Convolutional Neural Network Example
Build a convolutional neural network with TensorFlow.
- Author: Aymeric Damien
- Project: https://github.com/aymericdamien/TensorFlow-Examples/
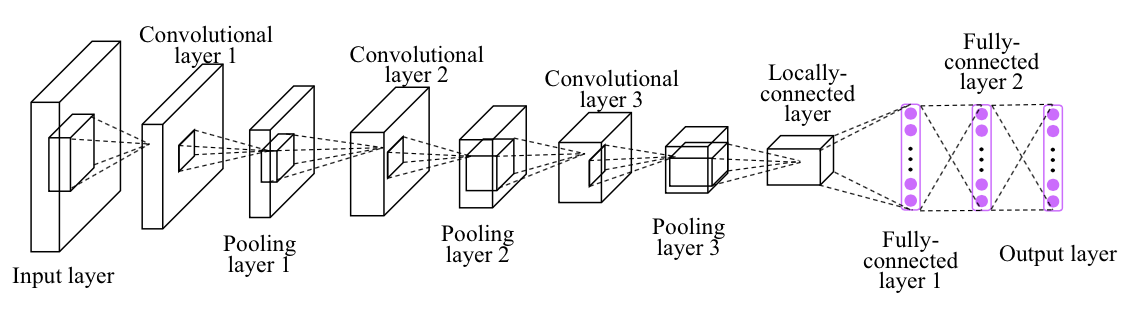
CNN Overview
MNIST Dataset Overview
This example is using MNIST handwritten digits. The dataset contains 60,000 examples for training and 10,000 examples for testing. The digits have been size-normalized and centered in a fixed-size image (28x28 pixels) with values from 0 to 1. For simplicity, each image has been flattened and converted to a 1-D numpy array of 784 features (28*28).

More info: http://yann.lecun.com/exdb/mnist/
from __future__ import division, print_function, absolute_import
import tensorflow as tf
# Import MNIST data
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot=True)
Extracting /tmp/data/train-images-idx3-ubyte.gz
Extracting /tmp/data/train-labels-idx1-ubyte.gz
Extracting /tmp/data/t10k-images-idx3-ubyte.gz
Extracting /tmp/data/t10k-labels-idx1-ubyte.gz
# Training Parameters
learning_rate = 0.001
num_steps = 500
batch_size = 128
display_step = 10
# Network Parameters
num_input = 784 # MNIST data input (img shape: 28*28)
num_classes = 10 # MNIST total classes (0-9 digits)
dropout = 0.75 # Dropout, probability to keep units
# tf Graph input
X = tf.placeholder(tf.float32, [None, num_input])
Y = tf.placeholder(tf.float32, [None, num_classes])
keep_prob = tf.placeholder(tf.float32) # dropout (keep probability)
# Create some wrappers for simplicity
def conv2d(x, W, b, strides=1):
# Conv2D wrapper, with bias and relu activation
x = tf.nn.conv2d(x, W, strides=[1, strides, strides, 1], padding='SAME')
x = tf.nn.bias_add(x, b)
return tf.nn.relu(x)
def maxpool2d(x, k=2):
# MaxPool2D wrapper
return tf.nn.max_pool(x, ksize=[1, k, k, 1], strides=[1, k, k, 1],
padding='SAME')
# Create model
def conv_net(x, weights, biases, dropout):
# MNIST data input is a 1-D vector of 784 features (28*28 pixels)
# Reshape to match picture format [Height x Width x Channel]
# Tensor input become 4-D: [Batch Size, Height, Width, Channel]
x = tf.reshape(x, shape=[-1, 28, 28, 1])
# Convolution Layer
conv1 = conv2d(x, weights['wc1'], biases['bc1'])
# Max Pooling (down-sampling)
conv1 = maxpool2d(conv1, k=2)
# Convolution Layer
conv2 = conv2d(conv1, weights['wc2'], biases['bc2'])
# Max Pooling (down-sampling)
conv2 = maxpool2d(conv2, k=2)
# Fully connected layer
# Reshape conv2 output to fit fully connected layer input
fc1 = tf.reshape(conv2, [-1, weights['wd1'].get_shape().as_list()[0]])
fc1 = tf.add(tf.matmul(fc1, weights['wd1']), biases['bd1'])
fc1 = tf.nn.relu(fc1)
# Apply Dropout
fc1 = tf.nn.dropout(fc1, dropout)
# Output, class prediction
out = tf.add(tf.matmul(fc1, weights['out']), biases['out'])
return out
# Store layers weight & bias
weights = {
# 5x5 conv, 1 input, 32 outputs
'wc1': tf.Variable(tf.random_normal([5, 5, 1, 32])),
# 5x5 conv, 32 inputs, 64 outputs
'wc2': tf.Variable(tf.random_normal([5, 5, 32, 64])),
# fully connected, 7*7*64 inputs, 1024 outputs
'wd1': tf.Variable(tf.random_normal([7*7*64, 1024])),
# 1024 inputs, 10 outputs (class prediction)
'out': tf.Variable(tf.random_normal([1024, num_classes]))
}
biases = {
'bc1': tf.Variable(tf.random_normal([32])),
'bc2': tf.Variable(tf.random_normal([64])),
'bd1': tf.Variable(tf.random_normal([1024])),
'out': tf.Variable(tf.random_normal([num_classes]))
}
# Construct model
logits = conv_net(X, weights, biases, keep_prob)
prediction = tf.nn.softmax(logits)
# Define loss and optimizer
loss_op = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(
logits=logits, labels=Y))
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
train_op = optimizer.minimize(loss_op)
# Evaluate model
correct_pred = tf.equal(tf.argmax(prediction, 1), tf.argmax(Y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
# Initialize the variables (i.e. assign their default value)
init = tf.global_variables_initializer()
# Start training
with tf.Session() as sess:
# Run the initializer
sess.run(init)
for step in range(1, num_steps+1):
batch_x, batch_y = mnist.train.next_batch(batch_size)
# Run optimization op (backprop)
sess.run(train_op, feed_dict={X: batch_x, Y: batch_y, keep_prob: dropout})
if step % display_step == 0 or step == 1:
# Calculate batch loss and accuracy
loss, acc = sess.run([loss_op, accuracy], feed_dict={X: batch_x,
Y: batch_y,
keep_prob: 1.0})
print("Step " + str(step) + ", Minibatch Loss= " + \
"{:.4f}".format(loss) + ", Training Accuracy= " + \
"{:.3f}".format(acc))
print("Optimization Finished!")
# Calculate accuracy for 256 MNIST test images
print("Testing Accuracy:", \
sess.run(accuracy, feed_dict={X: mnist.test.images[:256],
Y: mnist.test.labels[:256],
keep_prob: 1.0}))
Step 1, Minibatch Loss= 63763.3047, Training Accuracy= 0.141
Step 10, Minibatch Loss= 26429.6680, Training Accuracy= 0.242
Step 20, Minibatch Loss= 12171.8584, Training Accuracy= 0.586
Step 30, Minibatch Loss= 6306.6318, Training Accuracy= 0.734
Step 40, Minibatch Loss= 5113.7583, Training Accuracy= 0.711
Step 50, Minibatch Loss= 4022.2131, Training Accuracy= 0.805
Step 60, Minibatch Loss= 3125.4949, Training Accuracy= 0.867
Step 70, Minibatch Loss= 2225.4875, Training Accuracy= 0.875
Step 80, Minibatch Loss= 1843.3540, Training Accuracy= 0.867
Step 90, Minibatch Loss= 1715.7744, Training Accuracy= 0.875
Step 100, Minibatch Loss= 2611.2708, Training Accuracy= 0.906
Step 110, Minibatch Loss= 4804.0913, Training Accuracy= 0.875
Step 120, Minibatch Loss= 1067.5258, Training Accuracy= 0.938
Step 130, Minibatch Loss= 2519.1514, Training Accuracy= 0.898
Step 140, Minibatch Loss= 2687.9292, Training Accuracy= 0.906
Step 150, Minibatch Loss= 1983.4077, Training Accuracy= 0.938
Step 160, Minibatch Loss= 2844.6553, Training Accuracy= 0.930
Step 170, Minibatch Loss= 3602.2524, Training Accuracy= 0.914
Step 180, Minibatch Loss= 175.3922, Training Accuracy= 0.961
Step 190, Minibatch Loss= 645.1918, Training Accuracy= 0.945
Step 200, Minibatch Loss= 1147.6567, Training Accuracy= 0.938
Step 210, Minibatch Loss= 1140.4148, Training Accuracy= 0.914
Step 220, Minibatch Loss= 1572.8756, Training Accuracy= 0.906
Step 230, Minibatch Loss= 1292.9274, Training Accuracy= 0.898
Step 240, Minibatch Loss= 1501.4623, Training Accuracy= 0.953
Step 250, Minibatch Loss= 1908.2997, Training Accuracy= 0.898
Step 260, Minibatch Loss= 2182.2380, Training Accuracy= 0.898
Step 270, Minibatch Loss= 487.5807, Training Accuracy= 0.961
Step 280, Minibatch Loss= 1284.1130, Training Accuracy= 0.945
Step 290, Minibatch Loss= 1232.4919, Training Accuracy= 0.891
Step 300, Minibatch Loss= 1198.8336, Training Accuracy= 0.945
Step 310, Minibatch Loss= 2010.5345, Training Accuracy= 0.906
Step 320, Minibatch Loss= 786.3917, Training Accuracy= 0.945
Step 330, Minibatch Loss= 1408.3556, Training Accuracy= 0.898
Step 340, Minibatch Loss= 1453.7538, Training Accuracy= 0.953
Step 350, Minibatch Loss= 999.8901, Training Accuracy= 0.906
Step 360, Minibatch Loss= 914.3958, Training Accuracy= 0.961
Step 370, Minibatch Loss= 488.0052, Training Accuracy= 0.938
Step 380, Minibatch Loss= 1070.8710, Training Accuracy= 0.922
Step 390, Minibatch Loss= 151.4658, Training Accuracy= 0.961
Step 400, Minibatch Loss= 555.3539, Training Accuracy= 0.953
Step 410, Minibatch Loss= 765.5746, Training Accuracy= 0.945
Step 420, Minibatch Loss= 326.9393, Training Accuracy= 0.969
Step 430, Minibatch Loss= 530.8968, Training Accuracy= 0.977
Step 440, Minibatch Loss= 463.3909, Training Accuracy= 0.977
Step 450, Minibatch Loss= 362.2226, Training Accuracy= 0.977
Step 460, Minibatch Loss= 414.0034, Training Accuracy= 0.953
Step 470, Minibatch Loss= 583.4587, Training Accuracy= 0.945
Step 480, Minibatch Loss= 566.1262, Training Accuracy= 0.969
Step 490, Minibatch Loss= 691.1143, Training Accuracy= 0.961
Step 500, Minibatch Loss= 282.8893, Training Accuracy= 0.984
Optimization Finished!
Testing Accuracy: 0.976562