词嵌入
前面讲了循环神经网络做简单的图像分类问题和飞机流量时序预测,但是现在循环神经网络最火热的应用是自然语言处理,下面我们介绍一下自然语言处理中如果运用循环神经网络,首先我们介绍一下第一个概念,词嵌入。
对于图像分类问题,我们可以使用 one-hot 的类型去编码,比如一共有 5 类,那么属于第二类就可以用 (0, 1, 0, 0, 0) 去表示,对于分类问题,这样当然忒别简单,但是在自然语言处理中,因为单词的数目过多,这样做就行不通了,比如有 10000 个不同的词,那么使用 one-hot 不仅效率低,同时还没有办法表达出单词的特点,这个时候就引入了词嵌入去表达每一个单词。
词向量简单来说就是用一个向量去表示一个词语,但是这个向量并不是随机的,因为这样并没有任何意义,所以我们需要对每个词有一个特定的向量去表示他们,而有一些词的词性是相近的,比如”(love)喜欢”和”(like)爱”,对于这种词性相近的词,我们需要他们的向量表示也能够相近,如何去度量和定义向量之间的相近呢?非常简单,就是使用两个向量的夹角,夹角越小,越相近,这样就有了一个完备的定义。
我们举一个例子,下面有 4 段话
The cat likes playing wool.
The kitty likes playing wool.
The dog likes playing ball.
The boy does not like playing ball or wool.
这里面有 4 个词,分别是 cat, kitty, dog 和 boy。下面我们使用一个二维的词向量 (a, b) 来表示每一个词,其中 a,b 分别代表着这个词的一种属性,比如 a 代表是否喜欢玩球,b 代表是否喜欢玩毛线,数值越大表示越喜欢,那么我们就能够用数值来定义每一个单词。
对于 cat,我们可以定义它的词嵌入为 (-1, 4),因为他不喜欢玩球,喜欢玩毛线,同时可以定义 kitty 为 (-2, 5),dog 为 (3, 2) 以及 boy 为 (-2, -3),那么把这四个向量在坐标系中表示出来,就是

可以看到,上面这张图就显示了不同词嵌入之间的夹角,kitty 和 cat 之间的夹角比较小,所以他们更相似,dog 和 boy 之间的夹角很大,所以他们是不相似的。
下面我们看看 pytorch 中如何调用词向量
PyTorch 实现
词嵌入在 pytorch 中非常简单,只需要调用 torch.nn.Embedding(m, n) 就可以了,m 表示单词的总数目,n 表示词嵌入的维度,其实词嵌入就相当于是一个大矩阵,矩阵的每一行表示一个单词
import torch
from torch import nn
from torch.autograd import Variable
# 定义词嵌入
embeds = nn.Embedding(2, 5) # 2 个单词,维度 5
# 得到词嵌入矩阵
embeds.weight
Parameter containing:
-1.3426 0.7316 -0.2437 0.4925 -0.0191
-0.8326 0.3367 0.2135 0.5059 0.8326
[torch.FloatTensor of size 2x5]
我们通过 weight 得到了整个词嵌入的矩阵,注意,这个矩阵是一个可以改变的 parameter,在网络的训练中会不断更新,同时词嵌入的数值可以直接进行修改,比如我们可以读入一个预训练好的词嵌入等等
# 直接手动修改词嵌入的值
embeds.weight.data = torch.ones(2, 5)
embeds.weight
Parameter containing:
1 1 1 1 1
1 1 1 1 1
[torch.FloatTensor of size 2x5]
# 访问第 50 个词的词向量
embeds = nn.Embedding(100, 10)
single_word_embed = embeds(Variable(torch.LongTensor([50])))
single_word_embed
Variable containing:
-1.4954 -1.8475 0.2913 -0.9674 -2.1250 -0.5783 -0.6717 0.5638 0.7038 0.4437
[torch.FloatTensor of size 1x10]
可以看到如果我们要访问其中一个单词的词向量,我们可以直接调用定义好的词嵌入,但是输入必须传入一个 Variable,且类型是 LongTensor
虽然我们知道了如何定义词向量的相似性,但是我们仍然不知道如何得到词嵌入,因为如果一个词嵌入式 100 维,这显然不可能人为去赋值,所以为了得到词向量,需要介绍 skip-gram 模型。
Skip-Gram 模型
Skip Gram 模型是 Word2Vec 这篇论文的网络架构,下面我们来讲一讲这个模型。
模型结构
skip-gram 模型非常简单,我们在一段文本中训练一个简单的网络,这个网络的任务是通过一个词周围的词来预测这个词,然而我们实际上要做的就是训练我们的词嵌入。
比如我们给定一句话中的一个词,看看它周围的词,然后随机挑选一个,我们希望网络能够输出一个概率值,这个概率值能够告诉我们到底这个词离我们选择的词的远近程度,比如这么一句话 'A dog is playing with a ball',如果我们选的词是 'ball',那么 'playing' 就要比 'dog' 离我们选择的词更近。
对于一段话,我们可以按照顺序选择不同的词,然后构建训练样本和 label,比如
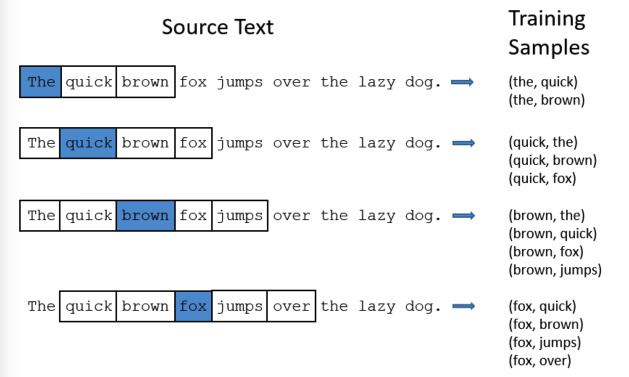
对于这个例子,我们依次取一个词以及其周围的词构成一个训练样本,比如第一次选择的词是 'the',那么我们取其前后两个词作为训练样本,这个也可以被称为一个滑动窗口,对于第一个词,其左边没有单词,所以训练集就是三个词,然后我们在这三个词中选择 'the' 作为输入,另外两个词都是他的输出,就构成了两个训练样本,又比如选择 'fox' 这个词,那么加上其左边两个词,右边两个词,一共是 5 个词,然后选择 'fox' 作为输入,那么输出就是其周围的四个词,一共可以构成 4 个训练样本,通过这个办法,我们就能够训练出需要的词嵌入。
下次课,我们会讲一讲词嵌入到底有什么用。