3.3 Linux 编程基础
3.3.1 你必须掌握的技能
根据笔者的经验,要想在 Linux 上能够”无障碍”的用 Qt 编程,掌握必要的 Linux 技 能是必需的。以下是笔者列出的一些技能,供参考:
- 了解各个发行版的特点,能够根据需求,挑选和安装适合自己的发行版;
- 掌握常见的软件包管理工具的使用,包括 GUI 工具和编译命令,能够熟练安装软件包
- 熟悉 Linux 文件系统结构,能够熟练使用文件系统操作命令,配置文件的权限
- 了解 X Window 系统的原理和组成结构,必要时可以自行配置
- 能够熟练使用常见的集成式桌面环境,如 KDE 和 GNOME
- 熟悉 Linux 系统的帐号管理,能够熟练管理用户与组的帐号,并使用常用命令
- 能够熟练配置网络连接,包括局域网和 Internet
- 熟悉 Shell,了解 Shell 的种类,熟悉与 Shell 有关的配置文件,并能够根据需要修改
- 熟悉 Linux 文件压缩的方法,掌握文件压缩的常见命令
- 能够熟练使用 man 命令执行在线查询和获取帮助,能够熟练使用查找命令
- 能够熟练掌握各个发行版上基础编程环境的配置,主要包括 GCC、GDB 等
- 能够熟练使用一种代码编辑器,如 vi、emacs 等,推荐 vi
- 了解 Linux 系统下打包软件的常见方法
在下面的各节中,笔者将结合编程实际和本书内容的需要,有选择的向大家介绍这些技能,更为详尽的说明,请参考相关的 Linux 书籍。
3.3.2 文件系统管理
文件系统操作系统实际用来保存和管理各种文件的方法。由于每种操作系统支持的文件系统数量和类型都不同,因此在了解系统运行前,必须对文件系统的结构有所了解。尤其在 Linux 系统中,任何软硬件都被视为文件,所以这一部分的内容就尤为重要。
1.Linux 文件系统架构
操作系统中的文件系统(File System)可说是最基本的架构,因为几乎所有与用户、 应用程序或安全性模型相互通信的方法,都与文件保存的类型息息相关。
(1) 文件类型 简单来说,文件系统可以分为两种类型。
- 共享与非共享文件:共享文件是指允许其他主机访问的文件,而非共享文件则只供 本机使用
- 可变与固定文件:可变文件是指不需要通过系统管理员修改,即可自动更改内容的 文件,例如数据库文件;而固定文件则是指内容不会自动更改的文件,例如一般的文件或二 进制文件。
Linux 文件系统采用层次式的树状目录结构,此结构的最上层是根目录 “/”,然后在 根目录下再建立其他的目录。虽然目录的名称可以自定义,但是某些特殊的目录名称包含重 要的功能,所以不可随意将它们改名,否则会造成系统错误。
因为 Linux 允许不同的厂商及个人修改其操作系统,所以常会造成目录名称不统一的 情况,有鉴于此,目前有一套规范文件目录的命名及存放标准,它被称为 Filesystem Hierarchy Standard(FHS),这也是大多数 Linux 发行版遵循的标准,如果需要详细的说 明,请参考以下网站说明:http://proton.pathname.com/fhs/。
(2) Linux 默认目录
在安装 Linux 时,系统会建立一些默认的目录, 并且每个目录都有其特殊功能,如图 3-5 所示。
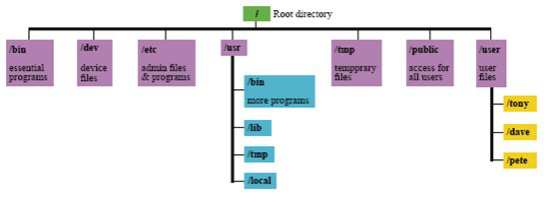
图 3-5 Unix/Linux 文件系统结构图
以下是这些目录的说明:
- /:Linux 文件系统的最顶层根目录
- /bin:Binary 的 缩写,存放用户的可执行程序,例如 ls、cp 和 mv 等,也包含其 他的 Shell,例如 Bash 和 csh
- /boot:操作系统启动时需要的文件,例如 vmlinuz 和 initrd.imp。这些文件如果 损坏,常会导致系统无法正常启动,因此最好不要任意改动
- /dev:接口设备文件目录,例如 hda 表示第一块 IDE 硬盘
- /etc:有关系统设置与管理的文件,例如 password。目前保存在 etc/目录中的文 件都不是二进制文件,之前在此目录中的二进制文件都已移到 /sbin 或/bin 目录
- etc/X11:X Window 系统的设置目录
- /home:一般用户的主目录或 FTP 站台目录
- /lib:仅包含执行/bin 和/sbin 目录中的二进制文件时所需的共享类库( shared library)
- /mnt:各项设备的文件挂载(Mount)点,例如光盘的默认挂载点是/mnt/cdrom, 而/mnt/floppy 是软驱的默认挂载点
- /opt:这个目录通常提供一个空间,供较大型且固定的应用程序软件包保存文件使 用,这样可以避免将文件分散到整个文件系统
- /proc:目前系统内核与程序执行的信息,它和用ps命令看到的内容相同
- /root:root 管理员主目录,其他用户的主目录都位于 /home 目录中
- /sbin:是 System Binary 的缩写,此目录存放的是系统启动时需要执行的程序, 比如 swapon
- /tmp:Tempoary 的缩写,它是用来存放临时文件的目录
- /usr:存放用户使用的系统命令,以及应用程序等信息
- /usr/bin:存放用户可执行程序,例如 finger 和 mdir 等
- /usr/include:保存供 C 语言加载的头文件
- /usr/include/X11:保存供 X Window 程序加载的头文件
- /usr/lib:用户类库
- /usr/lib/X11:X11 的类库
- /usr/local:提供自行安装的应用程序位置
- /usr/sbin:存放非经常性使用的程序,例如 showmount
- /usr/src:保存程序的原始文件
- /usr/X11R6/bin:存放 X Window 系统的执行程序
- /var:Variable 的缩写,具有可变性质的相关程序目录,例如 log、spool 和 named 等
(3) Linux 文件名称
Linux 中的文件名称最长可允许 256 个字符,而这些字符可用 A~Z、0~9、_、-等字符 来命名。
与其他操作系统相比,比如 DOS 和 Windows,Linux 最大的不同是,它并没有扩展名的 概念,也就是说文件的名称和该文件的类型并没有直接的关联,例如 sample.txt 可能是执 行文件,sample.exe 也有可能是文本文件,甚至可以不用扩展名。
另一个特性是文件名称区分大小写(Case Sensitive),这也是习惯 DOS 和 Windows 平台用户最难适应的一点。但所有的 Unix(包括 Linux)都遵循这条原则,例如 sample.txt、Sample.txt、SAMPLE.txt、sampLE.txt 在 Linux 上代表不同的文件,但在 DOS 和 Windows 平台上却是指同一个文件。
(4) Ext3 文件系统
Linux 可说是一种兼容性很高的操作系统。它可以支持的文件系统有很多,例如 msdos、ntfs、vfat、iso9660、minix 等等,也就是说它可以和其他许多不同的文件或操作 系统同时存在于硬盘中,这也是 Linux 足以傲视其他操作系统的地方之一。
与 micorsoft Windows 操作系统不同的是,Linux 并没有分区的概念,也就是说,它不 会将文件的保存位置指定为磁盘驱动器 C、D、E 等等,而是使用树状的 ext3fs(Third Extended File System)作为主要的文件系统(有时也简称为 ext3)。
ext3fs 是大多数 Linux 默认的文件系统,它主要是在原有的 ext2fs 系统上增加了日志 功能,并且在数据的有效性、完整性、访问速度方面有了大幅提高。
(5) Linux 文件路径
在此我们要介绍 Linux 文件路径表示法。因为在 Linux 的世界中没有微软产品的磁盘 驱动器的概念,也就是说没有所谓的磁盘驱动器 C、D 等表示法,它是利用目录与子目录的 层次式(Hierarchical)概念来表示文件保存位置的。
所以你需要先建立起这个新概念,否则可能会因为先前的概念而产生学习 Linux 的障 碍。一般来说,Linux 的文件路径分为两类:绝对路径和相对路径。
所谓绝对路径,就是指以根目录(/)为起始点来表示的路径,例如 “/etc/ppp/peers/isdn/avm”就是绝对路径,也就是说,如果一个路径的表示法是以根目 录(/)开头,那就属于绝对路径;如果不是以根目录开头,就称为相对路径。
相对路径是指从当前的目录算起。我们以刚才的绝对路径为例,如果现在工作的目录 是/etc/ppp,那么用相对路径来表示就是“./peers/isdn/avm”(也可以省略为 peers/isdn/avm)。
因为系统会自动在此路径前加上当前的工作目录位置,所以适当的使用相对路径可以 节省输入时间,并避免错误产生。
3.3.3 X Window 系统
许多人在抗拒学习 Linux 时,最大的借口之一就是命令和参数多如牛毛,特别是惯用 微软 Windows 操作系统的人更难接受。不过目前在 Linux 上已经大幅进步的图形界面功 能,使得 X Window 系统成为学习 Linux 时的另一种选择。
1.X Window 系统基础
X Window 系统是一种图形化的操作环境,它可以在 Unix 和 Linux 操作系统上提供 GUI(Graphical User Interface,图形用户界面)操作界面,同时它也有以下几种不同的名 称:X、X 视窗、X11、X11R7。
在此特别提醒一点,虽然以上名称都可用来表示 X Window 系统,但却不可称为 “Windows”,因为 Windows 一词已被 Microsoft 公司注册,所以切勿使用 Windows,以免 侵犯该公司的注册商标。
(1) X Window 系统的起源
在 X Window 系统出现前,其实已经有很多公司在发展 Unix 用户图形界面,但由于每 家公司开发的规范不一,因此在兼容性方面表现不佳,这种情形直到 X Window 系统推出后 才得以解决。
X Window 系统起源于 1984 年的雅典娜(Project Athena),它是由麻省理工学院(MIT)与 Digital Equipment 公司合作开发的图形界面系统,因为它以斯坦福大学的 W Window 系统为基础,所以命名为 X Window 系统(因为字母 X 位于 W 之后)。
为了确保 X Window 系统的持续发展,MIT 于 1988 年成立 X Consortium,它由 X Window 系统的主要设计者 Robert W.Scheifler 负责。之后由于 X Window 系统引起许多公司的兴趣,所以新版的 X Window 系统不断问世。
(2) X Window 系统组成
X Window 系统采用客户端-服务器架构,其中主要的组件为: X Server 和 X Client。 前者负责驱动显示卡和各种图形的显示,同时也会驱动其他输入设备,使客户端可以通过这 些输入界面与应用程序通信。而后者指实际执行的应用程序,它会向 X Server 提出服务请 求,以得到响应的显示画面。
除了 X Server 和 X Client 之外,在 X Window 系统中还包含其它组件,如图所示,以 下是这些组件的说明:
X Protocol
介于 X Server 和 X Client 间用于沟通的通信协议。因为基本的 X Window 系统并不提 供用户界面,比如按钮和菜单等组件,所以必须依靠 X Protocol 中的程序来提供这类功 能,否则单纯的 X Window 系统无法满足客户端的要求。
X Library
最底层的程序界面,它的主要功能是存取 X Protocol 服务,这对于图形程序编写非常 重要,常见的 X Library 有:Xlib、Motif、Qt 和 GTK+等。
X Toolkit
包含在 X Library 中的应用程序发展工具,它提供了 X Window 设计时需要的基本函 数,避免了程序开发时必须自行设计所有组件的不便,例如滚动条和功能钮。这些组件也称 为 widgets。目前 X Toolkit 的种类很多,较常见的有:Motif Development Toolkit、 OpenLook Toolkit、GTK+、TCL/TK、XForms 和 X Toolkit(Xt)等。
(3) X Window 系统的特点
X Window 系统的特点可以归纳如下:
图形化界面
X Window 系统是在 Linux 中唯一的图形界面系统,但是可以搭配多套窗口管理程序使 用,是比 Windows 产品更具有弹性设计。如果希望修改某些窗口管理程序的内容,可以用 它的源代码进行修改。
支持多种应用程序
目前在 X Window 系统中可使用的应用程序越来越多,文字处理、多媒体、图形图像、 游戏软件、因特网、甚至系统管理工具,都有免费的图形化工具可供使用。这除了有助于消 除用户对于文字界面的陌生感,还可以使其可能逐步取代 Windows 而成为个人工作站的选 择。
弹性设计
因为在 X Window 系统的设计中,X Server 只负责基本的显示及终端的控制,而其余的部分都是由 X Client 处理,所以这种设计不受操作系统的限制,突同的操作系统都可以使用 X Server。特别是在 Unix 的多任务环境中,更能发挥其优异的特性。
客户端-服务器架构
X Window 系统采用客户端-服务器架构,它将系统显示功能与应用程序分别用 X Server(X11R7)和 X Client 来执行,这种架构最大的优势是,执行程序( X Client)和 显示结果(X Server)的主机可以是不同的两部计算机。
举例来说,如果希望在主机上使用 firefox 来浏览网页,但是主机尚未安装 firefox, 而网络的某个工作站上装有 firefox,此时即可连接此工作站并执行 firefox,再将结果返 回本地主机。
在以上的例子中,本地主机担任 X Server 的角色,它只负责显示结果,而远程装有 firefox 的 Linux 工作站则是 X Client,它负责执行程序,在网络间负责传递两端信息的 机制则为 X Protocol。
通过 X Protocol 这个媒介,所有的主机都能使用此软件,而不需要在每台计算机上安 装相同的软件。因此建议将大型且需要高速运算的软件交由能力较强的工作站来处理,然后 再用网络显示执行结果。
2.X11R7
X11R7 是目前多数主流 Linux 发行版使用的 X Server,它发布于 2005 年 12 月,与之 前的 X11R6.9 相比,采用了模块化的设计。
(1) X11R7 重要目录
与 X11R7 有关的软件,大多放在/usr 及其子目录中,以下是较为重要的目录的说明。
- /usr/bin:存放 X Server 和不同的 X Client
- /usr/include:开发 X Client 和图形所需的文件路径
- /usr/lib:X Server 和 X Client 所需的类库目录
- /usr/lib/X11:保存多项资源,例如字体和文件等
- /usr/lib/xorg/moudles:包含驱动程序与多种 X Server 模块
- /usr/X11/man:保存 X11 程序编写时的手册说明
(2) /etc/X11/xorg.conf 文件
在安装 Linux 时如果没有设置 X Window 系统,之后必须先设置鼠标、键盘、显示器以 及显示卡等,才能成功启用 X Window 系统,而这些设置都记录在/etc/X11/xorg.conf 文件 中,由此可见这个文件的重要性。
这个文件由数个 Section/EndSection 的区块组成,每个区块的格式如下:
Section “Section 名称”
选项名称 “选项值”
选项名称 “选项值”
选项名称 “选项值”
......
EndSection
在/etc/X11/xorg.conf 文件中,有多个区块是非常重要的,包括 ServerLayout、
Files、Moudle、InputDevice、Monitor、Device、Screen 和 DRI 等。从字名上不难看出它 们的用途,详细的设置请参阅相应的 Linux 发行版手册,这里不再赘述。
3.集成式桌面环境
惯用 Windows 操作系统的用户可能没有想过,为什么每个人的右键菜单、开始菜单、 所有程序以及其它的系统设置都是如出一辙?能不能随着用户的喜好进行修改呢?
的确,Windows 系统使用单一的图形界面,并且用户无法改变它。而 Linux 在这方面就 具有较大的弹性,用户可以依其喜好随时改变图形界面,这就是所谓的集成式桌面环境。在 我们使用 Qt 开发的时候,经常用到的两种桌面环境是 GNOME 和 KDE。
(1) GNOME
GNOME 是 GNU Network Object Model Environment 的缩写,它属于 GNU(GNU‘s Not Unix)项目的一部分,这个项目始于 1984 年,目的是发展一个完全免费的类 Unix 操作系 统。GNOME 目前是许多 Linux 发行版默认的桌面环境。
除了包含功能强大的组件外,GNOME 也具有灵活的可配置性,所以可以根据个人的喜好 和习惯设置桌面环境。
(2) KDE
KDE(K Desktop Environment)是目前 Linux 两大集成式桌面环境之一,它与 1996 年 10 月由 Lyx 的原创者 Matthias Ettich 发起,从而促成了 KDE 计划的产生。
与 GNOME 最大的不同是,KDE 原本是使用 QPL(商业版权)发展的,而 GNOME 则是遵循 GNU 协议的,因此在刚开始时,KDE 的推广遇到了一定的障碍。直到 Qt 决定使用 GPL 协议 后,KDE 的发展又进入了快车道。
Linux 桌面环境的使用相对比较容易,可以参阅系统提供的帮助。
3.3.4 常用命令
下面我们介绍一些常用的命令,它们是经常会被用到的,需要熟练掌握。这里并不展 开对各个命令的详细说明,使用时请参考相关书籍,也可以使用 man 命令来获得帮助。
表 3-4 Linux 常用命令说明
| man | 获得联机帮助,是类 Unix 用户的在线帮助手册 |
|---|---|
| cd | 切换当前路径命令 |
| pwd | 显示当前路径 |
| ls | 显示目录下面的文件和子目录情况 |
| chmod | 变更文件和目录的属性 |
| mkdir | 建立目录 |
| rm | 删除目录或文件 |
| su | 切换用户登录到 shell,常见从一般用户到 root 用户或者相反顺序 |
| exec | 执行程序,并且不返回到当前 shell |
| ldd | 查看应用程序使用的动态库 |
| nm | 查看程序或库的调试信息 |
| objdump | 查看程序或库的信息 |
| env | 查看环境变量 |
| grep | 从文件中查找字符串 |
| find | 查找文件 |
| which | 查找命令的可执行文件 |
| uname | 查看操作系统版本 |
| ps | 查看进程信息 |
| top | 查看系统资源信息 |
| vmstat | 查看系统虚拟机各资源信息 |
| vi/vim | 使用 vi/vim 编辑器 |
| make | 处理工程文件,生成可执行文件或库或其他资源文件 |
| gdb/dbx | 调试工具命令 |
| strace/ltrace | 跟踪程序调用的系统函数情况 |
| file | 查看文件的格式 |
| fuser | 查看进程使用了哪些文件 |
3.3.5 Shell 应用
Shell 在操作系统中的作用就如同是翻译员,它在用户和操作系统之间传递信息。如果 少了它的运行,那么用户和操作系统之间将被完全阻隔而无法沟通。因此,了解 Shell 是 深入 Linux 核心、学习 Linux 上 Qt 开发的基本功课之一。
1.Shell 基础
Shell-如同其名字一样,它就像是一个壳,而这个壳介于用户和操作系统( Kernel)中间,负责将用户的命令解释为操作系统可以接受的低级语言,同时将操作系统的响应信息 以用户了解的方式来显示,这样可以避免用户执行不当的命令而对系统产生损害。图描述的是 Shell 这种角色。
每个用户在登录 Linux 后,系统会出现不同的提示符号,如#、$或~等,之后就可以输 入需要的命令。如果命令正确,系统就可按照命令的要求来执行,直到用户注销系统为止。 在登录到注销期间,用户输入的每个命令都会经过解释并执行,而这个负责的机制就是 Shell。
(1) 命令的类型
一般用户的命令可分为两大类:程序和 Shell 内置命令。如果该命令为程序类型,那 么 Shell 会找出该程序,然后将控制权交给内核,并由内核负责执行该程序;而在内核将 程序执行完毕后,再将控制权交给 Shell。但如果是 Shell 内置命令,则由 Shell 直接响 应,因此速度较快。
要判断一个命令属于 Shell 的内置命令还是程序,可以用 find 命令来判断:如果 find 命令没有任何响应,则表示该命令为 Shell 内置命令;如果显示查找的结果,则该命令为 程序。
其实 Shell 的概念并不只存在与 Linux 系统,在其他的操作系统上也有,只不过名称 不同,如 DOS 中的 command.com 和 Microsoft Windows 的 GUI(Graphical User Interface)。
但是 Linux 操作系统对于 Shell 极具灵活性的使用,是其他操作系统望尘莫及的。在 Linux 中可以使用的 Shell 很多,并且可以随意更换不同的 Shell。
(2) Shell 的种类
Linux 支持的 Shell 都记录在/etc/shells 文件中,我们可以使用 cat 命令来查看支持 的 Shell。
[wd@localhost ~]$ cat /etc/shells
/bin/sh
/bin/bash
/sbin/nologin
/bin/tcsh
/bin/csh
/bin/ksh
虽然每种 Unix/Linux 系统可以兼容的 Shell 有很多,但是使用较广的只有三种: Bourne Shell(sh)、C Shell(csh)以及 Korn Shell(ksh)。
每种 Shell 的命令名称和登录时出现的提示符号不尽相同,表 3-5 是个简单的说明。
表 3-5 常见 Shell 的说明
| Shell 名称 | 命令名称 | 登录符号 |
|---|---|---|
| Bourne | /bin/sh | $ |
| C | /bin/csh | % |
| Korn | ksh | $ |
I. Bourne Shell
Bourne Shell 是最早被大量使用和标准化的 Shell,几乎所有的 Unix/Linux 都支持。 由于 Bourne Shell 在执行效率上优于其他的 Shell,所以它是大多数 Unix 系统的默认Shell。但是它并不支持别名(aliases)与历史记录(history)等功能,同时在作业控制(Job Control)上的功能也比较简单,所以整体而言,在目前的系统环境下已略显不足。
II. C Shell
C Shell 的语法与 C 语言类似,它因此而得名。C Shell 已经是 Unix 类操作系统的重 要组成部分之一。
C Shell 的特点在于易于使用以及交互性强,目前 BSD 版的 UNIX 大多以 C Shell 作为 默认的 Shell。
III. Korn Shell
Korn Shell 兼具 Bourne Shell 和 C Shell 的优点,并且语法与 Bourne Shell 兼容, 但它出现的较晚,在一些新版的 Linux 发行版如 Ubuntu 中才有支持。
(3) 更改 Shell
因为 Linux 可以支持的 Shell 有很多,所以大家可以根据个人的习惯选择使用不同的 Shell。要查看当前使用的 Shell 或系统默认的 Shell,最简单的方式就是使用 echo 命令来 查询系统的 Shell 环境变量,命令用法如下:
[wd@localhost ~]$ echo $SHELL
/bin/bash #当前使用的 Shell 为 bash
或者输入:
[wd@localhost ~]$ echo ${SHELL}
/bin/bash
但是以上的方法只能显示用户登录时使用的 Shell,而无法显示出更换过的 Shell。如
果要更改使用的 Shell。只要执行该 Shell 程序名称,即可切换到不同的 Shell。下面是更 改 Shell 的方法:
[wd@localhost ~]$ sudo sh
#执行 sh
$ sudo bash
#执行 bash
在一般情况下,执行 exit 命令会立即注销系统。但如果从默认的 Shell 切换到其他的Shell,则不论切换的次数有多少,在切换后使用 exit 命令都不会注销系统,而只会跳离 当前的 Shell,并回到上一层的 Shell。
以上切换 Shell 的方法虽然简单,但它只是暂时的改变,待用户注销后登录,又会回 到系统默认的 Shell。
要解决上述问题,可以使用 chsh 命令(Change Shell),它的使用方法很简单。下面 是将用户默认的 Shell 改为 csh 的例子:
[wd@localhost ~]$ sudo chsh
正在更改 root 的 Shell
请输入新值,或直接敲回车键以使用默认值
登录 Shell [/bin/bash]: /bin/csh
# Shell 更改成功
注意,在使用 chsh 命令更改用户默认的 Shell 后,要重新登录才会更改。
2.环境变量
所谓的“环境变量”(Environment Variables),是指 Shell 中用来保存系统信息的 变量,这些变量可供 Shell 中执行的程序使用。不同的 Shell 会有不同的环境变量名称和 环境变量值的设置方法。
在 bash 中要显示环境变量名称及环境变量值,可以使用 set 命令。
3.Shell 配置文件与 Shell Script
在上一小节里,我们介绍了环境变量的内容,并了解了如何自定义变量名称或修改预 先定义的变量。而除了可以使用命令来执行变量的设置外,也可以通过一些 Shell 配置文 件来设置。在用户登录时,系统会检查这些配置文件,以便设置环境。
本小节我们将列出所有与 Shell 有关的配置文件名称,并且说明每个文件的功能。
(1) /etc/profile
这是系统最主要的 Shell 配置文件,也是用户登录时系统最先检查的文件。系统最重 要的环境变量都定义在此,其中包括 PATH、USER、LOGNAME、MAIL、HOSTNAME、HISTSIZE 和 INPUTRC 等。
除此之外,这个文件也定义了 ulimit,它的功能是限制每个 Shell 所能执行的程序数 目,以免造成系统资源的过度消耗。而在文件的最后,它会检查并执行
/etc/profile.d/*.sh 的 Script。
(2) ~/.bash_profile
这个文件是每位用户的 BASH 环境配置文件,它存在于用户的主目录中。当系统执行 /etc/profile 后,就会接着读取此文件内的设置值。
在此文件中,会定义 USERNAME、BASH_ENV 和 PATH 等环境变量。但是此处的 PATH 除了 包含系统的$PATH 变量外,还另外加入了用户的 bin 目录路径,而 BASH_ENV 变量则指出接 下来系统要检查的文件名称。
(3) ~/.bashrc
接下来系统会检查~/.bashrc 文件,这个文件和前两个文件(/etc/profile 和 ~/.bash_profile)最大的不同是,每次执行 bash 时,~/.bashrc 都会被再次读取,也就是 说变量会再次被设置;而/etc/profile 和~/.bash_profile 只有在登录时才进行读取。
就是因为经常被重新读取,所以~/.bashrc 文件只用来定义一些终端设置及 Shell 提示 符号等,而不用来定义环境变量。
举例来说,如果远程的终端窗口(例如由微软平台以 Telnet 进行登录)无法浏览超过 一页的信息或文件内容,可以在此文件中加入下面这行:
export TERM=vt100
~/.bashrc 文件中值得注意的一行是“. /etc/bashrc”,它利用一个小数点接着一个空格键再指向另外一个 Script,表示同时执行此 Script,并且采用 Script 的变量设置。
(4) ~/.bash_login
如果~/.bash_profile 文件不存在,则系统会转而读取这个文件内容。这是用户的登录 文件,每次用户登录系统时,bash 都会读取此文件,所以通常都会将登录后必须执行的命 令放在这个文件中。
(5) ~/.profile
如果~/.bash_profile 和~/.bash_login 两个文件都不存在,则会使用这个文件的设置 内容。它的功能与~/.bash_profile 完全相同。
(6) ~/.bash_logout
这个文件是 bash 在注销系统前读取的文件。通常这个文件只包含 clear 命令,也就是 先清除屏幕再注销。如果想在注销 Shell 前执行一些工作,例如清空缓冲区或执行备份, 都可以在此文件中设置。
(7) ~/.bash_history 这个文件中会记录用户曾经使用的命令历史,以供查阅。
3.3.6使用库程序
编程库是可以在多个软件项目中重用的代码集合。库是软件开发核心目标(代码重用)的一个经典例子。它们把常用的编程例程和实用程序代码收集到单独位置。例如,标准的 C 库包含数百个常用的例程,如输出函数 printf()和输入函数 getchar(),如果 每次创 建新程序都要重写它们很让人厌烦。但是,除了代码重用和程序员获得便利之外,库还提供大量已完成调试和良好测试过的实用程序代码,如用于网络编程、图像处理、数据操作和系统调用的例程。
在创建、维护以及管理编程库时,需要知道可用的工具。有两类库:静态的和共享的。
1.静态库
静态库是包含目标文件的专门格式文件,这些文件称为模块或成员,是可重用的、预 编译的代码。以特殊格式将它们与一张表格或映射图(把符号名链接到定义符号的成员)存 储起来。映射图可加快编译和链接。静态库通常用扩展名 .a 命名,.a 代表归档(archive)。
2.共享库 又被称作是动态库。与静态库类似的地方是,共享库也是文件,它包含其他目标文件或者指向其他目标文件的指针。称它们为共享库是因为在编译程序时,不 需要将它们包含的代码链接到程序。相反,动态的链接器 /装载器在运行时把共享库代码链接到程序中。
与静态库相比,共享库有几个优势。首先,它们需要的系统资源较少。因为共享库代 码没有编译成二进制代码,而是在运行时从单个位置动态的链接和装载,所以它们使用更少 的磁盘空间。它们使用的系统内存也较少,因为只需一次即可将它们装载到内存。最后,共 享库简化了代码和系统维护。修复 bug 或添加特性后,用户只需获得已更新的库并且安装 它即可。但对于静态库,必须重新编译使用该库的每个程序。
小贴士:如果想要构建一个在主机系统上不依靠任何内容的应用程序,或者在不确定开发 环境的地方使用特殊的命令时,使用静态库也有一定的优势。但是通常建议使用共享库。
3.常见的库命令
(1) nm 命令
nm 命令列出目标或二进制文件中所有已编码的符号。使用它可查看程序调用了什么函 数,或者查看库或目标文件是否提供了所需的函数。 nm 的语法如下:
nm [options] file
nm 列出存储在 file 中的符号,该 file 必须是静态库或归档文件,正如前面小节所描述的。options 控制 nm 的行为。符号类似与在代码中引用的函数、来自其他库的全局变量 等内容。必须跟踪找到程序所需的丢失符号时,可以使用 nm 命令作为一个工具。
表 3-6 介绍了有用的 nm 选项。
表 3-6 nm 命令行选项
| 选项 | 描述 |
|---|---|
| -c | 把符号名转换成用户级别名。这对使 C++函数名可读特别有用 |
| -l | 使用调试信息打印每个符号定义的行号,如果符号未定义,则重定位输入项 |
| -s | 在归档文件(.a)上使用时打印索引,该索引把符号名映射到定义符号的模块或成员上 |
| -u | 只把未定义的符号、外部定义的符号显示到正被检验的文件 |
下面是一个例子,它使用 nm 显示/usr/lib/libdl.a 中的一些符号:
$ nm /usr/lib/libdl.a | head
dlopen.o:
0 0 0 0 0 0 4 0 T __dlopen_check
U _dl_open
U _dlerror_run
0 0 0 0 0 0 4 0 W dlopen
0 0 0 0 0 0 0 0 t dlopen_doit
dlclose.o:
U _dl_close
(2) ar 命令
ar 可创建、修改或者提取档案。最常用于创建静态库(该库是包含一个或者多个目标 文件的文件)。ar 还创建并维护一个表,该表交叉引用符号名和定义符号名的成员。 Ar 命 令的句法如下:
ar {dmpqrtx} [options] [member] archive file [...]
ar 根据 file 中列出的文件创建名为 archive 的档案。至少要求使用 d、m、p、q、r、t 和 x 中的一个。通常使用 r。表 列出了最为常用的 ar 选项。
表 3-7 ar 命令行选项
| 选项 | 描述 |
|---|---|
| -c | 如果 archive 尚不存在,则通常发出禁止警告 |
| -q | 不检查是否有移位,把文件添加到 archive 末尾 |
| -r | 把文件插入 archive,代替任何现有成员中其名字与正增加的 文件名匹配的成员。新成员增加到档案末尾 |
| -s | 创建或者更新映射,此映射将符号链接到定义符号的成员 |
小贴士:给定一个用 ar 命令创建的档案,通过创建该档案的索引,可以加快档案的访问速度。ranlib 可精确的完成该任务,它在档案本身中存储该索引。 Ranlib 的句法是:
ranlib [-v | -V] file
这在 file 中生成符号映射,它等同于 ar -s file。
(3) ldd 命令
虽然 nm 可列出目标文件中定义的符号,但除非知道各个库定义了哪些函数,否则它没 什么太大用处。这就是 ldd 的工作了。它列出程序运行时所需的共享库。它的句法是:
ldd [options] file
ldd 打印 file 要求的共享库名。ldd 两个最有用的选项是-d(它报告任何缺失的函数)和-r(它报告缺失的函数和缺失的数据对象)。例如,下面的 ldd 报告 ftp 客户端 lftp(系统 上可能已安装它,也可能未安装)需要 13 个共享库:
$ ldd /usr/bin/lftp
liblftp-jobs.so.0 => /usr/lib/liblftp-jobs.so.0 (0x2aaf8000)
liblftp-tasks.so.0 => /usr/lib/liblftp-tasks.so.0 (0x2ab48000)
libreadline.so.5 => /usr/lib/libreadline.so.5 (0x2abbc000)
libutil.so.1 => /lib/libutil.so.1 (0x2ac08000)
libncurses.so.5 => /lib/libncurses.so.5 (0x2ac1c000)
libresolv.so.2 => /lib/libresolv.so.2 (0x2ac50000)
libdl.so.2 => /lib/libdl.so.2 (0x2ac78000)
libc.so.6 => /lib/libc.so.6 (0x2ac8c000)
libstdc++.so.6 => /usr/lib/libstdc++.so.6 (0x2ae24000)
libm.so.6 => /lib/libm.so.6 (0x2af44000)
libgcc_s.so.1 => /lib/libgcc_s.so.1 (0x2afdc000)
/lib/ld.so.1 (0x2aaa8000)
libtinfo.so.5 => /lib/libtinfo.so.5 (0x2b018000)
具体系统上的输出可能会有所不同。
(4) ldconfig 命令
ldconfig 确定共享库所需的运行时链接,它位于 /usr/lib 和/lib 中,在命令行上 libs 中指定,存储在/etc/ld.so.conf 中。它与动态链接器/装载器 ld.so 一起工作,创建 并维护到系统上最新版本可用共享库的链接。它的句法如下:
ldconfig [options] [libs]
运行无参数的 ldconfig 只会更新缓存文件/etc/ld.so.cache。options 控制 ldconfig的行为。当 ldconfig 更新缓存时,-v 选项通知它是 verbose 的。-p 选项表示打印,但不 更新 ld.so 所知道的当前共享库列表。要查看更新缓存时 ldconfig 正在完成什么,-v 选项可以打印显示 ldconfig 已经找到的目录和系统链接。
4. 环境变量和配置文件
动态链接器/装载器 ld.so 使用很多的环境变量来自定义和控制其行为。这些变量包括:
$LD_LIBRARY_PATH
该变量包含一个用冒号分隔开的目录列表,运行时在该表中查找共享库。它类似于$PATH 环境变量。
$LD_PRELOAD
该变量是一个用空格分隔开的附加列表,其中包含用户指定在所有其他库之前装载的库。它用于有选择的覆盖其他共享库中的函数。
ld.so 还使用两个配置文件,其作用目的与那些环境变量平行:
/etc/ld.so.conf
包含一个目录列表,除了标准目录(/usr/lib 和/lib,以及 64 位架构系统上的/lib64),连接器/装载器还应该在该列表的目录内搜索共享库。
/etc/ld.so.preload 包含$LD_PRELOAD 环境变量基于磁盘的版本,它包括一个在执行程序之前装载的、用空 格分开的共享库列表。
可以借助$LD_PRELOAD 使用特定的版本来覆盖已安装的版本。在测试新的(或者不同 的)库版本,而又不想在系统上安装代替库时,该功能通常很有用。通常在创建程序时只使 用环境变量。在生产环境中不要依赖这些环境变量,因为在过去它们导致过安全问题,所以 可能无法控制变量的值。
3.3.3 使用 VI
一个常用的 Linux 开发工具箱中必须包含包括什么?基本上要包括一个编写代码的编 辑器、一个或者多个把源代码转化成二进制代码的编译器,以及一个跟踪无法避免的 bug 的调试器。多数人都有喜爱的编辑器,试图说服他们试用新的编辑器是很困难的事情。多数 编辑器支持一组与编程有关的功能(可以肯定有些支持的功能会更多)。可以使用的编辑器 太多,由于篇幅有限无法意义介绍,但有一点是必须要声明的:至少需要一个编辑器。
只要使用 Linux,那么不使用文本编辑器几乎是不可能的。这是因为多数 Linux 配置文 件是纯文本文件,所以有时肯定需要进行手动修改。
如果正在使用 GUI,那么可以运行 gedit,编辑文本时使用它相当直观。还有一个简单 的文本编辑器 nano,可以从 shell 中运行它。但是多数 Linux Shell 用户会使用 vi 或 emacs 命令来编辑文本文件。与图形编辑器相比, vi 或 emacs 的优势在于可以在任何 shell、字符终端或基于字符的网络连接(例如使用 telnet 或 ssh)中使用它们,而无需使 用 GUI。它们都具有强大的功能,所以可以一直使用它们。
本节我们将提供一个简单的 vi 文本编辑器教程,使用它可在任意 shell 中手动编辑配 置文件。
1.运行 vi
通常情况下,运行 vi 可以打开特定的文件。例如,要打开 /tmp/test 文件,可输入下 面的命令:
$ vi /tmp/test
如果这是一个新文件,应该看到和下面类似的内容:
"/tmp/test" [New File]
顶部的框表示光标的位置,底部的行通知编辑情况(此处只是打开了一个新文件)。
在这两部分之间,波浪线(~)作为填充符,因为文件中还没有任何文本。现在这是令人害 怕的部分:这里没有提示、菜单或图标告诉我们要做什么。不能只是从顶部开始输入。如果 这样做,计算机就会发出蜂鸣声。所以有些人抱怨 Linux 并不友好。
(1) 首先需要了解的是不同的操作模式:命令或输入。
vi 编辑器始终启动到命令模式。在添加或修改文件中的文本前,必须输入命令(一个 或者两个字母加上一个可选的数字)告诉 vi 您想要做什么。大小写很重要,所以要按例子 所示精确的使用大写或小写字母!要进入输入模式,输入该输入命令。输入下面的命令开始 操作。
- a:添加命令。在它之后,可以从光标的右端开始输入文本。
- i:插入命令。在它之后,可以从光标的左端开始输入文本。 输入一些词句,然后按下 Enter 键。重复执行该操作数次,直到有几行文本为止。完成输入后,按下 Esc 键反回到命令模式。现在文件中有些文本了,试用下面的键或字母在文本中移动。记住使用 Esc 键,它始终可以回到命令模式。
- 方向键:在文件中上、下、左或右移动光标,一次一个字符。也可以使用退格键和 空格键分别向左和向右移动。如果喜欢将手指放在键盘上,可使用 h(左)、l(右)、j(下)、 或 k(上)来移动
- w:将光标移动到下一个单词的开头。
- b:将光标移动到前个单词的开头。
- $(零):将光标移动到当前行的末尾。
- H:将光标移动到屏幕的左上角(屏幕上的第一行)。
- M:将光标移动到屏幕中间的第一个字符。
- L:将光标移动到屏幕的左下角(屏幕上的最后一行)。
(2) 其它编辑操作中唯一需要知道的是如何删除文本。 下面是一些删除文本用的命令。
- x:删除光标下的字符。
- X:删除光标前字符。
- dw:删除从当前字符开始直到当前单词末尾的所有字符。
- d$:删除从当前字符开始直到当前行末尾的所有字符。
- d0:删除从前一个字符开始直到当前行开头的所有字符。
(3) 要结束编辑,可使用下列击键保存和退出文件。
- ZZ:将当前修改保存到文件并退出 vi。
- :w:保存当前文件,但继续编辑。
- :wq:与 ZZ 相同。
- :q:退出当前文件。没有任何未保存的修改时该命令才会工作。
- :q!:退出当前文件,并且不保存对文件进行的修改。 小贴士:如果确实错误的修改了文件,那么 :q!命令是退出并且放弃修改的最好方法。文件会还原到最近修改的版本。所以如果只是使用 :w,有时可能会陷入困境。如果只想取消一些错误的编辑,按 u 键即可撤销修改。
(4) 常用技巧
现在已经学习了一些 vi 编辑命令。在后面会介绍更多的命令。这里先列出首次使用 vi 的一些提示。
- Esc:记住,Esc 用于回到命令模式(我曾看到有人按下键盘上的所有键来尝试退出 文件)。
- u:按 u 键可以撤销之前做的修改。连续按 u 键可以撤销更前面的修改。
- Ctrl+R:如果决定不再撤销前面的命令,可使用 Ctrl+R 进行恢复。本质上,这个 命令取消所做的撤销操作。
- Caps Lock:小心不要错按了 Caps Lock 键。处于大写状态时,在 vi 中输入的任何 内容都有不同含义。输入大写字母时不会出现警告,但事情却开始变得不可思议。
- :!命令:在 vi 中,可使用:!后跟命令名的方式来运行命令。例如,输入 :!date 查 看当前的时间和日期,输入:!pwd 查看当前目录,输入:!jobs 查看后台是否有任务正在运 行。命令运行完成时,按 Enter 键就可以返回继续编辑文件。甚至可以使用该技术从 vi 中 启动 shell(:!bash)、在该 shell 中运行几个命令,然后键入 exit 返回到 vi(我建议 转到 shell 前保存文件,防止回到 vi 后忘记保存)。
- —INSERT:处于插入模式时,INSERT 一词会出现在屏幕底部。
- Ctrl+G:如果忘记了正在编辑的内容,按下这些键可在屏幕底部显示正在编辑的文 件名和所在的行。它还显示文件的总行数、己浏览过的部分占该文件的百分比,以及光标所 在的列号。这用来在下午停止工作一段时间后,帮助您确定编辑的位置。
2.搜索文本
要搜索文本在文件中下次出现的位置,可使用斜线(/)或问号(?)。在斜线或问号后面加上模式(字符串或文本)可分别向前或向后搜索该模式。搜索时也可以使用元字符。下面是一些例子。
- /hello:向前搜索单词 hello。
- ?goodbye:向后搜索单词 goodbye。
- /The.*foot:向前搜索包括单词 The,同时在 The 之后的某处有单词 foot 的行。
- ?[pP]rint:向后搜索 pring 或 Print。记住,Linux 中是区分大小写的,所以可使 用括号来搜索大小写不同的单词。
vi 编辑器最初基于 ex 编辑器,而 ex 编辑器不能完全在全屏幕模式下运行。但是它允 许运行命令,以便同时在一行或者多行中搜索和修改文本。输入冒号并且光标到达屏幕底部 时,实际上就处于 ex 模式下。下面的例子用 ex 命令搜索和修改文本(例如我选择搜索 Local 和 Remote,但也可以使用其它合适的单词)。
- :g/Local:搜索单词 Local,并且打印文件中它所出现的行(如果结果多于一个屏 幕,则以管道形式将输出定向到 more 命令)。
- :s/Local/s//Remote:在当前行上用 Remote 代替 Local。
- :g/Local/s//Remote:用 Remote 代替文件中每行第一次出现的 Local。
- :g/Local/s//Remote/g:用 Remote 代替文件中出现的所有 Local。
- :g/Local/s//Remote/gp:用 Remote 代替文件中出现所有的 Local,然后打印没一行 来查看进行的修改(如果输出多于一页,则以管道的形式将输出定向到 more 命令)。
3.使用命令和数字
在多数 vi 命令前都可以使用数字,这样命令就能够重复执行该指定数目的次数。这是 一次处理多行、多个单词或多个字符的便捷方法。下面是一些例子。
- 3dw:删除下面的 3 个单词。
- 5cl:修改下面的 5 个字母(即删除字母并进入输入模式)。
- 12j:向下移动 12 行。
在多数命令前加上数字只是重复执行这些命令。此时对于使用 vi 命令应该相当精通了。一旦习惯了使用 vi,就会发现其它文本编辑器使用起来效率都不高了。
在很多 Linux 系统中调用 vi 时,实际上正在调用 vim 文本编辑器,它运行在 vi 兼容 模式下。进行大量编程工作的人可能更愿意使用 vim,因为它以不同颜色显示不同的代码层 次。vim 还有一些其它有用的功能,例如在打开文档时,将光标放在最后一次退出文件时光 标所在的位置。
vi 编辑器在开始时很难学,可是一旦掌握了它,就永远不必使用鼠标或功能键了-一 个键盘就可以快速高效的在文件中编辑和移动。
3.3.4 使用 GCC
1.GCC 简介
通常所说的 GCC 是 GUN Compiler Collection 的简称,除了编译程序之外,它还含其 他相关工具,所以它能把易于人类使用的高级语言编写的源代码构建成计算机能够直接执行 的二进制代码。GCC 是 Linux 平台下最常用的编译程序,它是 Linux 平台编译器的事实标准。同时,在 Linux 平台下的嵌入式开发领域,GCC 也是用得最普遍的一种编译器。GCC 之
所以被广泛采用,是因为它能支持各种不同的目标体系结构。例如,它既支持基于宿主的开 发(简单讲就是要为某平台编译程序,就在该平台上编译),也支持交叉编译(即在 A 平台上编译的程序是供平台 B 使用的)。目前,GCC 支持的体系结构有四十余种,常见的有 X86 系列、Arm、 PowerPC 等。同时,GCC 还能运行在不同的操作系统上,如 Linux、 Solaris、Windows 等。
除了上面讲的之外,GCC 除了支持 C 语言外,还支持多种其他语言,例如 C++、Ada、 Java、Objective-C、FORTRAN、Pascal 等。
下面我们将介绍 Linux 平台下应用程序的编译过程,以及使用 GCC 编译应用程序的具 体用法,同时详细说明了 GCC 的常用选项、模式和警告选项。
2.使用 GCC 编译程序的过程
对于 GNU 通用编译器来说,程序的编译要经历预处理、编译、汇编、连接四个阶段, 如下图所示:
从功能上分,预处理、编译、汇编是三个不同的阶段,但 GCC 的实际操作上,它可以 把这三个步骤合并为一个步骤来执行。下面我们以 C 语言为例来谈一下不同阶段的输入和 输出情况。
在预处理阶段,输入的是 C 语言的源文件,通常为.c。它们通常带有.h 之类头文件的 包含文件。这个阶段主要处理源文件中的 #ifdef、 #include 和#define 命令。该阶段会生 成一个中间文件.i,但实际工作中通常不用专门生成这种文件,因为基本上用不到;若非 要生成这种文件不可,可以利用下面的示例命令:
GCC -E test.c -o test.i
在编译阶段,输入的是中间文件.i,编译后生成汇编语言文件.s 。这个阶段对应的GCC 命令如下所示:
GCC -S test.i -o test.s
在汇编阶段,将输入的汇编文件.s 转换成机器语言.o。这个阶段对应的 GCC 命令如下所示:
GCC -c test.s -o test.o
最后,在连接阶段将输入的机器代码文件 *.s(与其它的机器代码文件和库文件)汇集成一个可执行的二进制代码文件。这一步骤,可以利用下面的示例命令完成:
GCC test.o -o test
上面介绍了 GCC 编译过程的四个阶段以及相应的命令。下面我们进一步介绍常用 GCC的模式。
3.GCC 常用模式
这里介绍 GCC 追常用的两种模式:编译模式和编译连接模式。下面以一个例子来说明
各种模式的使用方法。为简单起见,假设我们全部的源代码都在一个文件 test.c 中,要想 把这个源文件直接编译成可执行程序,可以使用以下命令:
$ GCC -o test
这里 test.c 是源文件,生成的可执行代码存放在一个名为 test 的文件中(该文件是
机器代码并且可执行)。-o 是生成可执行文件的输出选项。如果我们只想让源文件生成目 标文件(给文件虽然也是机器代码但不可执行),可以使用标记 -c ,详细命令如下所示:
$ GCC -c test.c
默认情况下,生成的目标文件被命名为 test.o,但我们也可以为输出文件指定名称,
如下所示:
$ GCC -c test.c -o
上面这条命令将编译后的目标文件命名为 mytest.o,而不是默认的 test.o。
迄今为止,我们谈论的程序仅涉及到一个源文件;现实中,一个程序的源代码通常包 含在多个源文件之中,这该怎么办?没关系,即使这样,用 GCC 处理起来也并不复杂,见 下例:
$ GCC -o test first.c second.c third.c
该命令将同时编译 3 个源文件,即 first.c、second.c 和 third.c,然后将它们连接成一个可执行程序,名为 test。
许多情况下,头文件和源文件会单独存放在不同的目录中。例如,假设存放源文件的 子目录名为./src,而包含文件则放在层次的其他目录下,如 ./inc。当我们在./src 目录下 进行编译工作时,如何告诉 GCC 到哪里找头文件呢?方法如下所示:
$ gcc test.c –I../inc -o test
上面的命令告诉 GCC 包含文件存放在./inc 目录下,在当前目录的上一级。如果在编译时需要的包含文件存放在多个目录下,可以使用多个 -I 来指定各个目录:
$ gcc test.c –I../inc –I../../inc2 -o test
这里指出了另一个包含子目录 inc2,较之前目录它还要在再上两级才能找到。
另外,我们还可以在编译命令行中定义符号常量。为此,我们可以简单的在命令行中 使用-D 选项即可,如下例所示:
$ gcc -DTEST_CONFIGURATION test.c -o test
上面的命令与在源文件中加入下列命令是等效的:
#define TEST_CONFIGURATION
在编译命令行中定义符号常量的好处是,不必修改源文件就能改变由符号常量控制的行为。
实际上,GCC 命令提供了非常多的命令选项,但并不是所有都要熟悉,初学时掌握几个常用的就可以了,到后面再慢慢学习其它选项,免得因选项太多而打击了学习的信心。
为了方便读者查阅,这里将常见的编译选项列举如下:
(1) 常用编译命令选项 假设源程序文件名为 test.c。
I. 无选项编译链接 用法:#gcc test.c
作用:将 test.c 预处理、汇编、编译并链接形成可执行文件。这里未指定输出文件, 默认输出为 a.out。
II. 选项 -o
用法:#gcc test.c -o test
作用:将 test.c 预处理、汇编、编译并链接形成可执行文件 test。-o 选项用来指定 输出文件的文件名。
III. 选项 -E
用法:#gcc -E test.c -o test.i 作用:将 test.c 预处理输出 test.i 文件。
IV. 选项 -S
用法:#gcc -S test.i
作用:将预处理输出文件 test.i 汇编成 test.s 文件。
V. 选项 -c
用法:#gcc -c test.s
作用:将汇编输出文件 test.s 编译输出 test.o 文件。
VI. 无选项链接
用法:#gcc test.o -o test
作用:将编译输出文件 test.o 链接成最终可执行文件 test。
VII. 选项-O
用法:#gcc -O1 test.c -o test
作用:使用编译优化级别 1 编译程序。级别为 1~3,级别越大优化效果越好,但编译时 间越长。
(2) 多源文件的编译方法
如果有多个源文件,基本上有两种编译方法 (这里假设有两个源文件为 test.c 和 testfun.c。)。
I. 多个文件一起编译
用法:#gcc testfun.c test.c -o test
作用:将 testfun.c 和 test.c 分别编译后链接成 test 可执行文件。
II. 分别编译各个源文件,之后对编译后输出的目标文件链接。 用法:
#gcc -c testfun.c //将 testfun.c 编译成 testfun.o
#gcc -c test.c //将 test.c 编译成 test.o
#gcc -o testfun.o test.o -o test //将 testfun.o 和 test.o 链接成 test
以上两种方法相比较,第 1 种方法编译时需要所有文件重新编译,而第 2 种方法可以只重新编译修改的文件,未修改的文件不用重新编译。
4.警告功能
当 GCC 在编译过程中检查出错误的话,它就会中止编译;但检测到警告时却能继续编 译生成可执行程序,因为警告只是针对程序结构的诊断信息,它不能说明程序一定有错误, 而是存在风险,或者可能存在错误。虽然 GCC 提供了非常丰富的警告,但前提是你已经启 用了它们,否则它不会报告这些检测到的警告。
在众多的警告选项之中,最常用的就是 -Wall 选项。该选项能发现程序中一系列的常见 错误警告,该选项用法举例如下:
$ gcc -Wall test.c -o test
该选项相当于同时使用了下列所有的选项:
- unused-function:遇到仅声明过但尚未定义的静态函数时发出警告。
- unused-label:遇到声明过但不使用的标号的警告。
- unused-parameter:从未用过的函数参数的警告。
- unused-variable:在本地声明但从未用过的变量的警告。
- unused-value:仅计算但从未用过的值得警告。
- Format:检查对 printf 和 scanf 等函数的调用,确认各个参数类型和格式串中的 一致。
- implicit-int:警告没有规定类型的声明。
- implicit-function-:在函数在未经声明就使用时给予警告。
- char-subscripts:警告把 char 类型作为数组下标。这是常见错误,程序员经常忘记在某些机器上 char 有符号。
- missing-braces:聚合初始化两边缺少大括号。
- Parentheses:在某些情况下如果忽略了括号,编译器就发出警告。
- return-type:如果函数定义了返回类型,而默认类型是 int 型,编译器就发出警 告。同时警告那些不带返回值的 return 语句,如果他们所属的函数并非 void 类型。
- sequence-point:出现可疑的代码元素时,发出报警。
- Switch:如果某条 switch 语句的参数属于枚举类型,但是没有对应的 case 语句使 用枚举元素,编译器就发出警告(在 switch 语句中使用 default 分支能够防止这个警 告)。超出枚举范围的 case 语句同样会导致这个警告。
- strict-aliasing:对变量别名进行最严格的检查。
- unknown-pragmas:使用了不允许的#pragma。
- Uninitialized:在初始化之前就使用自动变量。
需要注意的是,各警告选项既然能使之生效,当然也能使之关闭。比如假设我们想要使用-Wall 来启用个选项,同时又要关闭 unused 警告,可以通过下面的命令来达到目的:
$ gcc -Wall -Wno-unused test.c -o test
下面是使用-Wall 选项的时候没有生效的一些警告项:
- cast-align:一旦某个指针类型强制转换时,会导致目标所需的地址对齐边界扩 展,编译器就发出警告。例如,某些机器上只能在 2 或 4 字节边界上访问整数,如果在这 种机型上把 char 强制转换成 int 类型, 编译器就发出警告。
- sign-compare:将有符号类型和无符号类型数据进行比较时发出警告。
- missing-prototypes :如果没有预先声明函数原形就定义了全局函数,编译器就 发出警告。即使函数定义自身提供了函数原形也会产生这个警告。这样做的目的是检查没有 在头文件中声明的全局函数。
- Packed:当结构体带有 packed 属性但实际并没有出现紧缩式给出警告。
- Padded:如果结构体通过充填进行对齐则给出警告。
- unreachable-code:如果发现从未执行的代码时给出警告。
- Inline:如果某函数不能内嵌(inline),无论是声明为 inline 或者是指定了- finline-functions 选项,编译器都将发出警告。
- disabled-optimization:当需要太长时间或过多资源而导致不能完成某项优化时 给出警告。
上面是使用-Wall 选项时没有生效,但又比较常用的一些警告选项。本文中要介绍的最后一个常用警告选项是-Werror。使用该选项后,GCC 发现可疑之处时不会简单的发出警告就算完事,而是将警告作为一个错误而中断编译过程。该选项在希望得到高质量代码时非常 有用。
3.3.5 使用 GDB
1.概述
GDB 是 GNU 开源组织发布的在 Linux 系统下用来调试 C 和 C++程序的强力调试器,它 可以在程序运行时用来观察程序的内部结构和内存等的使用情况。
一般来说,GDB 主要帮助程序员完成以下 4 个方面的工作:
(1) 启动程序,可以按照自定义的要求运行程序;
(2) 在被调试的程序所指定的断点处停止;
(3) 程序停止时检查此时程序中所发生的事件;
(4) 动态的改变程序执行环境。
在命令行上输入“gdb”并按回车键就可以运行 GDB 了,如果一切正常的话 GDB 将被启 动并且将在屏幕上显示如下内容:
#gdb
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
当启动 GDB 后,在命令行上可以指定很多的选项,也可以下面的形式来运行 GDB:
GDB <程序名>
当用这种方式运行 GDB 时,能直接指定想要调试的程序,GDB 将装入某个可执行文件。
GDB 也可以检查一个因程序异常终止而产生的 core 文件。
为了使 GDB 正常工作,必须使程序在编译时包含调试信息。调试信息包含程序里的每 个变量的类型和在可执行文件里面的地址映射以及源代码的行号, GDB 利用这些信息使源代 码和机器码相关联。在编译用“-g”选项打开调试选项。
2.GDB 基本命令
GDB 支持很多的命令,能实现不同的功能。表 2-1 列出了 GDB 调试时常用的一些命令。
表 3-8 GDB 基本命令
| 命令 | 含义 |
|---|---|
| backtrace | 显示函数调用的所有栈框架的踪迹和当前函数的参数值 |
| break | 设置一个断点,这个命令需要指定代码行或者函数名作为参数 |
| clear | 删除一个断点,这个命令需要指定代码行或者函数名作为参数 |
| continue | 在调试器停止的地方继续执行 |
| Ctrl+C | 在当前位置停止执行正在执行的程序,断点在当前行 |
| disable | 禁止断点功能,这个命令需要禁止的断点在断点列表索引值作为参数 |
| display | 在断点停止的地方显式指定的表达式的值 |
| enable | 允许断点功能,这个命令需要禁止的断点在断点列表索引值作为参数 |
| finish | 继续执行,直到当前函数返回 |
| ignore | 忽略某个断点制定的次数。例如:“ignore4 23”忽略断点 4 的 23 次运行,在第 24 此运行时中断 |
| Info breakpoints | 查看断点信息 |
| Info display | 查看设置的需要显式的表达式的信息 |
| kill | 终止当前 debug 进程 |
| list | 显示 10 行代码。如果没有提供参数给这个命令,则从当前行开始显示 10 行代码。如果提供了函数名作为参数,则从函数开头显示。如果提供代码行的编号作为参数,这一行作为开头显示 |
| load | 动态载入一个可执行文件到调试器 |
| next | 执行下一行的源代码的所有指令。如果是函数调用,则也当作一行源代码,执行到此函数返回 |
| nexti | 执行下一行源代码中的一条汇编指令 |
| 显式变量的值 | |
| ptype | 显示变量的类型 |
| return | 强制从当前函数返回 |
| run | 从程序开始的地方执行 |
| rwatch | 指定一个变量,如果这个变量被读,则暂停程序运行,在调试器中显示信息,并等待下一个调试指令,参考 rwatch 和 watch 命令 |
| set | 设置变量的值。例如:“set nval=54”将把 54 保存到 nval 变量中 |
| step | 继续执行程序下一行源代码的所有指令。如果是调用函数,这个命令将进入函数的内部,单步执行函数中的代码 |
| stepi | 继续执行程序下一行源代码的汇编指令。如果是调用函数,这个命令将进入函数的内部,单步执行函数中的代码 |
| txbreak | 在当前函数的退出点上设置一个临时断点(只可使用一次) |
| undisplay | 删除一个 display 设置的变量显示,这个命令需要将 display list 中的索引作为参数 |
| watch | 指定一个变量,如果这个变量被写,则暂停程序运行,在调试器中显示信息,并等待下一个调试命令,参考 rwatch 和 watch 命令 |
| whatis | 显示变量的值和类型 |
| xbreak | 在当前函数的退出点上设置一个断点 |
| awatch | 指定一个变量,如果这个变量被读写,则暂停程序运行,在调试器中显示信息,并等待下一个调试命令,参考 rwatch 和 watch 命令 |
3.GDB 的操作
GDB 支持很多与 shell 程序一样的命令编辑特征。能像在 Bash 里那样按“Tab”键让 GDB 补齐一个唯一的命令。如果该命令不唯一的话, GDB 会列出所有匹配的命令,也能用光 标键上下翻动历史命令。更为详尽的内容,请查阅 GDB 的帮助。
4.GDB 应用举例
本小节通过一个实例一步步的用 GDB 调试程序。下面是将被调试的程序,这个程序被 称为 greeting.c,它显示一个简单的问候,再用反序将它列出。
#include <stdio.h>
#filename.greeting.c
main()
{
char my_string[] = "hello there";
my_print (my_string);
my_print2 (my_string);
}
void my_print(char *string)
{
printf("The string is %s\n",string);
}
void my_print2(char *string)
{
char *string2;
int size,i;
size = strlen(string);
string2 = (char *) malloc(size+1);
for ( i=0;i<size;i++)
{
string2[size -i] = string[i];
string2[size+1] = '\0';
printf("The string printed backward is %s\n",string2);
}
}
用命令编译它:
#gcc -o test test.c
这个程序执行时显示如下结果:
The string is hello there
The string printed backward is
输出的第一行是正确的,但第二行打印出来的东西并不是所期望的,所设想的输出应该是:
The string printed backward is ereht olleh
由于某些原因,my_print2 函数没有正常工作。用 GDB 查看问题究竟出在哪儿,先输入如下命令:
#gdb greeting
注意,在编译 greeting 程序时需要把调试程序打开
如果在输入命令时忘了把要调试的程序作为参数传递给 GDB,可以在 GDB 提示符下用 file 命令载入它:
(gdb) file greeting
这个命令将载入 greeting 可执行文件,就像在 GDB 命令行里装入它一样。
这时可以用 GDB 的 run 命令运行 greeting 了,其在 GDB 里被运行后结果如下:
(gdb) run
Starting program: /root/geeeting
The string is hello there
The string printed backward is
Program exited with code p41
这个输出和在 GDB 外面运行的结果一样,但为什么反序打印却没有工作呢?为了找出症结所在,可以在 my_pringt2 函数的 for 语句后设一个断点,具体的做法是在 gdb 提示符 下键入 list 命令 3 次,列出源代码,如下所示:
(gdb) list
(gdb) list
(gdb) list
第一次输入 list 命令的输出如下:
#include <stdio.h>
main()
{
char my_string[] = "hello there";
my_print(my_string);
my_print2(my_string);
}
如果按下回车,GDB 将再执行一次 list 命令,输出如下:
my_print(char *string)
{
printf("The string is %s\n",string);
}
my_print2(char *string)
{
char *string2;
Int size,i;
}
再按一次一次回车将列出 greeting 程序的剩余部分,如下所示:
size = strlen(strint);
string2 = (char*)malloc(size+1);
for(i=0;i<size;i++)
{
string2[size-i] = string[i];
string2[size+1] = '\0';
printf("The string printed backward is %s\n",string2);
}
从列出的源程序可以看到要设断点的地方在第 24 行,在 GDB 命令行提示符下输入如下命令设置断点:
(gdb) break 24
GDB 将作出如下的响应:
Breakpoint 1 at 0x139: file greeting.c,line24
(gdb)
现在再输入 run 命令,将产生如下的输出:
Starting program:/root/greeting
The string is hello there
Breakpoint 1,my_print2(string = 0xbfffdc4 "hello there") at greeting.c :24
24 string2[size-i] = string[i];
能通过设置一个观察 string2[size-i]变量值的观察点来查看错误是怎样产生的,输入一下指令:
(gdb) watch string2[size-i];
GDB 将作出如下回应:
Watchpoint 2:string2[size-i]
现在可以用 next 命令一步一步的执行 for 循环了,如下所示:
(gdb) next
经过第一次循环后:GDB 告诉我们 string2[size-i]的值是 h。GDB 用如下的显示来告诉这个信息:
Watchpoint 2,string2[size-i]
Old value=0 '\000'
New value = 104 'h'
my_print2(string = 0xbfffdc4 "hello there") at greeting.c:23
23 for ( i= 0;i<size; i++ )
这个值正是期望的,后来的数次循环的结果都是正确的。当 i=10 时,表达式string2[size-i]的值等于 e,size-i 的值等于 1,最后 1 个字符已经复制到字符串里了。
如果再把循环执行下去,会看到已经没有值分配给 string2[0]了,而它是字符串的第 1 个字符,因为 malloc()函数在分配内存时把它们初始化为空 (null)字符,所以 string2 的第 1 个字符是空字符,这就解释了打印 string2 时没有任何输出的原因。
现在找出了问题在哪里,改正这个错误很容易。需要把代码里写入 string2 的第 1 个 字符的偏移量改为 size-1。
使代码正常工作有很多种修改方法。一种是另设一个比实际大小小 1 的变量,这种解 决办法的代码如下:
#include <stdio.h>
main()
{
char my_string[] = "hello there";
my_print(my_string);
my_print2(my_string);
}
my_print(char *string)
{
printf("The string is %s\n",string);
}
my_print2(char *string)
{
char *string2;
int size,size2,i;
size = strlen(string);
size2 = size-1;
string2 = (char*)malloc(size+1);
for( i = 0;i<size;i++ )
{
string2[size-i] = string[i];
}
string2[size] = '\0';
printf("The string printed backward is %s\n",string2);
}