8.1 Word Vectors and Embeddings in TensorFlow and Keras
import os
import numpy as np
np.random.seed(123)
print("NumPy:{}".format(np.__version__))
import matplotlib as mpl
import matplotlib.pyplot as plt
from matplotlib.pylab import rcParams
rcParams['figure.figsize']=15,10
print("Matplotlib:{}".format(mpl.__version__))
import tensorflow as tf
tf.set_random_seed(123)
print("TensorFlow:{}".format(tf.__version__))
NumPy:1.13.1
Matplotlib:2.1.0
TensorFlow:1.4.1
DATASETSLIB_HOME = os.path.join(os.path.expanduser('~'),'dl-ts','datasetslib')
import sys
if not DATASETSLIB_HOME in sys.path:
sys.path.append(DATASETSLIB_HOME)
%reload_ext autoreload
%autoreload 2
import datasetslib
from datasetslib import util as dsu
from datasetslib import nputil
datasetslib.datasets_root = os.path.join(os.path.expanduser('~'),'datasets')
Embeddings with PTB Data in TensorFlow
Load and Prepare PTB data
from datasetslib.ptb import PTBSimple
ptb = PTBSimple()
ptb.load_data()
print('Train :', ptb.part['train'][0:5])
print('Test: ', ptb.part['test'][0:5])
print('Valid: ', ptb.part['valid'][0:5])
print('Vocabulary Length = ', ptb.vocab_len)
Already exists: /home/armando/datasets/ptb-simple/simple-examples.tgz
Train : [9970 9971 9972 9974 9975]
Test: [102 14 24 32 752]
Valid: [1132 93 358 5 329]
Vocabulary Length = 10000
ptb.skip_window = 2
ptb.reset_index()
y_batch, x_batch = ptb.next_batch_cbow()
print('The CBOW pairs : context,target')
for i in range(5 * ptb.skip_window):
print('(', [ptb.id2word[x_i] for x_i in x_batch[i]],
',', y_batch[i], ptb.id2word[y_batch[i]], ')')
The CBOW pairs : context,target
( ['aer', 'banknote', 'calloway', 'centrust'] , 9972 berlitz )
( ['banknote', 'berlitz', 'centrust', 'cluett'] , 9974 calloway )
( ['berlitz', 'calloway', 'cluett', 'fromstein'] , 9975 centrust )
( ['calloway', 'centrust', 'fromstein', 'gitano'] , 9976 cluett )
( ['centrust', 'cluett', 'gitano', 'guterman'] , 9980 fromstein )
( ['cluett', 'fromstein', 'guterman', 'hydro-quebec'] , 9981 gitano )
( ['fromstein', 'gitano', 'hydro-quebec', 'ipo'] , 9982 guterman )
( ['gitano', 'guterman', 'ipo', 'kia'] , 9983 hydro-quebec )
( ['guterman', 'hydro-quebec', 'kia', 'memotec'] , 9984 ipo )
( ['hydro-quebec', 'ipo', 'memotec', 'mlx'] , 9986 kia )
ptb.skip_window = 2
ptb.reset_index()
x_batch, y_batch = ptb.next_batch_sg()
print('The skip-gram pairs : target,context')
for i in range(5 * ptb.skip_window):
print('(', x_batch[i], ptb.id2word[x_batch[i]],
',', y_batch[i], ptb.id2word[y_batch[i]], ')')
The skip-gram pairs : target,context
( 9972 berlitz , 9970 aer )
( 9972 berlitz , 9971 banknote )
( 9972 berlitz , 9974 calloway )
( 9972 berlitz , 9975 centrust )
( 9974 calloway , 9971 banknote )
( 9974 calloway , 9972 berlitz )
( 9974 calloway , 9975 centrust )
( 9974 calloway , 9976 cluett )
( 9975 centrust , 9972 berlitz )
( 9975 centrust , 9974 calloway )
valid_size = 8
x_valid = np.random.choice(valid_size * 10, valid_size, replace=False)
print('valid: ',x_valid)
valid: [64 58 59 4 69 53 31 77]
Train the skip-gram model for PTB Data in TensorFlow
batch_size = 128
embedding_size = 128
n_negative_samples = 64
ptb.skip_window=2
tf.reset_default_graph()
inputs = tf.placeholder(dtype=tf.int32, shape=[batch_size])
outputs = tf.placeholder(dtype=tf.int32, shape=[batch_size,1])
inputs_valid = tf.constant(x_valid, dtype=tf.int32)
embed_dist = tf.random_uniform(shape=[ptb.vocab_len, embedding_size],
minval=-1.0,
maxval=1.0
)
embed_matrix = tf.Variable(embed_dist,
name='embed_matrix'
)
embed_ltable = tf.nn.embedding_lookup(embed_matrix, inputs)
nce_dist = tf.truncated_normal(shape=[ptb.vocab_len, embedding_size],
stddev=1.0 /
tf.sqrt(embedding_size * 1.0)
)
nce_w = tf.Variable(nce_dist)
nce_b = tf.Variable(tf.zeros(shape=[ptb.vocab_len]))
loss = tf.reduce_mean(tf.nn.nce_loss(weights=nce_w,
biases=nce_b,
inputs=embed_ltable,
labels=outputs,
num_sampled=n_negative_samples,
num_classes=ptb.vocab_len
)
)
norm = tf.sqrt(tf.reduce_sum(tf.square(embed_matrix), 1,
keep_dims=True))
normalized_embeddings = embed_matrix / norm
embed_valid = tf.nn.embedding_lookup(normalized_embeddings,
inputs_valid)
similarity = tf.matmul(
embed_valid, normalized_embeddings, transpose_b=True)
n_epochs = 10
learning_rate = 0.9
n_batches = ptb.n_batches_wv()
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)
with tf.Session() as tfs:
tf.global_variables_initializer().run()
for epoch in range(n_epochs):
epoch_loss = 0
ptb.reset_index()
for step in range(n_batches):
x_batch, y_batch = ptb.next_batch_sg()
y_batch = nputil.to2d(y_batch, unit_axis=1)
feed_dict = {inputs: x_batch, outputs: y_batch}
_, batch_loss = tfs.run([optimizer, loss], feed_dict=feed_dict)
epoch_loss += batch_loss
epoch_loss = epoch_loss / n_batches
print('\nAverage loss after epoch ', epoch, ': ', epoch_loss)
similarity_scores = tfs.run(similarity)
top_k = 5
for i in range(valid_size):
similar_words = (-similarity_scores[i, :]
).argsort()[1:top_k + 1]
similar_str = 'Similar to {0:}:'.format(
ptb.id2word[x_valid[i]])
for k in range(top_k):
similar_str = '{0:} {1:},'.format(
similar_str, ptb.id2word[similar_words[k]])
print(similar_str)
final_embeddings = tfs.run(normalized_embeddings)
Average loss after epoch 0 : 114.686313165
Similar to we: japanese, premium, designer, whose, 's,
Similar to been: ', exports, plot, of, week,
Similar to also: country, types, or, ltd., spent,
Similar to of: are, $, own, stiff, u.s.,
Similar to last: satisfy, to, by, purchasing, paid,
Similar to u.s.: had, fact, of, under, before,
Similar to an: <unk>, country, members, stock, so,
Similar to trading: see, around, came, seeking, $,
Average loss after epoch 1 : 48.5942172454
Similar to we: details, japanese, designer, whose, premium,
Similar to been: ', exports, week, plot, english,
Similar to also: types, country, squeezed, ltd., spent,
Similar to of: are, stiff, $, utilities, effectively,
Similar to last: portugal, americans, satisfy, fans, one,
Similar to u.s.: had, fact, sooner, under, before,
Similar to an: <unk>, members, consider, country, billions,
Similar to trading: came, see, around, receiving, seeking,
Average loss after epoch 2 : 28.3028867856
Similar to we: details, japanese, whose, designer, premium,
Similar to been: plot, exports, week, ', accumulated,
Similar to also: types, squeezed, country, ltd., recorded,
Similar to of: stiff, are, utilities, $, effectively,
Similar to last: portugal, americans, fans, satisfy, faces,
Similar to u.s.: sooner, fact, had, under, fixed-rate,
Similar to an: consider, members, <unk>, billions, news,
Similar to trading: receiving, came, see, around, seeking,
Average loss after epoch 3 : 19.2299379783
Similar to we: details, whose, premium, designer, competition,
Similar to been: plot, exports, week, ', accumulated,
Similar to also: squeezed, types, country, ltd., recorded,
Similar to of: stiff, are, utilities, months, effectively,
Similar to last: portugal, americans, fans, faces, satisfy,
Similar to u.s.: sooner, fact, had, slowing, under,
Similar to an: consider, <unk>, members, gives, billions,
Similar to trading: receiving, came, see, around, we,
Average loss after epoch 4 : 13.9751931398
Similar to we: details, whose, premium, japanese, competition,
Similar to been: plot, exports, week, ', accumulated,
Similar to also: squeezed, types, country, ltd., recorded,
Similar to of: stiff, utilities, less, are, effectively,
Similar to last: portugal, fans, americans, faces, conduct,
Similar to u.s.: sooner, fact, had, fixed-rate, slowing,
Similar to an: consider, <unk>, members, gives, billions,
Similar to trading: receiving, came, see, around, seeking,
Average loss after epoch 5 : 11.1852364234
Similar to we: details, whose, premium, designer, competition,
Similar to been: plot, exports, week, ', accumulated,
Similar to also: squeezed, types, country, recorded, ltd.,
Similar to of: stiff, utilities, less, are, cutbacks,
Similar to last: portugal, fans, americans, faces, take,
Similar to u.s.: sooner, fact, had, fixed-rate, slowing,
Similar to an: consider, <unk>, members, gives, billions,
Similar to trading: receiving, came, around, see, seeking,
Average loss after epoch 6 : 8.20086761621
Similar to we: details, whose, premium, competition, designer,
Similar to been: plot, exports, week, accumulated, ',
Similar to also: squeezed, types, country, recorded, knowing,
Similar to of: stiff, utilities, less, effectively, cutbacks,
Similar to last: portugal, fans, faces, americans, take,
Similar to u.s.: fact, sooner, had, fixed-rate, slowing,
Similar to an: <unk>, consider, members, gives, billions,
Similar to trading: receiving, came, around, see, seeking,
Average loss after epoch 7 : 7.39699991544
Similar to we: details, whose, premium, designer, competition,
Similar to been: plot, exports, week, ', accumulated,
Similar to also: squeezed, types, country, knowing, recorded,
Similar to of: stiff, less, utilities, effectively, cutbacks,
Similar to last: portugal, fans, faces, americans, take,
Similar to u.s.: fact, sooner, had, fixed-rate, slowing,
Similar to an: <unk>, consider, gives, members, billions,
Similar to trading: receiving, came, around, see, settled,
Average loss after epoch 8 : 6.29247701856
Similar to we: details, whose, premium, competition, designer,
Similar to been: plot, exports, week, e., accumulated,
Similar to also: squeezed, types, country, recorded, knowing,
Similar to of: stiff, utilities, less, effectively, cutbacks,
Similar to last: portugal, fans, faces, take, americans,
Similar to u.s.: fact, sooner, had, fixed-rate, slowing,
Similar to an: consider, <unk>, gives, members, f.,
Similar to trading: receiving, came, around, see, separate,
Average loss after epoch 9 : 5.51221719766
Similar to we: details, whose, premium, disclosed, competition,
Similar to been: plot, accumulated, e., exports, week,
Similar to also: squeezed, recorded, types, country, knowing,
Similar to of: stiff, less, utilities, effectively, cutbacks,
Similar to last: portugal, fans, faces, take, americans,
Similar to u.s.: fact, sooner, had, fixed-rate, slowing,
Similar to an: consider, gives, members, f., billions,
Similar to trading: receiving, came, around, see, separate,
n_epochs = 5000
learning_rate = 0.9
n_batches = ptb.n_batches_wv()
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)
with tf.Session() as tfs:
tfs.run(tf.global_variables_initializer())
epoch_loss = 0
for epoch in range(n_epochs):
epoch_loss = 0
ptb.reset_index()
for step in range(n_batches):
x_batch, y_batch = ptb.next_batch_sg()
y_batch = nputil.to2d(y_batch, unit_axis=1)
feed_dict = {inputs: x_batch, outputs: y_batch}
_, batch_loss = tfs.run([optimizer, loss], feed_dict=feed_dict)
epoch_loss += batch_loss
epoch_loss = epoch_loss / n_batches
if epoch + 1 % 1000 == 0:
print('epoch done: ', epoch)
print('\nAverage loss after epoch ', epoch, ': ', epoch_loss)
similarity_scores = tfs.run(similarity)
top_k = 5
for i in range(valid_size):
similar_words = (-similarity_scores[i, :]).argsort()[1:top_k + 1]
similar_str = 'Similar to {0:}:'.format(ptb.id2word[x_valid[i]])
for k in range(top_k):
similar_str = '{0:} {1:},'.format(
similar_str, ptb.id2word[similar_words[k]])
print(similar_str)
final_embeddings = tfs.run(normalized_embeddings)
Average loss after epoch 4999 : 2.76887808091
Similar to we: champagne, permanent, she, over-the-counter, weeks,
Similar to been: precedent, deemed, visit, duty-free, conference,
Similar to also: attention, introduce, argue, index, extremely,
Similar to of: providing, grace, instruments, N, t.,
Similar to last: donoghue, agreed, march, swing, chief,
Similar to u.s.: automobile, fannie, soul, success, classified,
Similar to an: authority, outlawed, donaldson, stepping, eligible,
Similar to trading: money, boston, plus, uses, N,
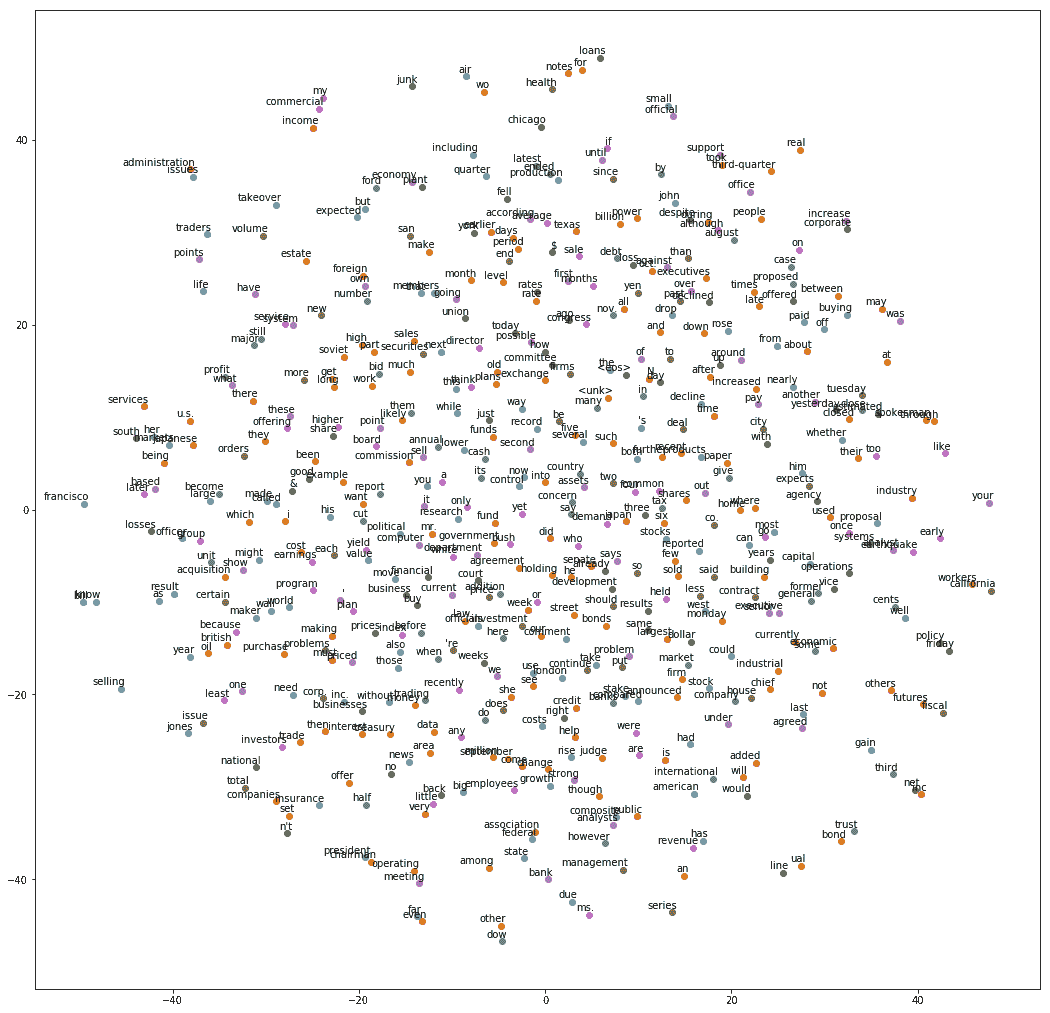
def plot_with_labels(low_dim_embs, labels):
assert low_dim_embs.shape[0] >= len(
labels), 'More labels than embeddings'
plt.figure(figsize=(18, 18))
for i, label in enumerate(labels):
x, y = low_dim_embs[i, :]
plt.scatter(x, y)
plt.annotate(label,
xy=(x, y),
xytext=(5, 2),
textcoords='offset points',
ha='right',
va='bottom')
plt.show()
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
tsne = TSNE(perplexity=30, n_components=2,
init='pca', n_iter=5000, method='exact')
n_embeddings = 500
low_dim_embeddings = tsne.fit_transform(final_embeddings[:n_embeddings, :])
labels = [ptb.id2word[i] for i in range(n_embeddings)]
plot_with_labels(low_dim_embeddings, labels)
Embeddings with Text8 data in TensorFlow
from datasetslib.text8 import Text8
text8 = Text8()
text8.load_data()
print('Train:', text8.part['train'][0:5])
print('Vocabulary Length = ', text8.vocab_len)
Already exists: /home/armando/datasets/text8/text8.zip
Train: [5233 3083 11 5 194]
Vocabulary Length = 253854
text8.skip_window = 2
text8.reset_index()
y_batch, x_batch = text8.next_batch_cbow()
print('The CBOW pairs : context,target')
for i in range(5 * text8.skip_window):
print('(', [text8.id2word[x_i] for x_i in x_batch[i]],
',', y_batch[i], text8.id2word[y_batch[i]], ')')
The CBOW pairs : context,target
( ['anarchism', 'originated', 'a', 'term'] , 11 as )
( ['originated', 'as', 'term', 'of'] , 5 a )
( ['as', 'a', 'of', 'abuse'] , 194 term )
( ['a', 'term', 'abuse', 'first'] , 1 of )
( ['term', 'of', 'first', 'used'] , 3133 abuse )
( ['of', 'abuse', 'used', 'against'] , 45 first )
( ['abuse', 'first', 'against', 'early'] , 58 used )
( ['first', 'used', 'early', 'working'] , 155 against )
( ['used', 'against', 'working', 'class'] , 127 early )
( ['against', 'early', 'class', 'radicals'] , 741 working )
text8.skip_window = 2
text8.reset_index()
x_batch, y_batch = text8.next_batch_sg()
print('The skip-gram pairs : target,context')
for i in range(5 * text8.skip_window):
print('(', x_batch[i], text8.id2word[x_batch[i]],
',', y_batch[i], text8.id2word[y_batch[i]], ')')
The skip-gram pairs : target,context
( 11 as , 5233 anarchism )
( 11 as , 3083 originated )
( 11 as , 5 a )
( 11 as , 194 term )
( 5 a , 3083 originated )
( 5 a , 11 as )
( 5 a , 194 term )
( 5 a , 1 of )
( 194 term , 11 as )
( 194 term , 5 a )
valid_size = 8
x_valid = np.random.choice(valid_size * 10, valid_size, replace=False)
print('valid: ',x_valid)
valid: [20 49 77 5 19 7 10 75]
batch_size = 128
embedding_size = 128
n_negative_samples = 64
text8.skip_window=2
tf.reset_default_graph()
inputs = tf.placeholder(dtype=tf.int32, shape=[batch_size])
outputs = tf.placeholder(dtype=tf.int32, shape=[batch_size,1])
inputs_valid = tf.constant(x_valid, dtype=tf.int32)
embed_matrix = tf.Variable(tf.random_uniform(shape=[text8.vocab_len, embedding_size],
minval = -1.0,
maxval = 1.0
),
name='embed_matrix'
)
embed_ltable = tf.nn.embedding_lookup(embed_matrix, inputs)
nce_w = tf.Variable(tf.truncated_normal(shape=[text8.vocab_len, embedding_size],
stddev=1.0 / tf.sqrt(embedding_size*1.0)
)
)
nce_b = tf.Variable(tf.zeros(shape=[text8.vocab_len]))
loss = tf.reduce_mean(tf.nn.nce_loss(weights=nce_w,
biases=nce_b,
inputs=embed_ltable,
labels=outputs,
num_sampled=n_negative_samples,
num_classes=text8.vocab_len
)
)
norm = tf.sqrt(tf.reduce_sum(tf.square(embed_matrix), 1, keep_dims=True))
normalized_embeddings = embed_matrix / norm
valid_embeddings = tf.nn.embedding_lookup(normalized_embeddings, inputs_valid)
similarity = tf.matmul(valid_embeddings, normalized_embeddings, transpose_b=True)
n_epochs = 50
learning_rate = 0.9
text8.reset_index()
n_batches = text8.n_batches_wv()
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)
with tf.Session() as tfs:
tf.global_variables_initializer().run()
for epoch in range(n_epochs):
epoch_loss = 0
for step in range(n_batches):
x_batch, y_batch = text8.next_batch_sg()
y_batch = nputil.to2d(y_batch,unit_axis=1)
feed_dict = {inputs: x_batch, outputs: y_batch}
_, batch_loss = tfs.run([optimizer, loss], feed_dict=feed_dict)
epoch_loss += batch_loss
epoch_loss = epoch_loss / n_batches
print('\nAverage loss after epoch ', epoch, ': ', epoch_loss)
similarity_scores = tfs.run(similarity)
for i in range(valid_size):
top_k = 5
similar_words = (-similarity_scores[i, :]).argsort()[1:top_k + 1]
similar_str = 'Similar to {0:}:'.format(text8.id2word[x_valid[i]])
for k in range(top_k):
similar_str = '{0:} {1:},'.format(similar_str, text8.id2word[similar_words[k]])
print(similar_str)
final_embeddings = tfs.run(normalized_embeddings)
Average loss after epoch 0 : 135.827208625
Similar to four: tissue, lechuguilla, straw, celsius, victoriae,
Similar to all: autistic, males, africa, gland, limited,
Similar to between: taxes, mormon, library, vivipara, declines,
Similar to a: the, carnival, of, lechuguilla, with,
Similar to that: leakey, basis, vivipara, but, staple,
Similar to zero: anna, launch, gland, two, one,
Similar to is: leadership, territories, parietal, taxes, and,
Similar to no: tissue, dagny, administration, ships, mirabilis,
Average loss after epoch 1 : 70.5671460077
Similar to four: one, zero, gb, eight, two,
Similar to all: gb, the, and, stronger, rotate,
Similar to between: two, devised, taxes, papyrus, newsgroup,
Similar to a: and, the, fam, gb, tissue,
Similar to that: leakey, but, altenberg, aesthetics, yum,
Similar to zero: one, altenberg, fam, phi, nine,
Similar to is: psi, hinder, territories, was, are,
Similar to no: altenberg, rotate, tissue, administration, ships,
Average loss after epoch 2 : 49.098458856
Similar to four: six, zero, three, five, one,
Similar to all: ameriko, hbox, gb, rotate, and,
Similar to between: levites, two, devised, abbates, ameriko,
Similar to a: the, ameriko, and, an, fam,
Similar to that: but, and, in, ameriko, vivipara,
Similar to zero: nine, eight, five, six, four,
Similar to is: was, are, psi, in, as,
Similar to no: altenberg, rotate, ameriko, abbates, sunda,
Average loss after epoch 3 : 36.9831544679
Similar to four: six, five, three, eight, dasyprocta,
Similar to all: operatorname, ameriko, gb, hbox, albuquerque,
Similar to between: and, in, operatorname, two, schmidt,
Similar to a: the, operatorname, his, and, or,
Similar to that: operatorname, with, but, and, it,
Similar to zero: two, three, five, four, nine,
Similar to is: was, are, as, with, dasyprocta,
Similar to no: operatorname, ameriko, altenberg, rotate, fam,
Average loss after epoch 4 : 28.6164453956
Similar to four: five, three, six, eight, two,
Similar to all: operatorname, ameriko, gb, lawsuits, many,
Similar to between: and, operatorname, schmidt, as, devised,
Similar to a: the, an, this, operatorname, or,
Similar to that: but, operatorname, it, which, this,
Similar to zero: eight, two, five, six, four,
Similar to is: was, are, operatorname, dasyprocta, as,
Similar to no: it, operatorname, ameriko, altenberg, rotate,
Average loss after epoch 5 : 22.323799798
Similar to four: six, three, five, two, eight,
Similar to all: the, operatorname, many, gb, three,
Similar to between: operatorname, in, schmidt, dasyprocta, with,
Similar to a: the, this, operatorname, an, or,
Similar to that: but, which, operatorname, with, it,
Similar to zero: three, eight, six, two, four,
Similar to is: was, are, operatorname, dasyprocta, as,
Similar to no: it, operatorname, ameriko, fam, altenberg,
Average loss after epoch 6 : 19.935355602
Similar to four: six, three, seven, five, two,
Similar to all: many, operatorname, trinomial, reuptake, cossa,
Similar to between: with, operatorname, schmidt, dasyprocta, in,
Similar to a: this, or, the, operatorname, an,
Similar to that: but, which, it, this, operatorname,
Similar to zero: eight, three, four, six, seven,
Similar to is: was, are, operatorname, dasyprocta, or,
Similar to no: it, a, operatorname, ameriko, but,
Average loss after epoch 7 : 16.9881831751
Similar to four: six, five, seven, two, three,
Similar to all: many, operatorname, trinomial, and, some,
Similar to between: with, in, eight, to, operatorname,
Similar to a: the, or, operatorname, this, an,
Similar to that: which, but, it, this, operatorname,
Similar to zero: eight, nine, five, dasyprocta, seven,
Similar to is: was, are, has, with, or,
Similar to no: it, a, this, operatorname, ameriko,
Average loss after epoch 8 : 14.2592270215
Similar to four: five, six, seven, eight, two,
Similar to all: albury, many, operatorname, some, trinomial,
Similar to between: with, in, albury, of, aveiro,
Similar to a: the, an, this, or, operatorname,
Similar to that: which, but, it, this, warshot,
Similar to zero: two, four, five, six, eight,
Similar to is: was, are, albury, operatorname, has,
Similar to no: it, this, but, albury, operatorname,
Average loss after epoch 9 : 13.0068666787
Similar to four: three, five, seven, six, eight,
Similar to all: many, albury, some, operatorname, trinomial,
Similar to between: with, recitative, in, albury, aveiro,
Similar to a: the, an, or, this, recitative,
Similar to that: which, but, this, and, it,
Similar to zero: five, four, eight, three, two,
Similar to is: was, are, has, operatorname, or,
Similar to no: this, kvac, it, but, albury,
Average loss after epoch 10 : 11.6051746191
Similar to four: three, five, six, seven, eight,
Similar to all: many, albury, some, operatorname, trinomial,
Similar to between: with, in, recitative, albury, to,
Similar to a: the, or, an, this, operatorname,
Similar to that: which, but, this, and, it,
Similar to zero: five, three, four, eight, two,
Similar to is: was, are, has, or, operatorname,
Similar to no: this, kvac, which, it, albury,
Average loss after epoch 11 : 10.6097498472
Similar to four: six, seven, three, five, eight,
Similar to all: many, some, albury, operatorname, trinomial,
Similar to between: with, in, recitative, and, albury,
Similar to a: the, an, or, this, operatorname,
Similar to that: which, but, this, it, however,
Similar to zero: six, eight, four, seven, five,
Similar to is: was, are, or, has, operatorname,
Similar to no: which, this, it, kvac, maritimequest,
Average loss after epoch 12 : 9.44573991087
Similar to four: six, three, two, five, seven,
Similar to all: many, some, albury, thibetanus, operatorname,
Similar to between: with, in, two, four, recitative,
Similar to a: an, the, this, operatorname, or,
Similar to that: which, this, but, it, however,
Similar to zero: eight, four, seven, five, six,
Similar to is: was, are, has, thibetanus, operatorname,
Similar to no: this, which, it, kvac, a,
Average loss after epoch 13 : 9.40504371293
Similar to four: six, five, three, seven, eight,
Similar to all: many, some, albury, these, thibetanus,
Similar to between: with, in, from, recitative, mastitis,
Similar to a: the, an, this, operatorname, recitative,
Similar to that: which, this, but, it, however,
Similar to zero: six, five, four, eight, three,
Similar to is: was, are, mastitis, has, operatorname,
Similar to no: this, kvac, which, it, any,
Average loss after epoch 14 : 8.97865626016
Similar to four: five, six, three, seven, eight,
Similar to all: many, some, these, albury, thibetanus,
Similar to between: with, in, recitative, mastitis, michelob,
Similar to a: the, an, this, operatorname, which,
Similar to that: which, but, this, michelob, when,
Similar to zero: six, five, three, four, seven,
Similar to is: was, are, has, mastitis, maritimequest,
Similar to no: this, which, it, a, kvac,
Average loss after epoch 15 : 8.14338739071
Similar to four: five, three, six, seven, eight,
Similar to all: some, many, these, albury, their,
Similar to between: with, in, from, recitative, mastitis,
Similar to a: the, an, operatorname, any, this,
Similar to that: which, but, this, michelob, however,
Similar to zero: five, six, seven, three, eight,
Similar to is: was, are, maritimequest, mastitis, operatorname,
Similar to no: this, which, any, it, kvac,
Average loss after epoch 16 : 8.31117789762
Similar to four: three, five, seven, six, eight,
Similar to all: some, many, these, albury, mitral,
Similar to between: with, in, mastitis, recitative, michelob,
Similar to a: the, an, this, or, any,
Similar to that: which, this, but, however, michelob,
Similar to zero: five, six, seven, eight, four,
Similar to is: was, are, has, operatorname, mastitis,
Similar to no: this, which, it, kvac, any,
Average loss after epoch 17 : 8.15239058717
Similar to four: six, five, three, seven, eight,
Similar to all: some, many, these, albury, both,
Similar to between: with, in, three, four, mastitis,
Similar to a: the, or, this, operatorname, which,
Similar to that: which, but, however, this, michelob,
Similar to zero: five, eight, four, six, seven,
Similar to is: was, are, has, mastitis, but,
Similar to no: this, which, kvac, a, any,
Average loss after epoch 18 : 7.46144762159
Similar to four: five, six, three, seven, eight,
Similar to all: some, many, both, these, albury,
Similar to between: with, in, from, michelob, three,
Similar to a: this, the, mastitis, an, recitative,
Similar to that: which, however, michelob, this, but,
Similar to zero: four, five, eight, six, seven,
Similar to is: was, are, has, mastitis, maritimequest,
Similar to no: this, which, any, only, kvac,
Average loss after epoch 19 : 8.29667459147
Similar to four: three, five, six, seven, two,
Similar to all: some, many, these, both, busan,
Similar to between: with, in, michelob, of, albury,
Similar to a: the, busan, or, escuela, this,
Similar to that: which, however, this, although, but,
Similar to zero: four, five, three, seven, six,
Similar to is: was, are, busan, mastitis, has,
Similar to no: this, which, any, it, only,
Average loss after epoch 20 : 7.73702917487
Similar to four: six, three, five, seven, eight,
Similar to all: some, many, both, these, busan,
Similar to between: with, in, from, five, michelob,
Similar to a: the, any, or, busan, this,
Similar to that: which, however, this, although, but,
Similar to zero: five, six, four, three, seven,
Similar to is: was, are, busan, has, but,
Similar to no: this, any, which, only, busan,
Average loss after epoch 21 : 7.53014415689
Similar to four: five, six, three, seven, eight,
Similar to all: some, many, both, these, busan,
Similar to between: with, from, in, michelob, against,
Similar to a: the, busan, any, this, operatorname,
Similar to that: which, however, this, although, michelob,
Similar to zero: four, six, three, five, eight,
Similar to is: was, are, busan, mastitis, operatorname,
Similar to no: this, which, any, only, a,
Average loss after epoch 22 : 7.39766837545
Similar to four: three, five, six, seven, zero,
Similar to all: some, many, both, these, busan,
Similar to between: with, in, from, michelob, against,
Similar to a: the, any, another, busan, this,
Similar to that: which, however, this, although, michelob,
Similar to zero: six, five, seven, four, eight,
Similar to is: was, are, busan, has, operatorname,
Similar to no: this, any, which, only, a,
Average loss after epoch 23 : 7.17782713765
Similar to four: six, three, five, seven, eight,
Similar to all: some, many, both, these, busan,
Similar to between: with, in, from, against, including,
Similar to a: the, any, busan, another, operatorname,
Similar to that: which, however, this, michelob, although,
Similar to zero: five, six, seven, three, four,
Similar to is: was, are, busan, has, operatorname,
Similar to no: this, which, any, only, busan,
Average loss after epoch 24 : 6.96806346772
Similar to four: five, three, six, seven, eight,
Similar to all: some, many, both, these, busan,
Similar to between: with, in, within, against, including,
Similar to a: the, any, busan, this, another,
Similar to that: which, however, although, this, but,
Similar to zero: five, seven, nine, three, eight,
Similar to is: was, are, has, mastitis, busan,
Similar to no: any, this, which, only, it,
Average loss after epoch 25 : 7.20916362865
Similar to four: five, three, six, seven, eight,
Similar to all: some, many, both, these, busan,
Similar to between: with, in, within, against, including,
Similar to a: the, any, another, busan, this,
Similar to that: which, however, although, this, but,
Similar to zero: five, eight, six, seven, three,
Similar to is: was, are, busan, has, operatorname,
Similar to no: this, any, only, which, however,
Average loss after epoch 26 : 6.98028469729
Similar to four: six, five, three, seven, eight,
Similar to all: some, many, both, these, several,
Similar to between: in, with, within, against, through,
Similar to a: the, any, another, busan, escuela,
Similar to that: which, however, this, michelob, but,
Similar to zero: five, two, four, six, busan,
Similar to is: was, are, busan, goldfinches, mastitis,
Similar to no: this, any, only, which, however,
Average loss after epoch 27 : 7.1013309475
Similar to four: five, six, three, seven, eight,
Similar to all: some, many, both, these, several,
Similar to between: with, within, in, from, against,
Similar to a: the, another, any, busan, michelob,
Similar to that: which, however, but, michelob, although,
Similar to zero: five, eight, six, seven, four,
Similar to is: was, are, has, busan, mastitis,
Similar to no: any, this, which, only, some,
Average loss after epoch 28 : 6.56530070452
Similar to four: five, six, three, seven, eight,
Similar to all: many, some, both, these, several,
Similar to between: with, within, in, against, both,
Similar to a: the, busan, another, any, operatorname,
Similar to that: which, however, although, but, this,
Similar to zero: five, busan, eight, four, seven,
Similar to is: was, are, busan, has, maritimequest,
Similar to no: any, this, only, however, capitols,
Average loss after epoch 29 : 6.91030734633
Similar to four: five, three, six, seven, eight,
Similar to all: many, some, both, these, busan,
Similar to between: with, within, both, against, through,
Similar to a: the, another, any, busan, escuela,
Similar to that: which, however, this, although, but,
Similar to zero: five, seven, four, eight, six,
Similar to is: was, are, has, busan, mastitis,
Similar to no: any, this, however, only, busan,
Average loss after epoch 30 : 6.98123962616
Similar to four: five, three, seven, six, eight,
Similar to all: many, some, these, both, several,
Similar to between: with, within, both, through, including,
Similar to a: another, the, any, busan, operatorname,
Similar to that: which, however, although, michelob, but,
Similar to zero: five, six, three, four, seven,
Similar to is: was, are, busan, has, mastitis,
Similar to no: any, this, however, only, which,
Average loss after epoch 31 : 7.09604787013
Similar to four: five, three, six, seven, eight,
Similar to all: many, some, both, these, several,
Similar to between: with, within, in, against, both,
Similar to a: the, another, any, busan, this,
Similar to that: which, however, this, although, michelob,
Similar to zero: five, eight, six, seven, four,
Similar to is: was, are, busan, has, mastitis,
Similar to no: any, this, however, only, a,
Average loss after epoch 32 : 7.10583426788
Similar to four: three, five, six, seven, eight,
Similar to all: many, some, both, these, several,
Similar to between: with, in, within, both, against,
Similar to a: another, the, any, busan, this,
Similar to that: which, however, although, while, but,
Similar to zero: eight, five, seven, six, busan,
Similar to is: was, are, has, busan, mastitis,
Similar to no: any, flageolet, this, however, only,
Average loss after epoch 33 : 6.64034354781
Similar to four: three, five, six, seven, eight,
Similar to all: many, some, both, these, several,
Similar to between: with, within, both, through, in,
Similar to a: the, another, any, busan, flageolet,
Similar to that: which, however, although, when, this,
Similar to zero: seven, five, eight, six, four,
Similar to is: was, are, has, busan, flageolet,
Similar to no: any, however, only, this, a,
Average loss after epoch 34 : 6.56126955526
Similar to four: six, five, three, seven, two,
Similar to all: many, some, both, these, several,
Similar to between: with, both, within, in, through,
Similar to a: the, another, any, busan, flageolet,
Similar to that: which, however, but, michelob, although,
Similar to zero: five, six, nine, eight, busan,
Similar to is: was, are, has, busan, mastitis,
Similar to no: any, a, only, however, another,
Average loss after epoch 35 : 7.92612275317
Similar to four: five, three, six, seven, eight,
Similar to all: many, some, both, these, several,
Similar to between: with, within, through, both, in,
Similar to a: the, another, any, busan, flageolet,
Similar to that: which, however, but, although, when,
Similar to zero: six, five, eight, two, four,
Similar to is: was, has, are, flageolet, busan,
Similar to no: any, only, flageolet, another, busan,
Average loss after epoch 36 : 6.45455038394
Similar to four: three, five, six, seven, two,
Similar to all: some, many, both, these, several,
Similar to between: with, within, through, in, both,
Similar to a: another, any, the, busan, delphinus,
Similar to that: which, however, but, although, this,
Similar to zero: eight, five, two, three, seven,
Similar to is: was, are, has, busan, flageolet,
Similar to no: any, only, flageolet, another, this,
Average loss after epoch 37 : 6.14241628294
Similar to four: five, three, six, seven, eight,
Similar to all: many, some, both, these, several,
Similar to between: with, through, in, within, including,
Similar to a: another, any, the, busan, flageolet,
Similar to that: which, however, although, this, when,
Similar to zero: busan, five, operatorname, seven, eight,
Similar to is: was, are, has, became, being,
Similar to no: any, only, however, another, flageolet,
Average loss after epoch 38 : 6.53143913077
Similar to four: five, six, three, seven, eight,
Similar to all: many, some, both, these, several,
Similar to between: with, through, within, in, against,
Similar to a: the, another, any, flageolet, busan,
Similar to that: which, however, although, this, when,
Similar to zero: six, five, seven, eight, nine,
Similar to is: was, are, being, flageolet, busan,
Similar to no: any, only, however, flageolet, this,
Average loss after epoch 39 : 6.49590713705
Similar to four: six, three, five, seven, eight,
Similar to all: some, many, both, these, several,
Similar to between: with, within, through, in, michelob,
Similar to a: another, the, any, flageolet, busan,
Similar to that: which, however, although, stadtbahn, when,
Similar to zero: five, eight, six, four, seven,
Similar to is: was, are, busan, means, being,
Similar to no: any, only, however, flageolet, this,
Average loss after epoch 40 : 6.63014369181
Similar to four: three, six, five, seven, two,
Similar to all: many, some, both, these, mitral,
Similar to between: with, through, within, in, michelob,
Similar to a: another, the, any, busan, operatorname,
Similar to that: which, however, when, although, stadtbahn,
Similar to zero: six, five, three, nine, seven,
Similar to is: was, are, busan, flageolet, being,
Similar to no: any, only, however, flageolet, another,
Average loss after epoch 41 : 6.07940426993
Similar to four: three, five, six, seven, eight,
Similar to all: many, some, both, these, several,
Similar to between: with, through, within, both, in,
Similar to a: another, the, any, busan, recitative,
Similar to that: which, however, although, stadtbahn, michelob,
Similar to zero: eight, five, seven, six, three,
Similar to is: was, are, flageolet, busan, means,
Similar to no: any, only, however, flageolet, another,
Average loss after epoch 42 : 6.15434198036
Similar to four: three, six, five, seven, eight,
Similar to all: many, some, both, various, these,
Similar to between: with, through, within, both, against,
Similar to a: another, the, any, busan, escuela,
Similar to that: which, however, although, stadtbahn, this,
Similar to zero: five, eight, six, seven, four,
Similar to is: was, are, became, flageolet, busan,
Similar to no: any, however, another, flageolet, only,
Average loss after epoch 43 : 6.21358637983
Similar to four: five, three, six, seven, two,
Similar to all: many, some, both, various, these,
Similar to between: with, within, through, in, against,
Similar to a: another, any, each, busan, the,
Similar to that: which, although, however, stadtbahn, this,
Similar to zero: five, four, seven, six, three,
Similar to is: was, are, busan, flageolet, means,
Similar to no: any, another, however, flageolet, only,
Average loss after epoch 44 : 6.07638619821
Similar to four: three, five, six, seven, eight,
Similar to all: many, some, both, various, these,
Similar to between: with, within, through, in, michelob,
Similar to a: another, the, any, flageolet, busan,
Similar to that: which, however, this, although, when,
Similar to zero: five, seven, three, eight, four,
Similar to is: was, are, has, busan, means,
Similar to no: any, another, flageolet, however, a,
Average loss after epoch 45 : 6.27363892372
Similar to four: six, five, three, seven, eight,
Similar to all: many, some, both, various, these,
Similar to between: with, through, within, in, both,
Similar to a: another, the, busan, any, flageolet,
Similar to that: which, however, stadtbahn, when, although,
Similar to zero: five, six, seven, four, eight,
Similar to is: was, are, flageolet, busan, means,
Similar to no: any, another, however, flageolet, this,
Average loss after epoch 46 : 6.08334335464
Similar to four: six, five, seven, three, eight,
Similar to all: many, some, both, various, these,
Similar to between: with, through, within, in, michelob,
Similar to a: another, the, any, busan, flageolet,
Similar to that: which, however, stadtbahn, although, when,
Similar to zero: five, eight, four, seven, busan,
Similar to is: was, are, means, busan, flageolet,
Similar to no: any, however, another, only, flageolet,
Average loss after epoch 47 : 6.15437479108
Similar to four: six, three, busan, five, seven,
Similar to all: many, some, both, these, various,
Similar to between: with, through, within, in, michelob,
Similar to a: another, any, the, this, busan,
Similar to that: which, however, when, although, but,
Similar to zero: busan, eight, five, seven, dasyprocta,
Similar to is: was, are, busan, means, flageolet,
Similar to no: however, any, only, another, flageolet,
Average loss after epoch 48 : 6.31930629635
Similar to four: six, three, five, seven, eight,
Similar to all: many, some, both, these, various,
Similar to between: with, through, within, around, michelob,
Similar to a: another, the, any, this, busan,
Similar to that: which, however, stadtbahn, although, michelob,
Similar to zero: five, seven, four, eight, three,
Similar to is: was, are, busan, being, flageolet,
Similar to no: any, only, another, however, flageolet,
Average loss after epoch 49 : 5.74088934757
Similar to four: six, five, three, eight, seven,
Similar to all: many, some, both, these, various,
Similar to between: with, within, through, in, around,
Similar to a: another, the, any, busan, delphinus,
Similar to that: which, however, although, but, stadtbahn,
Similar to zero: eight, six, seven, five, four,
Similar to is: was, are, being, busan, became,
Similar to no: any, another, however, flageolet, only,
def plot_with_words(low_dim_embeddings, words):
assert low_dim_embeddings.shape[0] >= len(words), 'More labels than embeddings'
plt.figure(figsize=(18, 18))
for i, words in enumerate(words):
x, y = low_dim_embeddings[i, :]
plt.scatter(x, y)
plt.annotate(words,
xy=(x, y),
xytext=(5, 2),
textcoords='offset points',
ha='right',
va='bottom')
plt.show()
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
tsne = TSNE(perplexity=30, n_components=2, init='pca', n_iter=5000, method='exact')
n_embeddings = 300
low_dim_embeddings = tsne.fit_transform(final_embeddings[:n_embeddings, :])
words = [text8.id2word[i] for i in range(n_embeddings)]
plot_with_words(low_dim_embeddings, words)

skip-gram model with Keras
from keras.models import Model
from keras.layers.embeddings import Embedding
from keras.preprocessing import sequence
from keras.layers import Input, Dense, Reshape, Dot, merge
import keras
Using TensorFlow backend.
tf.reset_default_graph()
keras.backend.clear_session()
valid_size = 8
x_valid = np.random.choice(valid_size * 10, valid_size, replace=False)
print('valid: ',x_valid)
valid: [55 49 64 69 53 23 32 42]
embedding_size = 512
n_negative_samples = 64
ptb.skip_window=2
sample_table = sequence.make_sampling_table(ptb.vocab_len)
pairs, labels= sequence.skipgrams(ptb.part['train'],
ptb.vocab_len,
window_size=ptb.skip_window,
sampling_table=sample_table)
print('The skip-gram pairs : target,context')
for i in range(5 * ptb.skip_window):
print(['{} {}'.format(id,ptb.id2word[id]) for id in pairs[i]],':',labels[i])
The skip-gram pairs : target,context
['9307 r', "9 's"] : 1
['253 very', '190 markets'] : 0
['4130 i.', '1365 store'] : 1
['3962 encouraging', '1017 continuing'] : 0
['842 kong', '9728 lancaster'] : 0
['186 revenue', '6398 elements'] : 0
['870 disclosed', "32 n't"] : 1
['9817 scheduling', '1311 backed'] : 0
['5659 enjoyed', '153 industry'] : 1
['9343 reruns', '4351 rebounded'] : 0
x,y=zip(*pairs)
x=np.array(x,dtype=np.int32)
x=nputil.to2d(x,unit_axis=1)
y=np.array(y,dtype=np.int32)
y=nputil.to2d(y,unit_axis=1)
labels=np.array(labels,dtype=np.int32)
labels=nputil.to2d(labels,unit_axis=1)
target_in = Input(shape=(1,),name='target_in')
target = Embedding(ptb.vocab_len,embedding_size,input_length=1,name='target_em')(target_in)
target = Reshape((embedding_size,1),name='target_re')(target)
context_in = Input((1,),name='context_in')
context = Embedding(ptb.vocab_len,embedding_size,input_length=1,name='context_em')(context_in)
context = Reshape((embedding_size,1),name='context_re')(context)
output = Dot(axes=1,name='output_dot')([target,context])
output = Reshape((1,),name='output_re')(output)
output = Dense(1,activation='sigmoid',name='output_sig')(output)
model = Model(inputs=[target_in,context_in],outputs=output)
model.compile(loss='binary_crossentropy', optimizer='adam')
similarity = Dot(axes=0,normalize=True,name='sim_dot')([target,context])
similarity_model = Model(inputs=[target_in,context_in],outputs=similarity)
model.summary()
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
target_in (InputLayer) (None, 1) 0
__________________________________________________________________________________________________
context_in (InputLayer) (None, 1) 0
__________________________________________________________________________________________________
target_em (Embedding) (None, 1, 512) 5120000 target_in[0][0]
__________________________________________________________________________________________________
context_em (Embedding) (None, 1, 512) 5120000 context_in[0][0]
__________________________________________________________________________________________________
target_re (Reshape) (None, 512, 1) 0 target_em[0][0]
__________________________________________________________________________________________________
context_re (Reshape) (None, 512, 1) 0 context_em[0][0]
__________________________________________________________________________________________________
output_dot (Dot) (None, 1, 1) 0 target_re[0][0]
context_re[0][0]
__________________________________________________________________________________________________
output_re (Reshape) (None, 1) 0 output_dot[0][0]
__________________________________________________________________________________________________
output_sig (Dense) (None, 1) 2 output_re[0][0]
==================================================================================================
Total params: 10,240,002
Trainable params: 10,240,002
Non-trainable params: 0
__________________________________________________________________________________________________
n_epochs = 5
batch_size = 1024
model.fit([x,y],labels,batch_size=batch_size, epochs=n_epochs)
Epoch 1/5
1096180/1096180 [==============================] - 14s 13us/step - loss: 0.4492
Epoch 2/5
1096180/1096180 [==============================] - 14s 13us/step - loss: 0.2846
Epoch 3/5
1096180/1096180 [==============================] - 14s 13us/step - loss: 0.1079
Epoch 4/5
1096180/1096180 [==============================] - 14s 13us/step - loss: 0.0284
Epoch 5/5
1096180/1096180 [==============================] - 14s 13us/step - loss: 0.0213
<keras.callbacks.History at 0x7fcd8c3d9780>
top_k = 5
y_val = np.arange(ptb.vocab_len, dtype=np.int32)
y_val = nputil.to2d(y_val,unit_axis=1)
for i in range(valid_size):
x_val = np.full(shape=(ptb.vocab_len,1),fill_value=x_valid[i], dtype=np.int32)
similarity_scores = similarity_model.predict([x_val,y_val])
similarity_scores=similarity_scores.flatten()
similar_words = (-similarity_scores).argsort()[1:top_k + 1]
similar_str = 'Similar to {0:}:'.format(ptb.id2word[x_valid[i]])
for k in range(top_k):
similar_str = '{0:} {1:},'.format(similar_str, ptb.id2word[similar_words[k]])
print(similar_str)
Similar to than: N, a, $, than, million,
Similar to his: do, did, from, to, of,
Similar to we: not, 're, did, it, n't,
Similar to last: year, month, N, <eos>, a,
Similar to u.s.: to, <eos>, said, as, in,
Similar to mr.: machines, was, said, co., years,
Similar to n't: did, does, wo, comment, would,
Similar to would: be, that, n't, if, should,
word2vec or embeddings visualisation using TensorBoard
tf.reset_default_graph()
from tensorflow.contrib.tensorboard.plugins import projector
batch_size = 128
embedding_size = 128
n_negative_samples = 64
ptb.skip_window=2
inputs = tf.placeholder(dtype=tf.int32, shape=[batch_size],name='inputs')
outputs = tf.placeholder(dtype=tf.int32, shape=[batch_size,1],name='outputs')
inputs_valid = tf.constant(x_valid, dtype=tf.int32,name='inputs_valid')
embed_matrix = tf.Variable(tf.random_uniform(shape=[ptb.vocab_len, embedding_size],
minval = -1.0,
maxval = 1.0
),
name='embed_matrix'
)
embed_ltable = tf.nn.embedding_lookup(embed_matrix, inputs)
nce_w = tf.Variable(tf.truncated_normal(shape=[ptb.vocab_len, embedding_size],
stddev=1.0 / tf.sqrt(embedding_size*1.0)
),
name='nce_w'
)
nce_b = tf.Variable(tf.zeros(shape=[ptb.vocab_len]), name='nce_b')
loss = tf.reduce_mean(tf.nn.nce_loss(weights=nce_w,
biases=nce_b,
inputs=embed_ltable,
labels=outputs,
num_sampled=n_negative_samples,
num_classes=ptb.vocab_len
),
name='nce_loss'
)
norm = tf.sqrt(tf.reduce_sum(tf.square(embed_matrix), 1, keep_dims=True),name='norm')
normalized_embeddings = tf.divide(embed_matrix,norm,name='normalized_embeddings')
embed_valid = tf.nn.embedding_lookup(normalized_embeddings, inputs_valid)
similarity = tf.matmul(embed_valid, normalized_embeddings, transpose_b=True, name='similarity')
n_epochs = 10
learning_rate = 0.9
n_batches = ptb.n_batches_wv()
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)
log_dir = 'tflogs'
vocabfile = 'word2id.tsv'
ptb.save_word2id(os.path.join(log_dir, vocabfile))
tf.summary.scalar('epoch_loss_scalar',epoch_loss)
tf.summary.histogram('epoch_loss_histogram',epoch_loss)
merged = tf.summary.merge_all()
with tf.Session() as tfs:
saver = tf.train.Saver()
config=projector.ProjectorConfig()
embed_conf1 = config.embeddings.add()
embed_conf1.tensor_name = embed_matrix.name
embed_conf1.metadata_path = vocabfile
file_writer = tf.summary.FileWriter(log_dir,tfs.graph)
projector.visualize_embeddings(file_writer,config)
tf.global_variables_initializer().run()
for epoch in range(n_epochs):
epoch_loss = 0
ptb.reset_index()
for step in range(n_batches):
x_batch, y_batch = ptb.next_batch_sg()
y_batch = nputil.to2d(y_batch,unit_axis=1)
feed_dict = {inputs: x_batch, outputs: y_batch}
summary, _, batch_loss = tfs.run([merged, optimizer, loss], feed_dict=feed_dict)
epoch_loss += batch_loss
saver.save(tfs,
os.path.join(log_dir, 'model.ckpt'),
global_step = epoch * n_batches + step)
epoch_loss = epoch_loss / n_batches
file_writer.add_summary(summary,global_step = epoch * n_batches + step)
print('\nAverage loss after epoch ', epoch, ': ', epoch_loss)
similarity_scores = tfs.run(similarity)
top_k = 5
for i in range(valid_size):
similar_words = (-similarity_scores[i, :]).argsort()[1:top_k + 1]
similar_str = 'Similar to {0:}:'.format(ptb.id2word[x_valid[i]])
for k in range(top_k):
similar_str = '{0:} {1:},'.format(similar_str, ptb.id2word[similar_words[k]])
print(similar_str)
final_embeddings = tfs.run(normalized_embeddings)
Average loss after epoch 0 : 113.313765391
Similar to than: a, teams, president, years, here,
Similar to his: six, money, department, types, he,
Similar to we: made, spending, as, major, share,
Similar to last: dodge, into, appeals, to, london,
Similar to u.s.: <unk>, export, said, latest, noted,
Similar to mr.: will, miles, company, page, 's,
Similar to n't: managers, $, preferences, the, new,
Similar to would: york, portfolios, N, montedison, she,
Average loss after epoch 1 : 49.7409719626
Similar to than: teams, declines, president, a, here,
Similar to his: six, money, department, uses, types,
Similar to we: made, spending, major, as, share,
Similar to last: appeals, dodge, into, thing, believe,
Similar to u.s.: latest, export, <unk>, commerce, nonexecutive,
Similar to mr.: will, contractor, miles, spokesman, status,
Similar to n't: managers, preferences, $, investment, cutting,
Similar to would: york, factors, portfolios, city, montedison,
Average loss after epoch 2 : 28.4847692404
Similar to than: declines, teams, here, president, years,
Similar to his: six, money, department, uses, types,
Similar to we: made, spending, major, share, started,
Similar to last: appeals, dodge, into, believe, thing,
Similar to u.s.: latest, export, marks, described, nonexecutive,
Similar to mr.: will, status, contractor, miles, spokesman,
Similar to n't: managers, preferences, managing, cutting, investment,
Similar to would: factors, york, portfolios, concerns, city,
Average loss after epoch 3 : 19.1291707601
Similar to than: declines, teams, here, president, spinoff,
Similar to his: six, money, department, uses, caused,
Similar to we: made, spending, major, november, knowing,
Similar to last: appeals, believe, into, dodge, investor,
Similar to u.s.: latest, marks, export, described, nonexecutive,
Similar to mr.: will, status, contractor, miles, spokesman,
Similar to n't: managers, preferences, managing, cutting, investment,
Similar to would: factors, york, portfolios, concerns, survival,
Average loss after epoch 4 : 13.7645920408
Similar to than: declines, teams, here, president, snapped,
Similar to his: six, money, caused, department, uses,
Similar to we: made, major, spending, november, knowing,
Similar to last: appeals, believe, investor, dodge, into,
Similar to u.s.: marks, latest, export, described, labor,
Similar to mr.: status, will, contractor, miles, spokesman,
Similar to n't: managers, preferences, managing, cutting, stepping,
Similar to would: factors, york, portfolios, survival, concerns,
Average loss after epoch 5 : 10.4424061714
Similar to than: declines, teams, here, president, imbalances,
Similar to his: six, money, caused, department, gradual,
Similar to we: made, major, november, knowing, spending,
Similar to last: appeals, believe, investor, into, dodge,
Similar to u.s.: marks, latest, export, described, labor,
Similar to mr.: status, will, contractor, spokesman, miles,
Similar to n't: preferences, managers, managing, cutting, stepping,
Similar to would: factors, york, portfolios, survival, concerns,
Average loss after epoch 6 : 8.91055996907
Similar to than: declines, teams, here, president, snapped,
Similar to his: six, money, caused, department, gradual,
Similar to we: made, major, november, knowing, started,
Similar to last: appeals, believe, investor, into, thing,
Similar to u.s.: marks, labor, latest, export, described,
Similar to mr.: status, will, contractor, spokesman, engineers,
Similar to n't: preferences, managers, managing, cutting, stepping,
Similar to would: factors, survival, portfolios, york, city,
Average loss after epoch 7 : 6.77055571095
Similar to than: declines, teams, here, president, snapped,
Similar to his: six, caused, money, gradual, department,
Similar to we: made, november, major, knowing, started,
Similar to last: appeals, believe, investor, thing, into,
Similar to u.s.: marks, labor, latest, export, described,
Similar to mr.: status, contractor, will, spokesman, engineers,
Similar to n't: preferences, managers, managing, cutting, monetary,
Similar to would: factors, york, portfolios, survival, city,
Average loss after epoch 8 : 6.54217958068
Similar to than: declines, teams, here, president, snapped,
Similar to his: six, caused, money, gradual, department,
Similar to we: made, november, major, knowing, started,
Similar to last: appeals, believe, investor, thing, into,
Similar to u.s.: marks, labor, latest, described, image,
Similar to mr.: status, contractor, will, spokesman, engineers,
Similar to n't: preferences, managers, managing, monetary, cutting,
Similar to would: factors, portfolios, york, survival, city,
Average loss after epoch 9 : 5.45150865576
Similar to than: declines, teams, here, sharply, snapped,
Similar to his: six, caused, gradual, money, department,
Similar to we: made, november, major, started, knowing,
Similar to last: appeals, believe, investor, thing, into,
Similar to u.s.: marks, labor, latest, commerce, image,
Similar to mr.: status, contractor, spokesman, will, engineers,
Similar to n't: preferences, managers, managing, monetary, stepping,
Similar to would: factors, portfolios, survival, york, guterman,
The word2id and id2word code explained
import collections
counter=collections.Counter(['a','b','a','c','a','c'])
l=lambda x: (-x[1],x[0])
count_pairs=sorted(counter.items(),key=l)
words,_=list(zip(*count_pairs))
print(words)
word2id = dict(zip(words, range(len(words))))
print(word2id)
id2word = dict(zip(word2id.values(), word2id.keys()))
print(id2word)
('a', 'c', 'b')
{'c': 1, 'a': 0, 'b': 2}
{0: 'a', 1: 'c', 2: 'b'}