4.1 Regression with TensorFlow
import tensorflow as tf
print('TensorFlow:{}'.format(tf.__version__))
tf.set_random_seed(123)
import numpy as np
print('NumPy:{}'.format(np.__version__))
np.random.seed(123)
import matplotlib.pyplot as plt
import sklearn as sk
print('Scikit Learn:{}'.format(sk.__version__))
from sklearn import model_selection as skms
from sklearn import datasets as skds
from sklearn import preprocessing as skpp
TensorFlow:1.4.1
NumPy:1.13.1
Scikit Learn:0.19.1
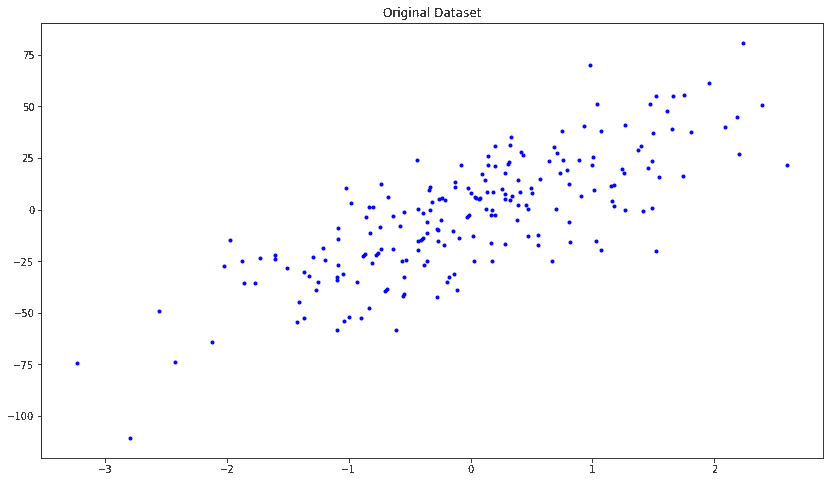
Generated Datasets
X, y = skds.make_regression(
n_samples=200, n_features=1, n_informative=1, n_targets=1, noise=20.0)
if (y.ndim == 1):
y = y.reshape(-1, 1)
plt.figure(figsize=(14,8))
plt.plot(X,y,'b.')
plt.title('Original Dataset')
plt.show()
X_train, X_test, y_train, y_test = skms.train_test_split(
X, y, test_size=.4, random_state=123)
num_outputs = y_train.shape[1]
num_inputs = X_train.shape[1]
x_tensor = tf.placeholder(dtype=tf.float32, shape=[None, num_inputs], name='x')
y_tensor = tf.placeholder(
dtype=tf.float32, shape=[None, num_outputs], name='y')
w = tf.Variable(
tf.zeros([num_inputs, num_outputs]), dtype=tf.float32, name='w')
b = tf.Variable(tf.zeros([num_outputs]), dtype=tf.float32, name='b')
model = tf.matmul(x_tensor, w) + b
loss = tf.reduce_mean(tf.square(model - y_tensor))
mse = tf.reduce_mean(tf.square(model - y_tensor))
y_mean = tf.reduce_mean(y_tensor)
total_error = tf.reduce_sum(tf.square(y_tensor - y_mean))
unexplained_error = tf.reduce_sum(tf.square(y_tensor - model))
rs = 1 - tf.div(unexplained_error, total_error)
learning_rate = 0.001
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)
num_epochs = 1500
w_hat = 0
b_hat = 0
loss_epochs = np.empty(shape=[num_epochs], dtype=np.float32)
mse_epochs = np.empty(shape=[num_epochs], dtype=np.float32)
rs_epochs = np.empty(shape=[num_epochs], dtype=np.float32)
mse_score = 0
rs_score = 0
with tf.Session() as tfs:
tfs.run(tf.global_variables_initializer())
for epoch in range(num_epochs):
feed_dict = {x_tensor: X_train, y_tensor: y_train}
loss_val, _ = tfs.run([loss, optimizer], feed_dict=feed_dict)
loss_epochs[epoch] = loss_val
feed_dict = {x_tensor: X_test, y_tensor: y_test}
mse_score, rs_score = tfs.run([mse, rs], feed_dict=feed_dict)
mse_epochs[epoch] = mse_score
rs_epochs[epoch] = rs_score
w_hat, b_hat = tfs.run([w, b])
w_hat = w_hat.reshape(1)
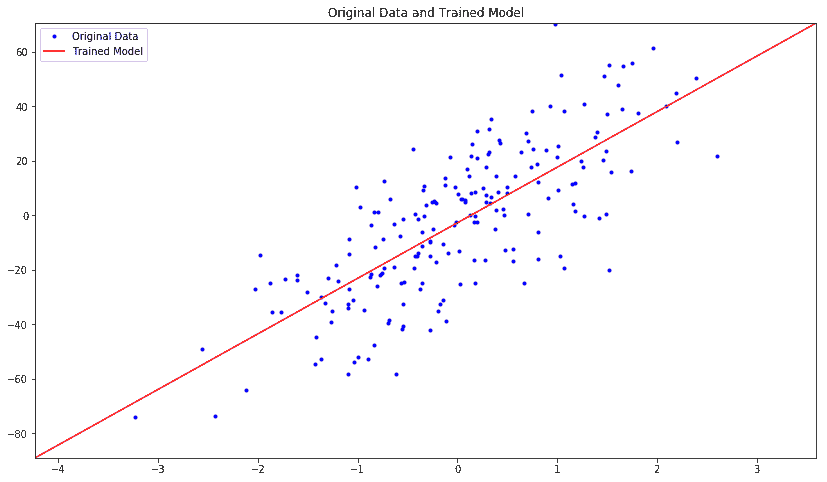
print('model : Y = {0:.8f} X + {1:.8f}'.format(w_hat[0], b_hat[0]))
print('For test data : MSE = {0:.8f}, R2 = {1:.8f} '.format(
mse_score, rs_score))
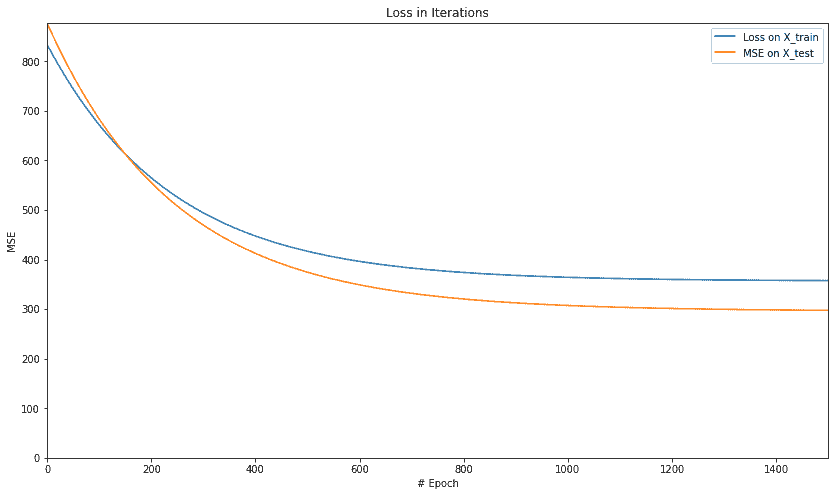
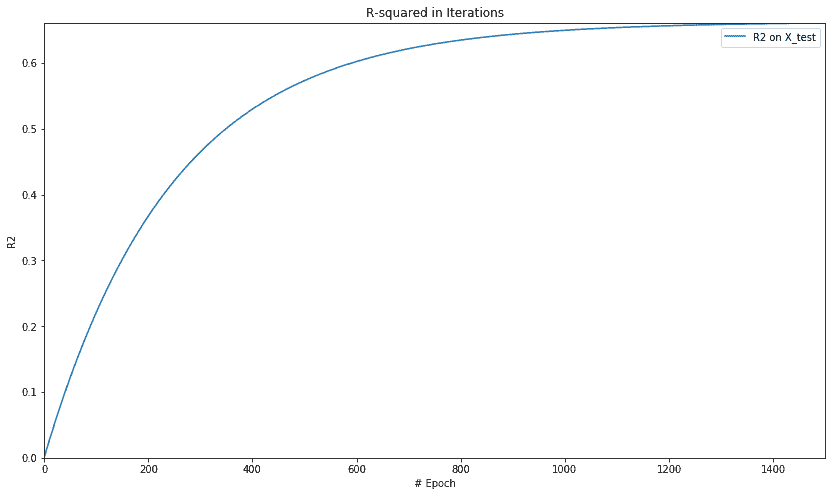
model : Y = 20.37448311 X + -2.75295663
For test data : MSE = 297.57989502, R2 = 0.66098374
plt.figure(figsize=(14, 8))
plt.title('Original Data and Trained Model')
x_plot = [np.min(X) - 1, np.max(X) + 1]
y_plot = w_hat * x_plot + b_hat
plt.axis([x_plot[0], x_plot[1], y_plot[0], y_plot[1]])
plt.plot(X, y, 'b.', label='Original Data')
plt.plot(x_plot, y_plot, 'r-', label='Trained Model')
plt.legend()
plt.show()
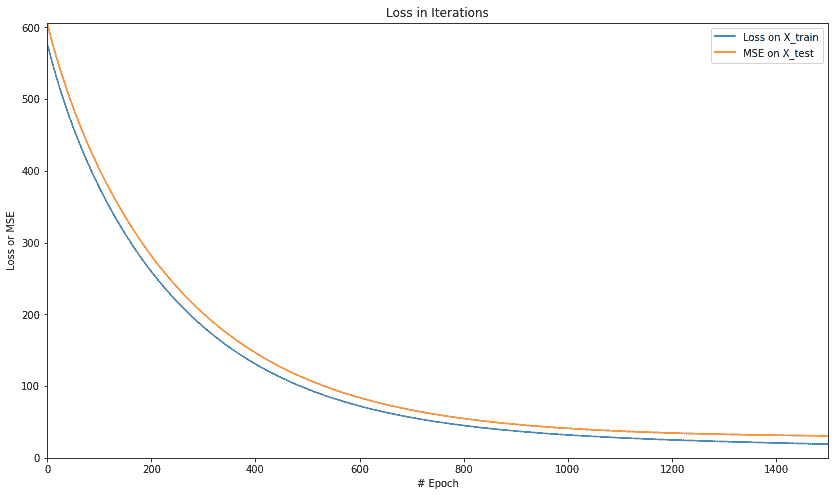
plt.figure(figsize=(14, 8))
plt.axis([0, num_epochs, 0, np.max(loss_epochs)])
plt.plot(loss_epochs, label='Loss on X_train')
plt.title('Loss in Iterations')
plt.xlabel('# Epoch')
plt.ylabel('MSE')
plt.axis([0, num_epochs, 0, np.max(mse_epochs)])
plt.plot(mse_epochs, label='MSE on X_test')
plt.xlabel('# Epoch')
plt.ylabel('MSE')
plt.legend()
plt.show()
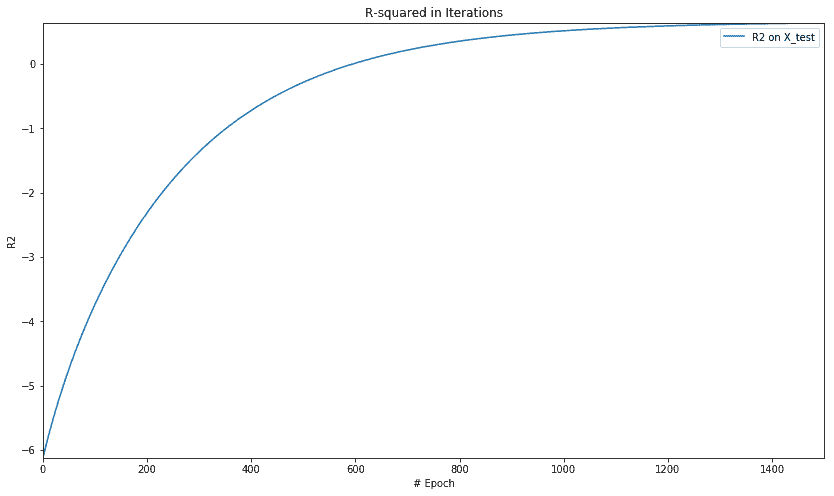
plt.figure(figsize=(14, 8))
plt.axis([0, num_epochs, np.min(rs_epochs), np.max(rs_epochs)])
plt.title('R-squared in Iterations')
plt.plot(rs_epochs, label='R2 on X_test')
plt.xlabel('# Epoch')
plt.ylabel('R2')
plt.legend()
plt.show()
Boston Dataset
boston=skds.load_boston()
print(boston.DESCR)
X=boston.data.astype(np.float32)
y=boston.target.astype(np.float32)
if (y.ndim == 1):
y = y.reshape(-1,1)
X = skpp.StandardScaler().fit_transform(X)
Boston House Prices dataset
===========================
Notes
------
Data Set Characteristics:
:Number of Instances: 506
:Number of Attributes: 13 numeric/categorical predictive
:Median Value (attribute 14) is usually the target
:Attribute Information (in order):
- CRIM per capita crime rate by town
- ZN proportion of residential land zoned for lots over 25,000 sq.ft.
- INDUS proportion of non-retail business acres per town
- CHAS Charles River dummy variable (= 1 if tract bounds river; 0 otherwise)
- NOX nitric oxides concentration (parts per 10 million)
- RM average number of rooms per dwelling
- AGE proportion of owner-occupied units built prior to 1940
- DIS weighted distances to five Boston employment centres
- RAD index of accessibility to radial highways
- TAX full-value property-tax rate per $10,000
- PTRATIO pupil-teacher ratio by town
- B 1000(Bk - 0.63)^2 where Bk is the proportion of blacks by town
- LSTAT % lower status of the population
- MEDV Median value of owner-occupied homes in $1000's
:Missing Attribute Values: None
:Creator: Harrison, D. and Rubinfeld, D.L.
This is a copy of UCI ML housing dataset.
http://archive.ics.uci.edu/ml/datasets/Housing
This dataset was taken from the StatLib library which is maintained at Carnegie Mellon University.
The Boston house-price data of Harrison, D. and Rubinfeld, D.L. 'Hedonic
prices and the demand for clean air', J. Environ. Economics & Management,
vol.5, 81-102, 1978. Used in Belsley, Kuh & Welsch, 'Regression diagnostics
...', Wiley, 1980. N.B. Various transformations are used in the table on
pages 244-261 of the latter.
The Boston house-price data has been used in many machine learning papers that address regression
problems.
**References**
- Belsley, Kuh & Welsch, 'Regression diagnostics: Identifying Influential Data and Sources of Collinearity', Wiley, 1980. 244-261.
- Quinlan,R. (1993). Combining Instance-Based and Model-Based Learning. In Proceedings on the Tenth International Conference of Machine Learning, 236-243, University of Massachusetts, Amherst. Morgan Kaufmann.
- many more! (see http://archive.ics.uci.edu/ml/datasets/Housing)
X_train, X_test, y_train, y_test = skms.train_test_split(
X, y, test_size=.4, random_state=123)
print(X_train.shape)
(303, 13)
Simple Multi Regression
num_outputs = y_train.shape[1]
num_inputs = X_train.shape[1]
x_tensor = tf.placeholder(dtype=tf.float32, shape=[None, num_inputs], name='x')
y_tensor = tf.placeholder(
dtype=tf.float32, shape=[None, num_outputs], name='y')
w = tf.Variable(
tf.zeros([num_inputs, num_outputs]), dtype=tf.float32, name='w')
b = tf.Variable(tf.zeros([num_outputs]), dtype=tf.float32, name='b')
model = tf.matmul(x_tensor, w) + b
loss = tf.reduce_mean(tf.square(model - y_tensor))
mse = tf.reduce_mean(tf.square(model - y_tensor))
y_mean = tf.reduce_mean(y_tensor)
total_error = tf.reduce_sum(tf.square(y_tensor - y_mean))
unexplained_error = tf.reduce_sum(tf.square(y_tensor - model))
rs = 1 - tf.div(unexplained_error, total_error)
learning_rate = 0.001
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)
num_epochs = 1500
loss_epochs = np.empty(shape=[num_epochs], dtype=np.float32)
mse_epochs = np.empty(shape=[num_epochs], dtype=np.float32)
rs_epochs = np.empty(shape=[num_epochs], dtype=np.float32)
mse_score = 0.0
rs_score = 0.0
with tf.Session() as tfs:
tfs.run(tf.global_variables_initializer())
for epoch in range(num_epochs):
feed_dict = {x_tensor: X_train, y_tensor: y_train}
loss_val, _ = tfs.run([loss, optimizer], feed_dict)
loss_epochs[epoch] = loss_val
feed_dict = {x_tensor: X_test, y_tensor: y_test}
mse_score, rs_score = tfs.run([mse, rs], feed_dict)
mse_epochs[epoch] = mse_score
rs_epochs[epoch] = rs_score
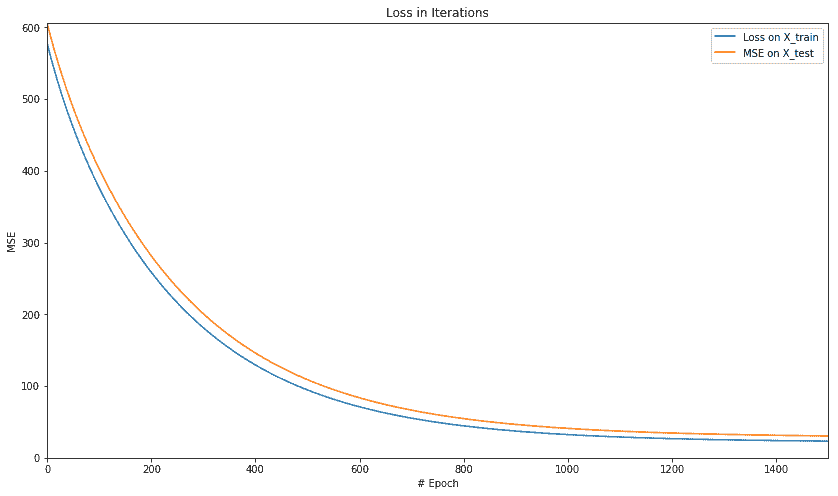
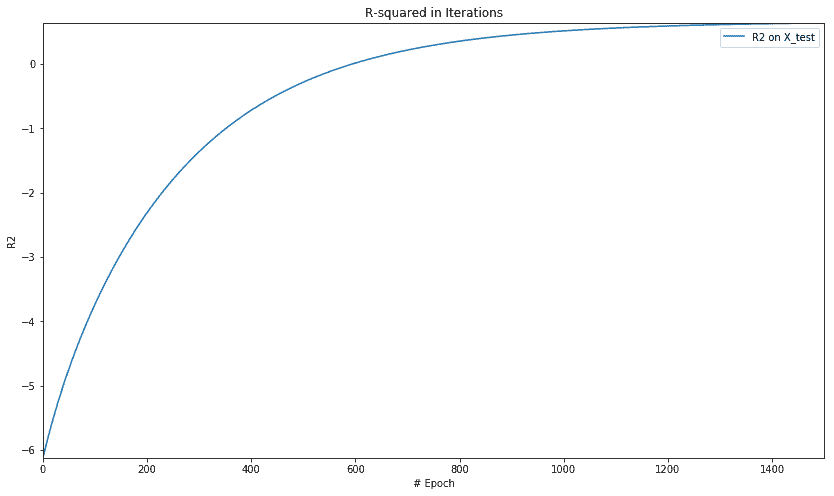
print('For test data : MSE = {0:.8f}, R2 = {1:.8f} '.format(
mse_score, rs_score))
For test data : MSE = 30.48501968, R2 = 0.64172244
plt.figure(figsize=(14, 8))
plt.axis([0, num_epochs, 0, np.max(loss_epochs)])
plt.plot(loss_epochs, label='Loss on X_train')
plt.title('Loss in Iterations')
plt.xlabel('# Epoch')
plt.ylabel('MSE')
plt.axis([0, num_epochs, 0, np.max(mse_epochs)])
plt.plot(mse_epochs, label='MSE on X_test')
plt.xlabel('# Epoch')
plt.ylabel('MSE')
plt.legend()
plt.show()
plt.figure(figsize=(14, 8))
plt.axis([0, num_epochs, np.min(rs_epochs), np.max(rs_epochs)])
plt.title('R-squared in Iterations')
plt.plot(rs_epochs, label='R2 on X_test')
plt.xlabel('# Epoch')
plt.ylabel('R2')
plt.legend()
plt.show()
Regularization
Lasso Regularlization
num_outputs = y_train.shape[1]
num_inputs = X_train.shape[1]
x_tensor = tf.placeholder(dtype=tf.float32,
shape=[None, num_inputs], name='x')
y_tensor = tf.placeholder(dtype=tf.float32,
shape=[None, num_outputs], name='y')
w = tf.Variable(tf.zeros([num_inputs, num_outputs]),
dtype=tf.float32, name='w')
b = tf.Variable(tf.zeros([num_outputs]),
dtype=tf.float32, name='b')
model = tf.matmul(x_tensor, w) + b
lasso_param = tf.Variable(0.8, dtype=tf.float32)
lasso_loss = tf.reduce_mean(tf.abs(w)) * lasso_param
loss = tf.reduce_mean(tf.square(model - y_tensor)) + lasso_loss
learning_rate = 0.001
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)
mse = tf.reduce_mean(tf.square(model - y_tensor))
y_mean = tf.reduce_mean(y_tensor)
total_error = tf.reduce_sum(tf.square(y_tensor - y_mean))
unexplained_error = tf.reduce_sum(tf.square(y_tensor - model))
rs = 1 - tf.div(unexplained_error, total_error)
num_epochs = 1500
loss_epochs = np.empty(shape=[num_epochs], dtype=np.float32)
mse_epochs = np.empty(shape=[num_epochs], dtype=np.float32)
rs_epochs = np.empty(shape=[num_epochs], dtype=np.float32)
mse_score = 0.0
rs_score = 0.0
with tf.Session() as tfs:
tfs.run(tf.global_variables_initializer())
for epoch in range(num_epochs):
feed_dict = {x_tensor: X_train, y_tensor: y_train}
loss_val,_ = tfs.run([loss,optimizer], feed_dict)
loss_epochs[epoch] = loss_val
feed_dict = {x_tensor: X_test, y_tensor: y_test}
mse_score,rs_score = tfs.run([mse,rs], feed_dict)
mse_epochs[epoch] = mse_score
rs_epochs[epoch] = rs_score
print('For test data : MSE = {0:.8f}, R2 = {1:.8f} '.format(
mse_score, rs_score))
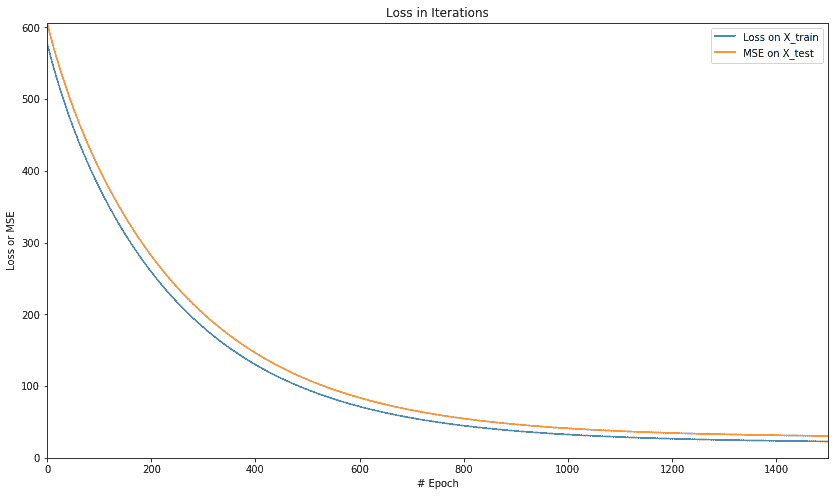
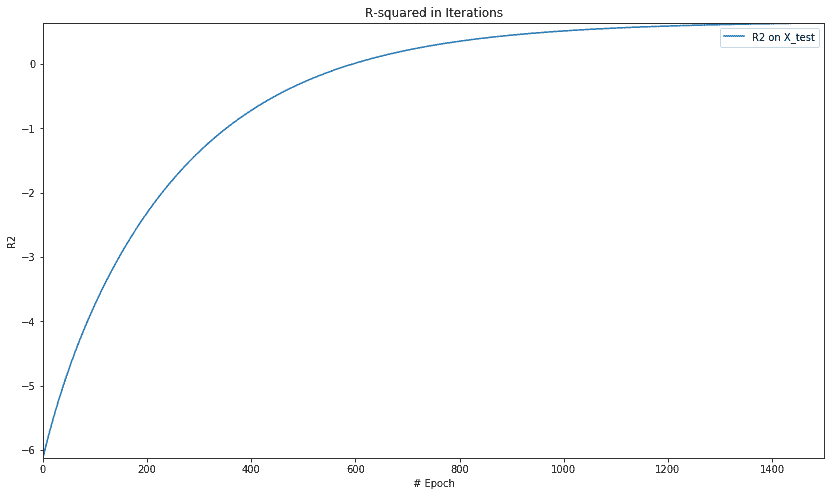
For test data : MSE = 30.48978233, R2 = 0.64166647
plt.figure(figsize=(14, 8))
plt.axis([0, num_epochs, 0, np.max([loss_epochs, mse_epochs])])
plt.plot(loss_epochs, label='Loss on X_train')
plt.plot(mse_epochs, label='MSE on X_test')
plt.title('Loss in Iterations')
plt.xlabel('# Epoch')
plt.ylabel('Loss or MSE')
plt.legend()
plt.show()
plt.figure(figsize=(14, 8))
plt.axis([0, num_epochs, np.min(rs_epochs), np.max(rs_epochs)])
plt.title('R-squared in Iterations')
plt.plot(rs_epochs, label='R2 on X_test')
plt.xlabel('# Epoch')
plt.ylabel('R2')
plt.legend()
plt.show()
Ridge Regularization
num_outputs = y_train.shape[1]
num_inputs = X_train.shape[1]
x_tensor = tf.placeholder(dtype=tf.float32,
shape=[None, num_inputs], name='x')
y_tensor = tf.placeholder(dtype=tf.float32,
shape=[None, num_outputs], name='y')
w = tf.Variable(tf.zeros([num_inputs, num_outputs]),
dtype=tf.float32, name='w')
b = tf.Variable(tf.zeros([num_outputs]),
dtype=tf.float32, name='b')
model = tf.matmul(x_tensor, w) + b
ridge_param = tf.Variable(0.8, dtype=tf.float32)
ridge_loss = tf.reduce_mean(tf.square(w)) * ridge_param
loss = tf.reduce_mean(tf.square(model - y_tensor)) + ridge_loss
learning_rate = 0.001
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)
mse = tf.reduce_mean(tf.square(model - y_tensor))
y_mean = tf.reduce_mean(y_tensor)
total_error = tf.reduce_sum(tf.square(y_tensor - y_mean))
unexplained_error = tf.reduce_sum(tf.square(y_tensor - model))
rs = 1 - tf.div(unexplained_error, total_error)
num_epochs = 1500
loss_epochs = np.empty(shape=[num_epochs], dtype=np.float32)
mse_epochs = np.empty(shape=[num_epochs], dtype=np.float32)
rs_epochs = np.empty(shape=[num_epochs], dtype=np.float32)
mse_score = 0.0
rs_score = 0.0
with tf.Session() as tfs:
tfs.run(tf.global_variables_initializer())
for epoch in range(num_epochs):
feed_dict = {x_tensor: X_train, y_tensor: y_train}
loss_val, _ = tfs.run([loss, optimizer], feed_dict=feed_dict)
loss_epochs[epoch] = loss_val
feed_dict = {x_tensor: X_test, y_tensor: y_test}
mse_score, rs_score = tfs.run([mse, rs], feed_dict=feed_dict)
mse_epochs[epoch] = mse_score
rs_epochs[epoch] = rs_score
print('For test data : MSE = {0:.8f}, R2 = {1:.8f} '.format(
mse_score, rs_score))
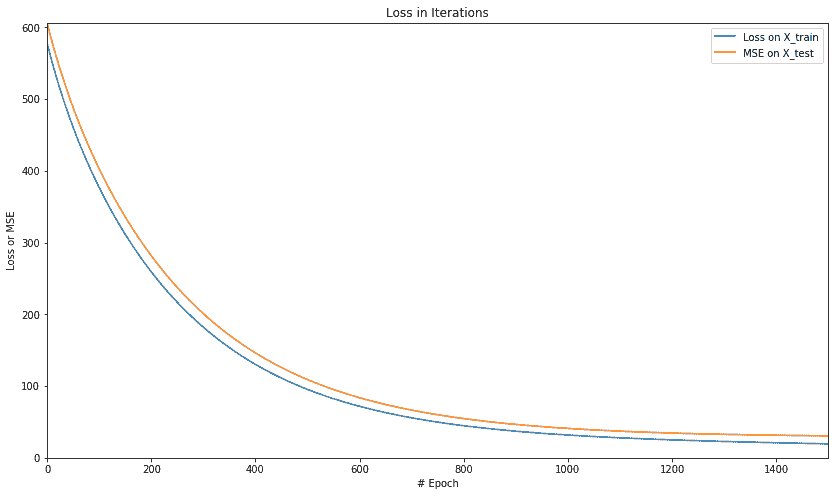
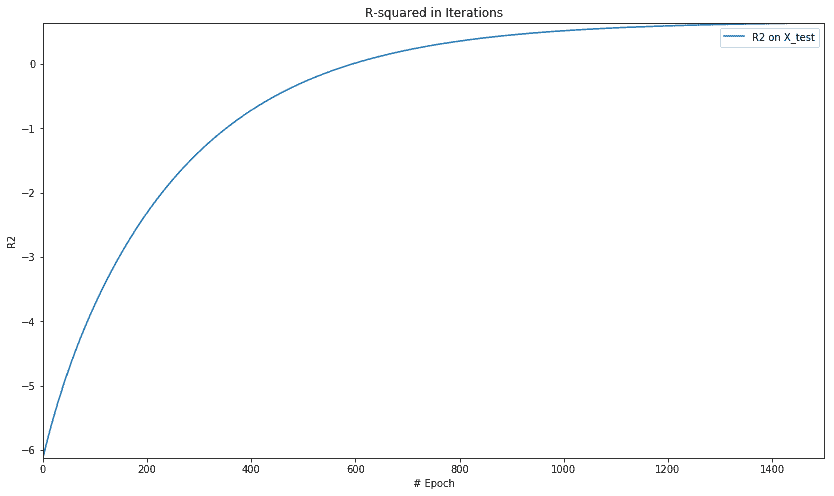
For test data : MSE = 30.64177513, R2 = 0.63988018
plt.figure(figsize=(14, 8))
plt.axis([0, num_epochs, 0, np.max([loss_epochs, mse_epochs])])
plt.plot(loss_epochs, label='Loss on X_train')
plt.plot(mse_epochs, label='MSE on X_test')
plt.title('Loss in Iterations')
plt.xlabel('# Epoch')
plt.ylabel('Loss or MSE')
plt.legend()
plt.show()
plt.figure(figsize=(14, 8))
plt.axis([0, num_epochs, np.min(rs_epochs), np.max(rs_epochs)])
plt.title('R-squared in Iterations')
plt.plot(rs_epochs, label='R2 on X_test')
plt.xlabel('# Epoch')
plt.ylabel('R2')
plt.legend()
plt.show()
ElasticNet Regularization
num_outputs = y_train.shape[1]
num_inputs = X_train.shape[1]
x_tensor = tf.placeholder(dtype=tf.float32,
shape=[None, num_inputs], name='x')
y_tensor = tf.placeholder(dtype=tf.float32,
shape=[None, num_outputs], name='y')
w = tf.Variable(tf.zeros([num_inputs, num_outputs]),
dtype=tf.float32, name='w')
b = tf.Variable(tf.zeros([num_outputs]),
dtype=tf.float32, name='b')
model = tf.matmul(x_tensor, w) + b
ridge_param = tf.Variable(0.8, dtype=tf.float32)
ridge_loss = tf.reduce_mean(tf.square(w)) * ridge_param
lasso_param = tf.Variable(0.8, dtype=tf.float32)
lasso_loss = tf.reduce_mean(tf.abs(w)) * lasso_param
loss = tf.reduce_mean(tf.square(model - y_tensor)) + \
ridge_loss + lasso_loss
learning_rate = 0.001
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)
mse = tf.reduce_mean(tf.square(model - y_tensor))
y_mean = tf.reduce_mean(y_tensor)
total_error = tf.reduce_sum(tf.square(y_tensor - y_mean))
unexplained_error = tf.reduce_sum(tf.square(y_tensor - model))
rs = 1 - tf.div(unexplained_error, total_error)
num_epochs = 1500
loss_epochs = np.empty(shape=[num_epochs], dtype=np.float32)
mse_epochs = np.empty(shape=[num_epochs], dtype=np.float32)
rs_epochs = np.empty(shape=[num_epochs], dtype=np.float32)
mse_score = 0.0
rs_score = 0.0
with tf.Session() as tfs:
tfs.run(tf.global_variables_initializer())
for epoch in range(num_epochs):
feed_dict = {x_tensor: X_train, y_tensor: y_train}
loss_val, _ = tfs.run([loss, optimizer], feed_dict=feed_dict)
loss_epochs[epoch] = loss_val
feed_dict = {x_tensor: X_test, y_tensor: y_test}
mse_score, rs_score = tfs.run([mse, rs], feed_dict=feed_dict)
mse_epochs[epoch] = mse_score
rs_epochs[epoch] = rs_score
print('For test data : MSE = {0:.8f}, R2 = {1:.8f} '.format(
mse_score, rs_score))
For test data : MSE = 30.64861488, R2 = 0.63979977
plt.figure(figsize=(14, 8))
plt.axis([0, num_epochs, 0, np.max([loss_epochs, mse_epochs])])
plt.plot(loss_epochs, label='Loss on X_train')
plt.plot(mse_epochs, label='MSE on X_test')
plt.title('Loss in Iterations')
plt.xlabel('# Epoch')
plt.ylabel('Loss or MSE')
plt.legend()
plt.show()
plt.figure(figsize=(14, 8))
plt.axis([0, num_epochs, np.min(rs_epochs), np.max(rs_epochs)])
plt.title('R-squared in Iterations')
plt.plot(rs_epochs, label='R2 on X_test')
plt.xlabel('# Epoch')
plt.ylabel('R2')
plt.legend()
plt.show()