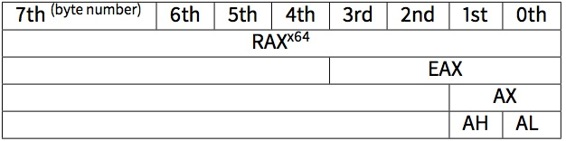
#include <stdio.h>
int f1()
{
printf ("world\n");
}
int f2()
{
printf ("hello world\n");
}
int main()
{
f1();
f2();
}
一般的C/C++编译器(包括MSVC)会分别分配给地址两个字符串,但是让我们看看GCC干了什么:
代码清单 3.10: GCC 4.8.1 + IDA listing
f1 proc near
s = dword ptr -1Ch
sub esp, 1Ch
mov [esp+1Ch+s], offset s ; "world\n"
call _puts
add esp, 1Ch
retn
f1 endp
f2 proc near
s = dword ptr -1Ch
sub esp, 1Ch
mov [esp+1Ch+s], offset aHello ; "hello "
call _puts
add esp, 1Ch
retn
f2 endp
aHello db 'hello '
s db 'world',0xa,0
P. Z. Ingerman说这个函数是"提供地址的一段代码",他于1961年,发明了形实转换函数,并作为Algol-60 程序调用里,将实参转换为标准定义的一种方式。
如果调用一个带有表达式形参的程序,编译器会生成一个形实转换函数来计算表达式的值,并将结果的地址放在某些标准位置上。
...
Microsoft 和 IBM 都在他们的基于Intel的系统里面定义了一个“16-位的环境”(带有讨厌的段寄存器和64K的内存限制)和一个“32-位的环境”(带有平坦寻址和半实时的内存管理)。
这两种环境都能在相同的电脑和操作系统上运行(感谢我们在Microsoft世界里称之为WOW的东西,WOW代表着Windows On Windows)。
MS 和 IBM都决定将16位到32位和相反的转换过程称为一个"thunk";对于Windows 95来说,甚至有个叫做“Thunk编译器”的工具——THUNK.EXE。
1 $LC0:
2 ; \000 is zero byte in octal base:
3 .ascii "Hello, world!\012\000"
4 main:
5 ; function prologue.
6 ; set the GP:
7 lui $28,%hi(__gnu_local_gp)
8 addiu $sp,$sp,-32
9 addiu $28,$28,%lo(__gnu_local_gp)
10 ; save the RA to the local stack:
11 sw $31,28($sp)
12 ; load the address of the puts() function from the GP to $25:
13 lw $25,%call16(puts)($28)
14 ; load the address of the text string to $4 ($a0):
15 lui $4,%hi($LC0)
16 ; jump to puts(), saving the return address in the link register:
17 jalr $25
18 addiu $4,$4,%lo($LC0) ; branch delay slot
19 ; restore the RA:
20 lw $31,28($sp)
21 ; copy 0 from $zero to $v0:
22 move $2,$0
23 ; return by jumping to the RA:
24 j $31
25 ; function epilogue:
26 addiu $sp,$sp,32 ; branch delay slot
代码清单 3.19: 带优化的 GCC 4.4.5 (IDA)
1 .text:00000000 main:
2 .text:00000000
3 .text:00000000 var_10 = -0x10
4 .text:00000000 var_4 = -4
5 .text:00000000
6 ; function prologue.
7 ; set the GP:
8 .text:00000000 lui $gp, (__gnu_local_gp >> 16)
9 .text:00000004 addiu $sp, -0x20
10 .text:00000008 la $gp, (__gnu_local_gp & 0xFFFF)
11 ; save the RA to the local stack:
12 .text:0000000C sw $ra, 0x20+var_4($sp)
13 ; save the GP to the local stack:
14 ; for some reason, this instruction is missing in the GCC assembly output:
15 .text:00000010 sw $gp, 0x20+var_10($sp)
16 ; load the address of the puts() function from the GP to $t9:
17 .text:00000014 lw $t9, (puts & 0xFFFF)($gp)
18 ; form the address of the text string in $a0:
19 .text:00000018 lui $a0, ($LC0 >> 16) # "Hello, world!"
20 ; jump to puts(), saving the return address in the link register:
21 .text:0000001C jalr $t9
22 .text:00000020 la $a0, ($LC0 & 0xFFFF) # "Hello, world!"
23 ; restore the RA:
24 .text:00000024 lw $ra, 0x20+var_4($sp)
25 ; copy 0 from $zero to $v0:
26 .text:00000028 move $v0, $zero
27 ; return by jumping to the RA:
28 .text:0000002C jr $ra
29 ; function epilogue:
30 .text:00000030 addiu $sp, 0x20
3.5.3 无优化的 GCC
无优化的GCC会产生更冗长的代码:
代码清单 3.20: 无优化的 GCC 4.4.5 (汇编输出)
1 $LC0:
2 .ascii "Hello, world!\012\000"
3 main:
4 ; function prologue.
5 ; save the RA ($31) and FP in the stack:
6 addiu $sp,$sp,-32
7 sw $31,28($sp)
8 sw $fp,24($sp)
9 ; set the FP (stack frame pointer):
10 move $fp,$sp
11 ; set the GP:
12 lui $28,%hi(__gnu_local_gp)
13 addiu $28,$28,%lo(__gnu_local_gp)
14 ; load the address of the text string:
15 lui $2,%hi($LC0)
16 addiu $4,$2,%lo($LC0)
17 ; load the address of puts() using the GP:
18 lw $2,%call16(puts)($28)
19 nop
20 ; call puts():
21 move $25,$2
22 jalr $25
23 nop ; branch delay slot
24
25 ; restore the GP from the local stack:
26 lw $28,16($fp)
27 ; set register $2 ($V0) to zero:
28 move $2,$0
29 ; function epilogue.
30 ; restore the SP:
31 move $sp,$fp
32 ; restore the RA:
33 lw $31,28($sp)
34 ; restore the FP:
35 lw $fp,24($sp)
36 addiu $sp,$sp,32
37 ; jump to the RA:
38 j $31
39 nop ; branch delay slot
代码清单 3.21: 无优化的 GCC 4.4.5 (IDA)
1 .text:00000000 main:
2 .text:00000000
3 .text:00000000 var_10 = -0x10
4 .text:00000000 var_8 = -8
5 .text:00000000 var_4 = -4
6 .text:00000000
7 ; function prologue.
8 ; save the RA and FP in the stack:
9 .text:00000000 addiu $sp, -0x20
10 .text:00000004 sw $ra, 0x20+var_4($sp)
11 .text:00000008 sw $fp, 0x20+var_8($sp)
12 ; set the FP (stack frame pointer):
13 .text:0000000C move $fp, $sp
14 ; set the GP:
15 .text:00000010 la $gp, __gnu_local_gp
16 .text:00000018 sw $gp, 0x20+var_10($sp)
17 ; load the address of the text string:
18 .text:0000001C lui $v0, (aHelloWorld >> 16) # "Hello, world!"
19 .text:00000020 addiu $a0, $v0, (aHelloWorld & 0xFFFF) # "Hello, world!"
20 ; load the address of puts() using the GP:
21 .text:00000024 lw $v0, (puts & 0xFFFF)($gp)
22 .text:00000028 or $at, $zero ; NOP
23 ; call puts():
24 .text:0000002C move $t9, $v0
25 .text:00000030 jalr $t9
26 .text:00000034 or $at, $zero ; NOP
27 ; restore the GP from local stack:
28 .text:00000038 lw $gp, 0x20+var_10($fp)
29 ; set register $2 ($V0) to zero:
30 .text:0000003C move $v0, $zero
31 ; function epilogue.
32 ; restore the SP:
33 .text:00000040 move $sp, $fp
34 ; restore the RA:
35 .text:00000044 lw $ra, 0x20+var_4($sp)
36 ; restore the FP:
37 .text:00000048 lw $fp, 0x20+var_8($sp)
38 .text:0000004C addiu $sp, 0x20
39 ; jump to the RA:
40 .text:00000050 jr $ra
41 .text:00000054 or $at, $zero ; NOP
root@debian-mips:~# gcc hw.c -O3 -o hw
root@debian-mips:~# gdb hw
GNU gdb (GDB) 7.0.1-debian
Copyright (C) 2009 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "mips-linux-gnu".
For bug reporting instructions, please see:
<http://www.gnu.org/software/gdb/bugs/>...
Reading symbols from /root/hw...(no debugging symbols found)...done.
(gdb) b main
Breakpoint 1 at 0x400654
(gdb) run
Starting program: /root/hw
Breakpoint 1, 0x00400654 in main ()
(gdb) set step-mode on
(gdb) disas
Dump of assembler code for function main:
0x00400640 <main+0>: lui gp,0x42
0x00400644 <main+4>: addiu sp,sp,-32
0x00400648 <main+8>: addiu gp,gp,-30624
0x0040064c <main+12>: sw ra,28(sp)
0x00400650 <main+16>: sw gp,16(sp)
0x00400654 <main+20>: lw t9,-32716(gp)
0x00400658 <main+24>: lui a0,0x40
0x0040065c <main+28>: jalr t9
0x00400660 <main+32>: addiu a0,a0,2080
0x00400664 <main+36>: lw ra,28(sp)
0x00400668 <main+40>: move v0,zero
0x0040066c <main+44>: jr ra
0x00400670 <main+48>: addiu sp,sp,32
End of assembler dump.
(gdb) s
0x00400658 in main ()
(gdb) s
0x0040065c in main ()
(gdb) s
0x2ab2de60 in printf () from /lib/libc.so.6
(gdb) x/s $a0
0x400820: "hello, world"
(gdb)