10.5.2 算法分析实例
本节以本章介绍的若干算法为例来讨论对算法复杂性的分析。
搜索问题的两个算法 对于搜索问题,本章介绍了线性搜索和二分搜索两个算法。
线性搜索算法的思想是逐个检查列表成员,编码时可以用一个循环语句来实现。循环体 的执行次数取决于列表长度:如果列表长度为 n,则循环体最多执行 n 次。因此,如果列表 长度增大一倍,则循环次数最多增加一倍,算法执行的步数或实际运行时间最多增加一倍。 可见,线性搜索算法在最坏情形下的运行时间与输入列表的大小 n 呈线性关系,即复杂度为 O(n),称为线性时间算法。
二分搜索算法的主体也是一个循环,但该循环不是逐个检查列表数据,而是每次检查位 于列表中点的数据,并根据该中点数据与要查找的数据的大小比较情况来排除掉左半列表或 右半列表。接着对保留下来的一半列表重复进行这个“折半”过程。显然,循环的次数取决 于输入列表能“折半”多少次。如果初始输入列表有 16 个数据,则第一轮循环后剩下 8 个数据,第二轮循环后剩下 4 个数据,第三轮后剩下 2 个,第四轮后只剩下 1 个数据。因此, 最多四轮循环后就能得出搜索结论:要么找到,要么不存在。一般地,如果输入规模为 n, 则二分搜索算法最多循环 log2n 次,即复杂度为 O(log2n),称为对数时间算法。要说明的是, O(log2n)表示复杂度与问题规模 n 的对数成正比,至于这个对数是以 2 为底还是以 10 为底并 不重要,因此我们经常省略对数的底,写成 O(log n)。
O(n)与 O(log n)到底有多大差别?回到 10.2 中提到的猜数游戏,假如某甲心中想好一个1百万以内的数让某乙来猜。某乙从小到大逐个试猜(即线性搜索)的话,运气好猜 1 次就能命中,运气不好最多要猜 1 百万次。平均来说需要猜 50 万次才能猜中。而如果某乙每次 猜中间数(即二分搜索)的话,则最少猜 1 次,最多也不过猜 log21000000≈20 次就能猜中。 可见,随着 n 的增大,O(log n)远远优于 O(n)。
排序问题的两个算法
对于排序问题,本章介绍了选择排序和归并排序两个算法。
首先推导选择排序算法的步数与问题规模(即数据列表的长度)的关系。选择排序算法 首先找出全体数据中的最小值,并将该值作为结果列表的第一个成员。其次,算法从剩余数 据中找出最小值,并将该值作为结果列表的第二个成员。依此类推,直至产生有序列表。假 设列表初始大小为 n,为找出最小值,算法需检查每一个数据。接下来算法从剩余 n-1 个数 据中找出最小值,这需要检查 n-1 个数据;第三次循环从 n-2 个剩余数据中找出最小值。这 个过程一直继续到只剩 1 个数据为止。因此,选择排序需要执行的步数为
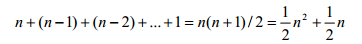
按照前述规则,可以看出选择排序算法所需的步数与数据列表大小的平方成正比,即算法复杂度为 O(n2),称为二次方时间算法。 其次,我们来推导归并排序算法的步数与列表大小的关系。归并排序算法的基本思想是将列表一分为二,然后对两半数据各自排序,最后再合并成一个列表。其中对两个子列表的 排序又是通过递归调用归并排序来实现的,最终将分解到长度为 1 的列表,这时可直接进行 归并。由此可见真正的排序工作是在归并过程中完成的,该过程所做的只是将来自子列表的 数据按从小到大的顺序逐个复制到初始列表的合适位置。图 10.11 展示了对列表[0,5,7,2]进 行归并排序的过程。图中用虚线表示初始列表的递归分解过程,逐步分解后最终得到长度为 1 的列表。这些长度为 1 的列表再进行归并,逐步形成长度为 2、4 的有序的列表,图中用实线箭头表示归并时各数据的逐步到位过程。从图 10.11 容易分析出归并排序算法的步数。 从左向右,分解过程并不比较数据大小来排序,这部分工作可以忽略。接下来的归并过程包 含大量比较、复制操作,是整个算法的工作量的体现。归并过程分为 log2n 层,以逐步形成 长度为 2、22、23、…、n 的有序子列表①。又因为每一层归并都需要对全部 n 个数据进行处 理,所以归并排序算法的步数是“n×层数”,即具有复杂度 O(nlog n),可称为 nlog n 时间 算法。

图 10.11 归并排序过程示意图
n2 与 nlog n 有多大差别呢?当 n 较小时,两者差距不大,选择排序算法甚至有可能还快 一些,因为它的代码更简单。但是,随着 n 的增大,log n 只是缓慢地增大,因此 n×log n 的增长速度远远低于 n×n。这就是说,对于大量数据,归并排序算法的性能远远好于选择 排序算法。
① 如果 n 不是 2 的幂,子列表的长度当然也不会都是 2 的幂。
Hanoi 塔算法
下面推导 Hanoi 塔问题的递归算法的步数与圆盘个数 n 的关系。与基于循环(迭代)的算法不同,递归算法不容易直接从代码形式上看出具体的操作步数。对于 Hanoi 塔递归算法, 我们可以直接考虑将 n 个圆盘从 A 柱移到 C 柱所需的移动次数。
根据算法的结构,为了移动 n 个圆盘,需要先将 n-1 个圆盘从最大圆盘上移开,然后移 动最大圆盘,最后再将 n-1 个圆盘移到最大圆盘上。假设 f(n)是移动 n 个圆盘所需的步数, 则应用一点中学数学知识很容易推导出
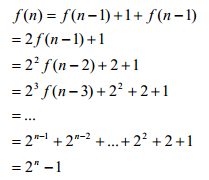
可见,Hanoi 塔算法的复杂度为 O(2n),称为指数时间算法,这是因为问题规模的度量 n 出 现在步数公式的指数部分。
指数时间算法到底有多复杂呢?读者也许听说过“指数爆炸”这个名词,它表明指数时 间算法所需要的执行时间会随着问题规模的增长而迅速增长。在 Hanoi 塔故事中,即使僧侣 们 1 秒钟就能移动一步圆盘,并且每天都不休息,为了移动 64 个圆盘,也需要花费 264-1秒,即 5850 亿年!可见,指数时间算法只适用于解决小规模的问题。
总之,利用计算机解决问题时,需要考虑算法的时间复杂性,这是衡量问题难度和算法 优劣的一个重要指标。有些应用对于运行时间有较高要求,运行时间过长的话可能导致计算 结果过时、失效。图 10.12 给出了本章见过的各种算法复杂度的大致比较,图中横坐标表示 问题规模 n,纵坐标是算法执行时间(或步数)。虽然图中曲线不是很精确,但足以说明指 数时间和二次方时间算法是多么不适合大量数据,而其他几种复杂度的曲线则相当平缓。

图 10.12 各种算法复杂度比较