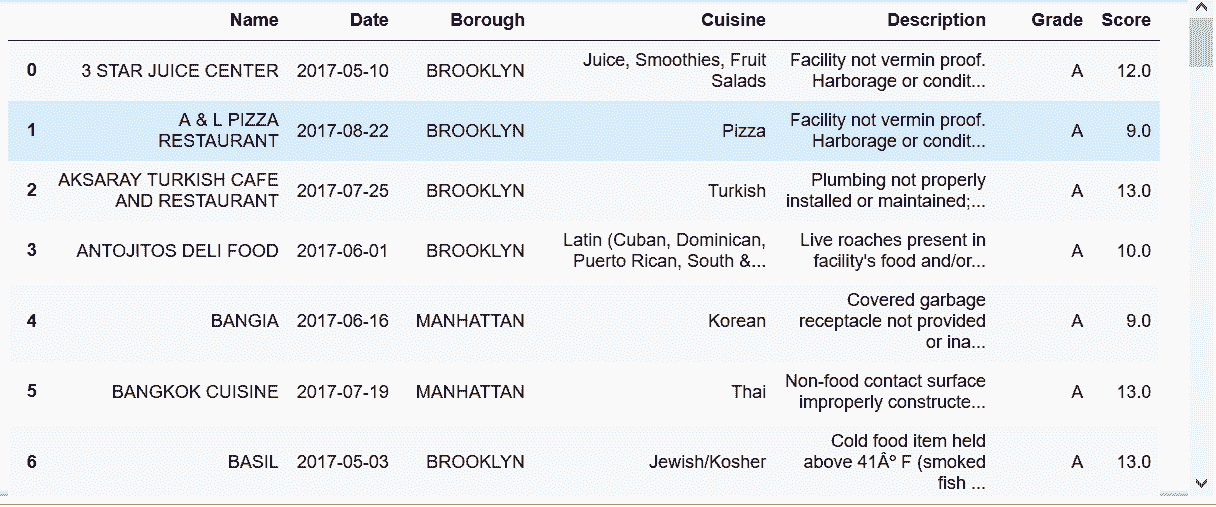
In[67]: inspections = pd.read_csv('data/restaurant_inspections.csv', parse_dates=['Date'])
inspections.head(10)
out[67]:
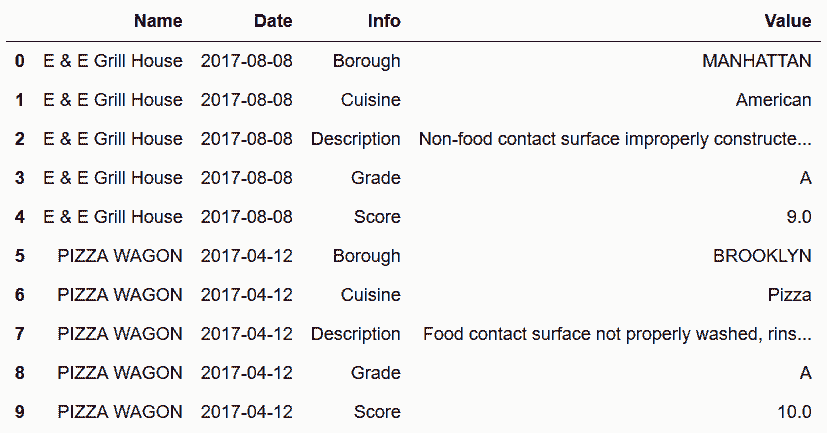
# 用info列的所有值造一个新列。但是,Pandas不支持这种功能
In[68]: inspections.pivot(index=['Name', 'Date'], columns='Info', values='Value')
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
/Users/Ted/anaconda/lib/python3.6/site-packages/pandas/core/categorical.py in __init__(self, values, categories, ordered, fastpath)
297 try:
--> 298 codes, categories = factorize(values, sort=True)
299 except TypeError:
/Users/Ted/anaconda/lib/python3.6/site-packages/pandas/core/algorithms.py in factorize(values, sort, order, na_sentinel, size_hint)
559 check_nulls = not is_integer_dtype(original)
--> 560 labels = table.get_labels(values, uniques, 0, na_sentinel, check_nulls)
561
pandas/_libs/hashtable_class_helper.pxi in pandas._libs.hashtable.PyObjectHashTable.get_labels (pandas/_libs/hashtable.c:21922)()
ValueError: Buffer has wrong number of dimensions (expected 1, got 2)
During handling of the above exception, another exception occurred:
NotImplementedError Traceback (most recent call last)
<ipython-input-68-754f69d68d6c> in <module>()
----> 1 inspections.pivot(index=['Name', 'Date'], columns='Info', values='Value')
/Users/Ted/anaconda/lib/python3.6/site-packages/pandas/core/frame.py in pivot(self, index, columns, values)
3851 """
3852 from pandas.core.reshape.reshape import pivot
-> 3853 return pivot(self, index=index, columns=columns, values=values)
3854
3855 def stack(self, level=-1, dropna=True):
/Users/Ted/anaconda/lib/python3.6/site-packages/pandas/core/reshape/reshape.py in pivot(self, index, columns, values)
375 index = self[index]
376 indexed = Series(self[values].values,
--> 377 index=MultiIndex.from_arrays([index, self[columns]]))
378 return indexed.unstack(columns)
379
/Users/Ted/anaconda/lib/python3.6/site-packages/pandas/core/indexes/multi.py in from_arrays(cls, arrays, sortorder, names)
1098 from pandas.core.categorical import _factorize_from_iterables
1099
-> 1100 labels, levels = _factorize_from_iterables(arrays)
1101 if names is None:
1102 names = [getattr(arr, "name", None) for arr in arrays]
/Users/Ted/anaconda/lib/python3.6/site-packages/pandas/core/categorical.py in _factorize_from_iterables(iterables)
2191 # For consistency, it should return a list of 2 lists.
2192 return [[], []]
-> 2193 return map(list, lzip(*[_factorize_from_iterable(it) for it in iterables]))
/Users/Ted/anaconda/lib/python3.6/site-packages/pandas/core/categorical.py in <listcomp>(.0)
2191 # For consistency, it should return a list of 2 lists.
2192 return [[], []]
-> 2193 return map(list, lzip(*[_factorize_from_iterable(it) for it in iterables]))
/Users/Ted/anaconda/lib/python3.6/site-packages/pandas/core/categorical.py in _factorize_from_iterable(values)
2163 codes = values.codes
2164 else:
-> 2165 cat = Categorical(values, ordered=True)
2166 categories = cat.categories
2167 codes = cat.codes
/Users/Ted/anaconda/lib/python3.6/site-packages/pandas/core/categorical.py in __init__(self, values, categories, ordered, fastpath)
308
309 # FIXME
--> 310 raise NotImplementedError("> 1 ndim Categorical are not "
311 "supported at this time")
312
NotImplementedError: > 1 ndim Categorical are not supported at this time
In[69]: inspections.set_index(['Name','Date', 'Info']).head(10)
out[69]:
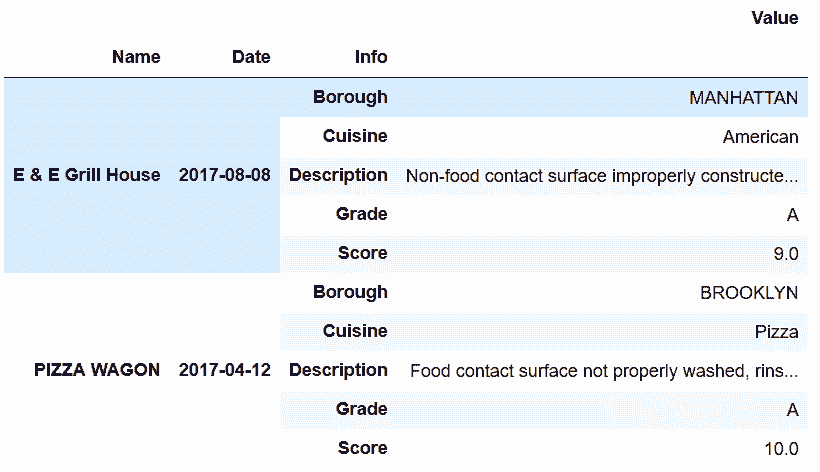
In[70]: inspections.set_index(['Name','Date', 'Info']).unstack('Info').head()
out[70]:
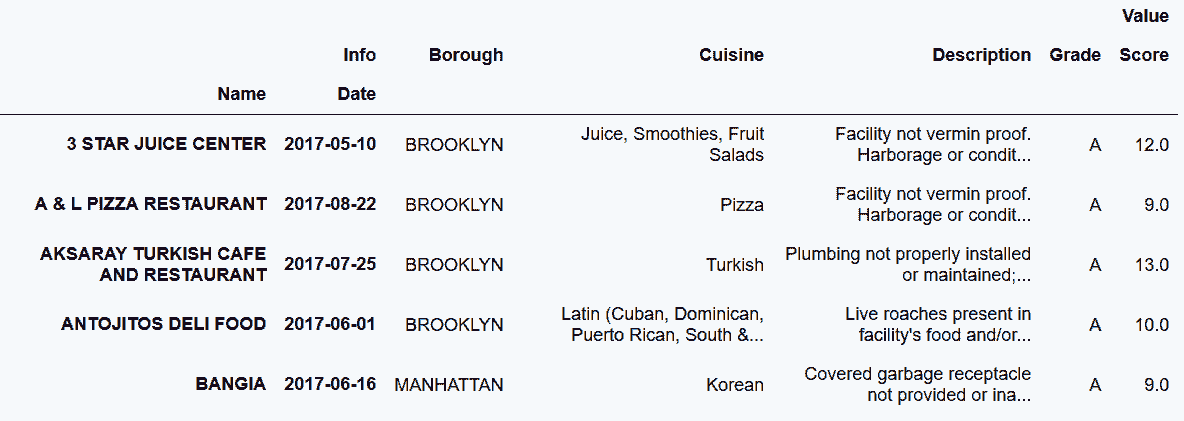
In[71]: insp_tidy = inspections.set_index(['Name','Date', 'Info']) \
.unstack('Info') \
.reset_index(col_level=-1)
insp_tidy.head()
out[71]:
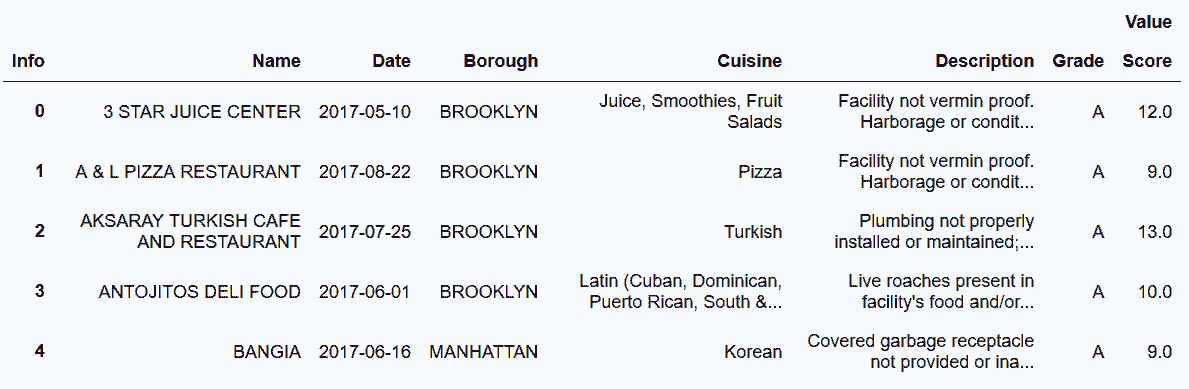
In[72]: insp_tidy.columns = insp_tidy.columns.droplevel(0).rename(None)
insp_tidy.head()
out[72]:
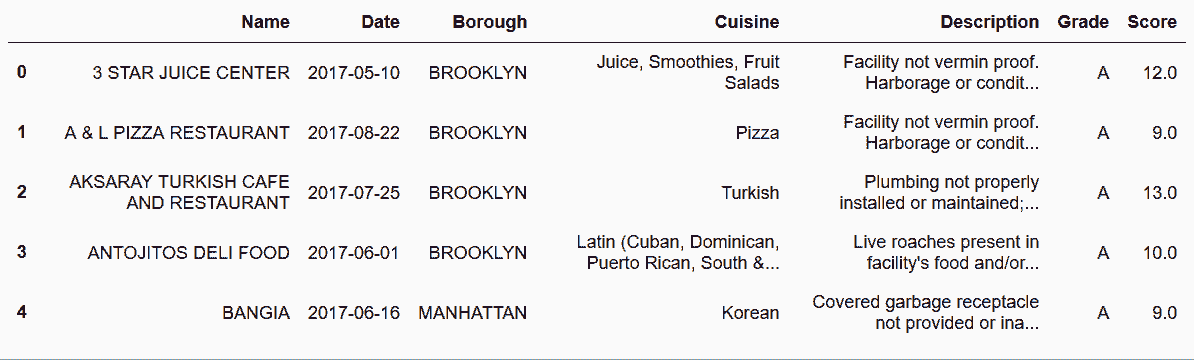
In[73]: inspections.set_index(['Name','Date', 'Info']) \
.squeeze() \
.unstack('Info') \
.reset_index() \
.rename_axis(None, axis='columns')
out[73]:
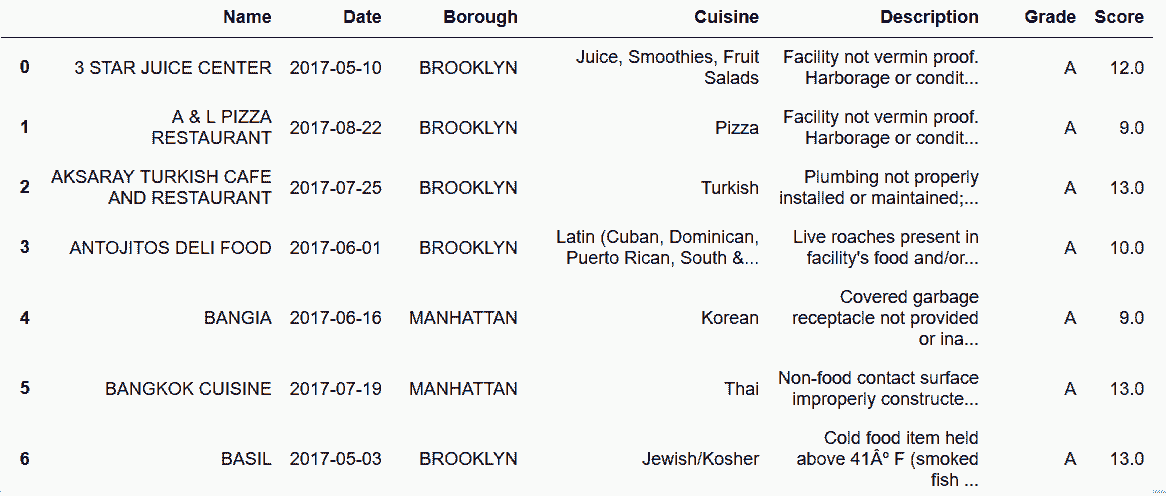
更多
In[74]: inspections.pivot_table(index=['Name', 'Date'],
columns='Info',
values='Value',
aggfunc='first') \
.reset_index()\
.rename_axis(None, axis='columns')
out[74]:
10. 当两个或多个值存储于一个单元格时进行清理
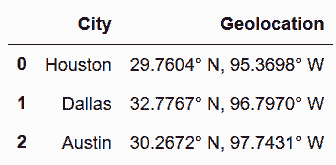
In[75]: cities = pd.read_csv('data/texas_cities.csv')
cities
out[75]:
In[76]: geolocations = cities.Geolocation.str.split(pat='. ', expand=True)
geolocations.columns = ['latitude', 'latitude direction', 'longitude', 'longitude direction']
geolocations
out[76]:

In[77]: geolocations = geolocations.astype({'latitude':'float', 'longitude':'float'})
geolocations.dtypes
out[77]: latitude float64
latitude direction object
longitude float64
longitude direction object
dtype: object
In[78]: cities_tidy = pd.concat([cities['City'], geolocations], axis='columns')
cities_tidy
out[78]:

In[79]: pd.concat([cities['City'], geolocations], axis='columns')
out[79]:

原理
In[80]: temp = geolocations.apply(pd.to_numeric, errors='ignore')
temp
out[80]:

In[81]: temp.dtypes
out[81]: latitude float64
latitude direction object
longitude float64
longitude direction object
dtype: object
更多
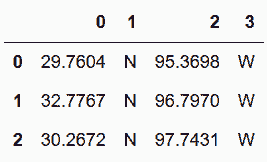
In[82]: cities.Geolocation.str.split(pat='° |, ', expand=True)
out[82]:
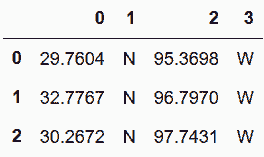
In[83]: cities.Geolocation.str.extract('([0-9.]+). (N|S), ([0-9.]+). (E|W)', expand=True)
out[83]:
11. 当多个变量被存储为列名和列值时进行清理
In[84]: sensors = pd.read_csv('data/sensors.csv')
sensors
out[84]:
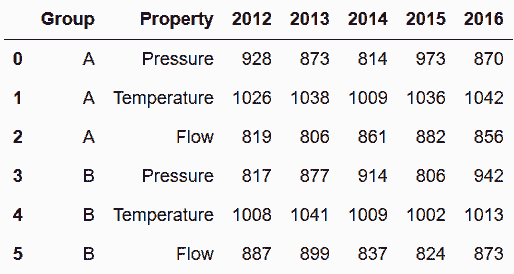
In[85]: sensors.melt(id_vars=['Group', 'Property'], var_name='Year').head(6)
out[85]:
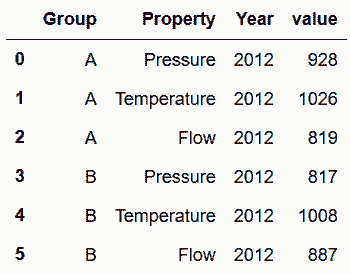
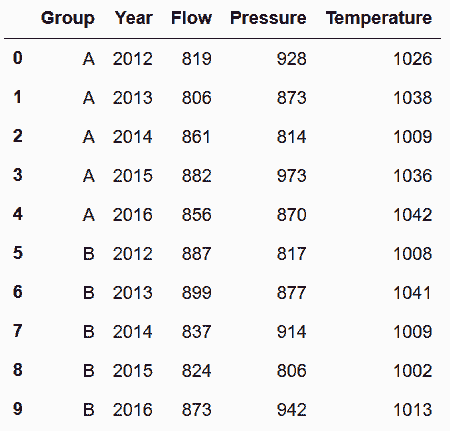
In[86]: sensors.melt(id_vars=['Group', 'Property'], var_name='Year') \
.pivot_table(index=['Group', 'Year'], columns='Property', values='value') \
.reset_index() \
.rename_axis(None, axis='columns')
out[86]:
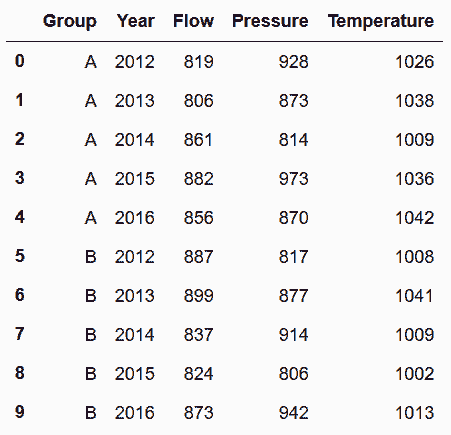
更多
In[87]: sensors.set_index(['Group', 'Property']) \
.stack() \
.unstack('Property') \
.rename_axis(['Group', 'Year'], axis='index') \
.rename_axis(None, axis='columns') \
.reset_index()
out[87]:
12. 当多个观察单位被存储于同一张表时进行清理
In[88]: movie = pd.read_csv('data/movie_altered.csv')
movie.head()
out[88]:

In[89]: movie.insert(0, 'id', np.arange(len(movie)))
movie.head()
out[89]:
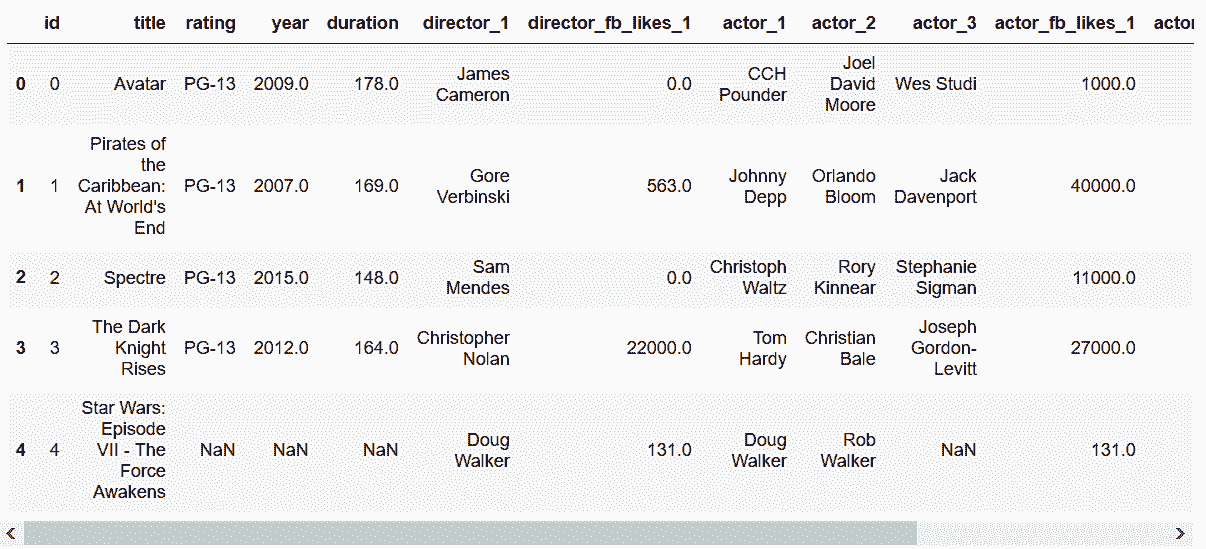
In[90]: stubnames = ['director', 'director_fb_likes', 'actor', 'actor_fb_likes']
movie_long = pd.wide_to_long(movie,
stubnames=stubnames,
i='id',
j='num',
sep='_').reset_index()
movie_long['num'] = movie_long['num'].astype(int)
movie_long.head(9)
out[90]:
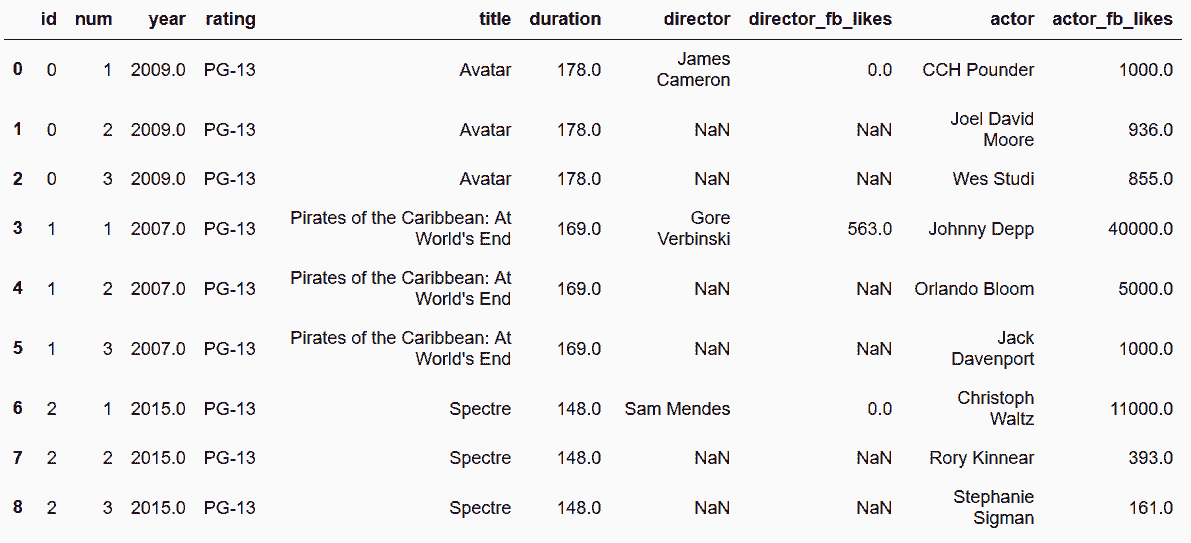
In[91]: movie_table = movie_long[['id','title', 'year', 'duration', 'rating']]
director_table = movie_long[['id', 'director', 'num', 'director_fb_likes']]
actor_table = movie_long[['id', 'actor', 'num', 'actor_fb_likes']]
In[92]: movie_table.head(9)
out[90]:
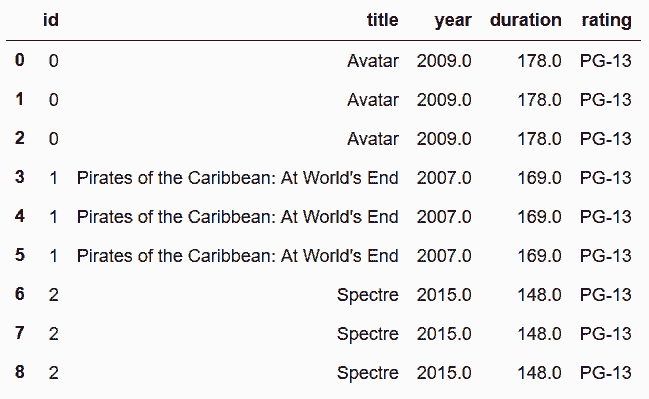
In[93]: director_table.head(9)
out[93]:
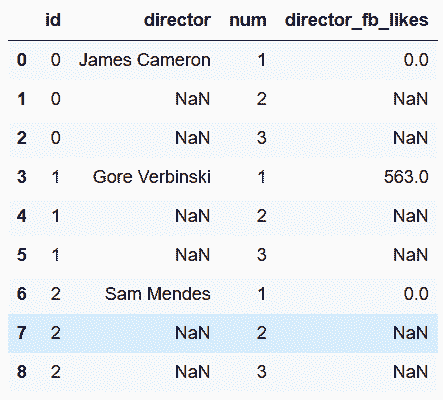
In[94]: actor_table.head(9)
out[94]:
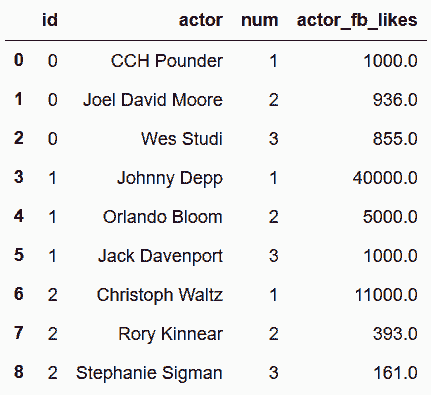
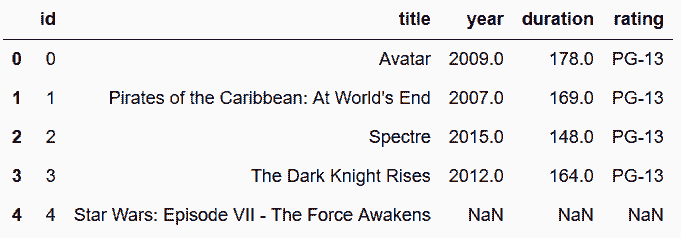
In[95]: movie_table = movie_table.drop_duplicates().reset_index(drop=True)
director_table = director_table.dropna().reset_index(drop=True)
actor_table = actor_table.dropna().reset_index(drop=True)
In[96]: movie_table.head()
out[96]:
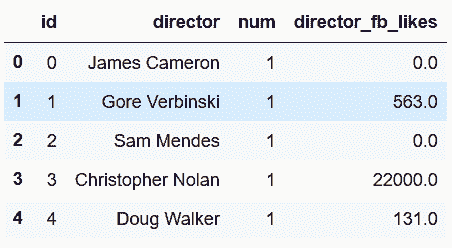
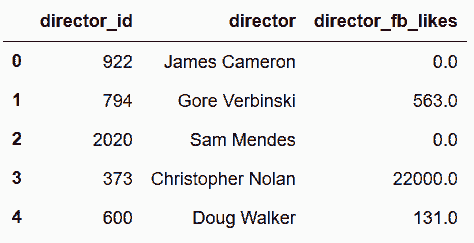
In[97]: director_table.head()
out[97]:
In[98]: movie.memory_usage(deep=True).sum()
out[98]: 2318234
In[99]: movie_table.memory_usage(deep=True).sum() + \
director_table.memory_usage(deep=True).sum() + \
actor_table.memory_usage(deep=True).sum()
out[99]: 2624898
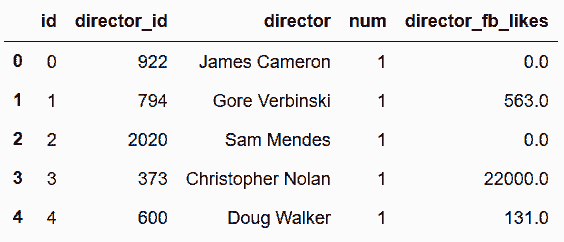
In[100]: director_cat = pd.Categorical(director_table['director'])
director_table.insert(1, 'director_id', director_cat.codes)
actor_cat = pd.Categorical(actor_table['actor'])
actor_table.insert(1, 'actor_id', actor_cat.codes)
director_table.head()
out[100]:
In[101]: actor_table.head()
out[101]:
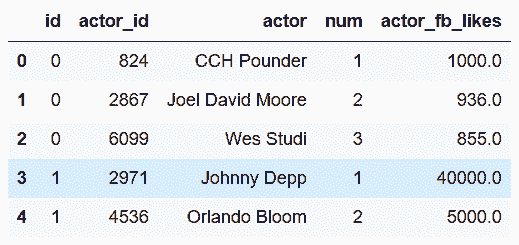
In[102]: director_associative = director_table[['id', 'director_id', 'num']]
dcols = ['director_id', 'director', 'director_fb_likes']
director_unique = director_table[dcols].drop_duplicates().reset_index(drop=True)
director_associative.head()
out[102]:

In[103]: director_unique.head()
out[103]:
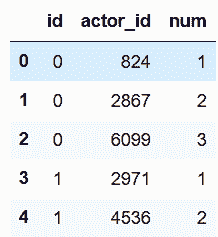
In[104]: actor_associative = actor_table[['id', 'actor_id', 'num']]
acols = ['actor_id', 'actor', 'actor_fb_likes']
actor_unique = actor_table[acols].drop_duplicates().reset_index(drop=True)
actor_associative.head()
out[104]:
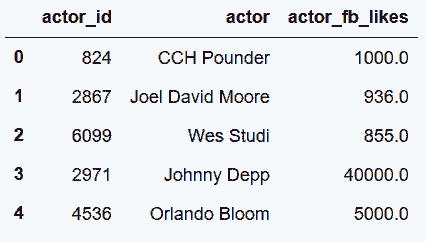
In[105]: actor_unique.head()
out[105]:
In[106]: movie_table.memory_usage(deep=True).sum() + \
director_associative.memory_usage(deep=True).sum() + \
director_unique.memory_usage(deep=True).sum() + \
actor_associative.memory_usage(deep=True).sum() + \
actor_unique.memory_usage(deep=True).sum()
out[106]: 1833402
In[107]: movie_table.head()
out[107]:

In[108]: actors = actor_associative.merge(actor_unique, on='actor_id') \
.drop('actor_id', 1) \
.pivot_table(index='id', columns='num', aggfunc='first')
actors.columns = actors.columns.get_level_values(0) + '_' + \
actors.columns.get_level_values(1).astype(str)
directors = director_associative.merge(director_unique, on='director_id') \
.drop('director_id', 1) \
.pivot_table(index='id', columns='num', aggfunc='first')
directors.columns = directors.columns.get_level_values(0) + '_' + \
directors.columns.get_level_values(1).astype(str)
In[109]: actors.head()
out[109]:
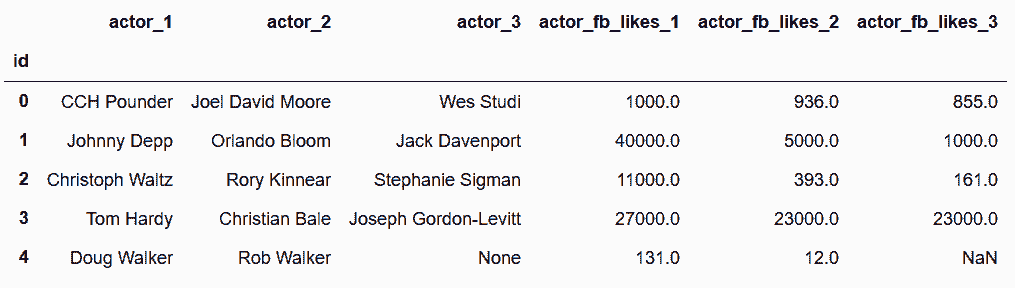
In[110]: directors.head()
out[110]:

In[111]: movie2 = movie_table.merge(directors.reset_index(), on='id', how='left') \
.merge(actors.reset_index(), on='id', how='left')
In[112]: movie2.head()
out[112]:
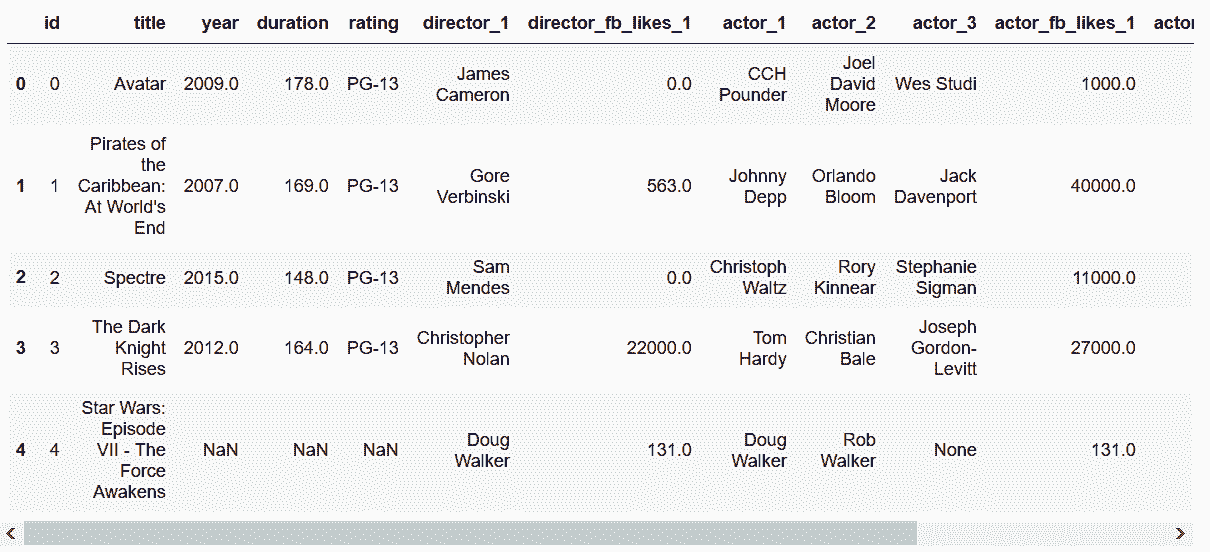
In[113]: movie.equals(movie2[movie.columns])
out[113]: True