Intro
- Graphs defined in Python, executed in C++
- Open-sourced 2015. Windows, Linux, macOS, iOS, Android
- Python API: tensorflow.contrib.learn (trains NNs)
- Simpler API: tensorflow.contrib.slim (simplifies building NNs)
- Other high-level APIs: Keras, Pretty Tensor.
- Libraries: Caffe, DeepLearning4J, H2O, MXNet, Theano, Torch
- TensorBoard visualization tool
- Cloud service
- Resources: home page, GitHub, StackOverflow
Installation & Test
$ cd
$ source env/bin/activate (if using virtualenv)
$ pip3 install --upgrade tensorflow (or tensorflow-gpu for GPU support)
$ python3 -c 'import tensorflow; print(tensorflow.version)'
!python3 -c 'import tensorflow; print(tensorflow.__version__)'
1.0.0
import numpy as np
First Graph
# create your first graph
import tensorflow as tf
x = tf.Variable(3, name="x")
y = tf.Variable(4, name="y")
f = x*x*y + y + 2
# run graph by opening a session
sess = tf.Session()
sess.run(x.initializer)
sess.run(y.initializer)
result = sess.run(f)
print(result)
sess.close()
42
# for repeated session "runs"
with tf.Session() as sess:
x.initializer.run()
y.initializer.run()
result = f.eval()
print(result)
42
# use global_variables_initializer() to set up initialization
init = tf.global_variables_initializer()
with tf.Session() as sess:
init.run() # actually initialize all the variables
result = f.eval()
print(result)
42
# interactive sessions (from within Jupyter or Python shell)
# interactive sesions are auto-set as default sessions
sess = tf.InteractiveSession()
init.run()
result = f.eval()
print(result)
sess.close()
42
Managing Graphs
# any created node = added to default graph
x1 = tf.Variable(1)
x1.graph is tf.get_default_graph()
True
# handling multiple graphs
graph = tf.Graph()
with graph.as_default():
x2 = tf.Variable(2)
x2.graph is graph, x2.graph is tf.get_default_graph()
(True, False)
Node Lifecycles
# TF finds node's dependencies & evaluates them first
w = tf.constant(3)
x = w + 2
y = x + 5
z = x * 3
# previous eval results = NOT reused. above code evals w & x twice.
with tf.Session() as sess:
print(y.eval())
print(z.eval())
# a more efficient evaluation call:
with tf.Session() as sess:
y_val, z_val = sess.run([y,z])
print(y_val)
print(z_val)
10
15
10
15
Linear Regression with TF
- TF ops take any number of inputs & produce any number of outputs
- Constants & variables = source ops (no inputs)
- Inputs & outputs = multidimensional "tensors" = NumPy ndarrays in Python API. Typically floats, can also be strings.
Below: Linear Regression on 2D arrays (California Housing dataset)
# (never used Numpy c_ operator before. Had to check it out.)
a = np.ones((6,1))
b = np.zeros((6,4))
c = np.ones((6,2))
np.c_[a,b,c]
array([[ 1., 0., 0., 0., 0., 1., 1.],
[ 1., 0., 0., 0., 0., 1., 1.],
[ 1., 0., 0., 0., 0., 1., 1.],
[ 1., 0., 0., 0., 0., 1., 1.],
[ 1., 0., 0., 0., 0., 1., 1.],
[ 1., 0., 0., 0., 0., 1., 1.]])
from sklearn.datasets import fetch_california_housing
import numpy as np
housing = fetch_california_housing()
m, n = housing.data.shape
# add bias feature, x0 = 1
housing_data_plus_bias = np.c_[np.ones((m, 1)), housing.data]
print(m,n,housing_data_plus_bias.shape)
20640 8 (20640, 9)
tf.reset_default_graph()
X = tf.constant(
housing_data_plus_bias,
dtype=tf.float64, name="X")
print("X shape: ",X.shape)
# housing.target = 1D array. Reshape to col vector to compute theta.
# reshape() accepts -1 = "unspecified" for a dimension.
y = tf.constant(
housing.target.reshape(-1, 1),
dtype=tf.float64, name="y")
XT = tf.transpose(X)
print("XT shape: ",XT.shape)
# normal equation: theta = (XT * X)^-1 * XT * y
theta = tf.matmul(
tf.matmul(
tf.matrix_inverse(
tf.matmul(XT, X)),
XT),
y)
# TF doesn't immediately run the code. It creates nodes that will run with eval().
# TF will auto-run on GPU if available.
with tf.Session() as sess:
result = theta.eval()
print("theta: \n",result)
X shape: (20640, 9)
XT shape: (9, 20640)
theta:
[[ -3.69419202e+01]
[ 4.36693293e-01]
[ 9.43577803e-03]
[ -1.07322041e-01]
[ 6.45065694e-01]
[ -3.97638942e-06]
[ -3.78654265e-03]
[ -4.21314378e-01]
[ -4.34513755e-01]]
# compare to pure NumPy
X = housing_data_plus_bias
y = housing.target.reshape(-1, 1)
theta_numpy = np.linalg.inv(X.T.dot(X)).dot(X.T).dot(y)
print("theta: \n",theta_numpy)
theta:
[[ -3.69419202e+01]
[ 4.36693293e-01]
[ 9.43577803e-03]
[ -1.07322041e-01]
[ 6.45065694e-01]
[ -3.97638942e-06]
[ -3.78654265e-03]
[ -4.21314378e-01]
[ -4.34513755e-01]]
# compare to Scikit
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(
housing.data,
housing.target.reshape(-1, 1))
print("theta: \n",np.r_[
lin_reg.intercept_.reshape(-1, 1),
lin_reg.coef_.T])
theta:
[[ -3.69419202e+01]
[ 4.36693293e-01]
[ 9.43577803e-03]
[ -1.07322041e-01]
[ 6.45065694e-01]
[ -3.97638942e-06]
[ -3.78654265e-03]
[ -4.21314378e-01]
[ -4.34513755e-01]]
Batch Gradient Descent (instead of Normal Equation):
- Could use TF; let's use Scikit first.
# normalize input features first - otherwise training = much slower.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaled_housing_data = scaler.fit_transform(
housing.data)
scaled_housing_data_plus_bias = np.c_[
np.ones((m, 1)),
scaled_housing_data]
import pandas as pd
pd.DataFrame(scaled_housing_data_plus_bias).info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 20640 entries, 0 to 20639
Data columns (total 9 columns):
0 20640 non-null float64
1 20640 non-null float64
2 20640 non-null float64
3 20640 non-null float64
4 20640 non-null float64
5 20640 non-null float64
6 20640 non-null float64
7 20640 non-null float64
8 20640 non-null float64
dtypes: float64(9)
memory usage: 1.4 MB
print("mean (axis=0): \n",scaled_housing_data_plus_bias.mean(axis=0))
print("mean (axis=1): \n",scaled_housing_data_plus_bias.mean(axis=1))
print("mean (w/bias): \n",scaled_housing_data_plus_bias.mean())
print("data shape: \n",scaled_housing_data_plus_bias.shape)
mean (axis=0):
[ 1.00000000e+00 6.60969987e-17 5.50808322e-18 6.60969987e-17
-1.06030602e-16 -1.10161664e-17 3.44255201e-18 -1.07958431e-15
-8.52651283e-15]
mean (axis=1):
[ 0.38915536 0.36424355 0.5116157 ..., -0.06612179 -0.06360587
0.01359031]
mean (w/bias):
0.111111111111
data shape:
(20640, 9)
Manual gradient computation
# batch gradient step:
# theta(next) = theta - learning_rate * MSE(theta)
tf.reset_default_graph()
n_epochs = 1000
learning_rate = 0.01
X = tf.constant(
scaled_housing_data_plus_bias,
dtype=tf.float32, name="X")
y = tf.constant(
housing.target.reshape(-1, 1),
dtype=tf.float32, name="y")
theta = tf.Variable( # tf.random_uniform = generates random tensor
tf.random_uniform([n+1, 1], -1.0, 1.0, seed=42),
name="theta")
y_pred = tf.matmul(
X, theta, name="predictions")
error = y_pred - y
mse = tf.reduce_mean(tf.square(error), name="mse")
gradients = 2/m * tf.matmul(tf.transpose(X), error)
training_op = tf.assign(theta, theta - learning_rate * gradients)
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for epoch in range(n_epochs):
if epoch % 100 == 0: # do every 100th epoch:
print("Epoch", epoch, "MSE =", mse.eval())
sess.run(training_op)
best_theta = theta.eval()
print("Best theta: \n",best_theta)
Epoch 0 MSE = 2.75443
Epoch 100 MSE = 0.632222
Epoch 200 MSE = 0.57278
Epoch 300 MSE = 0.558501
Epoch 400 MSE = 0.549069
Epoch 500 MSE = 0.542288
Epoch 600 MSE = 0.537379
Epoch 700 MSE = 0.533822
Epoch 800 MSE = 0.531243
Epoch 900 MSE = 0.529371
Best theta:
[[ 2.06855226e+00]
[ 7.74078071e-01]
[ 1.31192386e-01]
[ -1.17845096e-01]
[ 1.64778158e-01]
[ 7.44080753e-04]
[ -3.91945168e-02]
[ -8.61356616e-01]
[ -8.23479712e-01]]
Using autodiff
- automatically finds gradients. Note the different gradients assignment.
tf.reset_default_graph()
n_epochs = 1000
learning_rate = 0.01
X = tf.constant(
scaled_housing_data_plus_bias,
dtype=tf.float32, name="X")
y = tf.constant(
housing.target.reshape(-1, 1),
dtype=tf.float32, name="y")
theta = tf.Variable(
tf.random_uniform([n + 1, 1], -1.0, 1.0,
seed=42), name="theta")
y_pred = tf.matmul(
X, theta, name="predictions")
error = y_pred - y
mse = tf.reduce_mean(tf.square(error), name="mse")
# AutoDiff to the rescue
# creates list of ops, one/variable, to find gradients per variable
gradients = tf.gradients(mse, [theta])[0]
#
training_op = tf.assign(theta, theta - learning_rate * gradients)
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for epoch in range(n_epochs):
if epoch % 100 == 0:
print("Epoch", epoch, "MSE =", mse.eval())
sess.run(training_op)
best_theta = theta.eval()
print("Best theta: \n", best_theta)
Epoch 0 MSE = 2.75443
Epoch 100 MSE = 0.632222
Epoch 200 MSE = 0.57278
Epoch 300 MSE = 0.558501
Epoch 400 MSE = 0.549069
Epoch 500 MSE = 0.542288
Epoch 600 MSE = 0.537379
Epoch 700 MSE = 0.533822
Epoch 800 MSE = 0.531243
Epoch 900 MSE = 0.529371
Best theta:
[[ 2.06855249e+00]
[ 7.74078071e-01]
[ 1.31192386e-01]
[ -1.17845066e-01]
[ 1.64778143e-01]
[ 7.44078017e-04]
[ -3.91945094e-02]
[ -8.61356676e-01]
[ -8.23479772e-01]]
Four ways to run autodiff - see Appendix D
- reverse-mode (default): best for many inputs, few outputs
- symbolic diff: high accuracy
- forward mode: high accuracy
- numerical diff: low accuracy, but trivial to implement
Using a predefined optimizer (Gradient Descent)
tf.reset_default_graph()
n_epochs = 1000
learning_rate = 0.01
X = tf.constant(
scaled_housing_data_plus_bias,
dtype=tf.float32, name="X")
y = tf.constant(
housing.target.reshape(-1, 1),
dtype=tf.float32, name="y")
theta = tf.Variable(
tf.random_uniform([n + 1, 1], -1.0, 1.0, seed=42),
name="theta")
y_pred = tf.matmul(
X, theta, name="predictions")
error = y_pred - y
mse = tf.reduce_mean(tf.square(error), name="mse")
#####
optimizer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate)
training_op = optimizer.minimize(mse)
#####
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for epoch in range(n_epochs):
if epoch % 100 == 0:
print("Epoch", epoch, "MSE =", mse.eval())
sess.run(training_op)
best_theta = theta.eval()
print("Best theta:\n", best_theta)
Epoch 0 MSE = 2.75443
Epoch 100 MSE = 0.632222
Epoch 200 MSE = 0.57278
Epoch 300 MSE = 0.558501
Epoch 400 MSE = 0.549069
Epoch 500 MSE = 0.542288
Epoch 600 MSE = 0.537379
Epoch 700 MSE = 0.533822
Epoch 800 MSE = 0.531243
Epoch 900 MSE = 0.529371
Best theta:
[[ 2.06855249e+00]
[ 7.74078071e-01]
[ 1.31192386e-01]
[ -1.17845066e-01]
[ 1.64778143e-01]
[ 7.44078017e-04]
[ -3.91945094e-02]
[ -8.61356676e-01]
[ -8.23479772e-01]]
Using a predefined optimizer (Momentum)
tf.reset_default_graph()
n_epochs = 1000
learning_rate = 0.01
X = tf.constant(
scaled_housing_data_plus_bias,
dtype=tf.float32, name="X")
y = tf.constant(
housing.target.reshape(-1, 1),
dtype=tf.float32, name="y")
theta = tf.Variable(
tf.random_uniform([n + 1, 1], -1.0, 1.0, seed=42),
name="theta")
y_pred = tf.matmul(X, theta, name="predictions")
error = y_pred - y
mse = tf.reduce_mean(tf.square(error), name="mse")
#####
optimizer = tf.train.MomentumOptimizer(
learning_rate=learning_rate,
momentum=0.25)
#####
training_op = optimizer.minimize(mse)
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for epoch in range(n_epochs):
sess.run(training_op)
best_theta = theta.eval()
print("Best theta:\n", best_theta)
Best theta:
[[ 2.06855392e+00]
[ 7.94067979e-01]
[ 1.25333667e-01]
[ -1.73580602e-01]
[ 2.18767926e-01]
[ -1.64708309e-03]
[ -3.91250364e-02]
[ -8.85289013e-01]
[ -8.50607991e-01]]
Training & Data Feeds
- Goal: modify previous code for Minibatch gradient descent
- Best practice: placeholder nodes (no computation, just data output)
A = tf.placeholder(tf.float32, shape=(None, 3))
B = A + 5
with tf.Session() as sess:
B_val_1 = B.eval(
feed_dict={A: [[1, 2, 3]]})
B_val_2 = B.eval(
feed_dict={A: [[4, 5, 6], [7, 8, 9]]})
print(B_val_1, "\n", B_val_2)
[[ 6. 7. 8.]]
[[ 9. 10. 11.]
[ 12. 13. 14.]]
# definition phase: change X,y to placeholder nodes
tf.reset_default_graph()
n_epochs = 1000
learning_rate = 0.01
##########
X = tf.placeholder(tf.float32, shape=(None, n+1), name="X")
y = tf.placeholder(tf.float32, shape=(None, 1), name="y")
##########
theta = tf.Variable(
tf.random_uniform([n+1, 1], -1.0, 1.0, seed=42),
name="theta")
y_pred = tf.matmul(
X, theta, name="predictions")
error = y_pred - y
mse = tf.reduce_mean(tf.square(error), name="mse")
optimizer = tf.train.GradientDescentOptimizer(
learning_rate=learning_rate)
training_op = optimizer.minimize(mse)
init = tf.global_variables_initializer()
# execution phase: fetch minibatches one-by-one.
# use feed_dict to provide values to dependent nodes
import numpy.random as rnd
n_epochs = 10
batch_size = 100
n_batches = int(np.ceil(m / batch_size))
print("m: ",m,"\n","n_batches: ",n_batches,"\n")
def fetch_batch(epoch, batch_index, batch_size):
rnd.seed(epoch * n_batches + batch_index)
indices = rnd.randint(m, size=batch_size)
X_batch = scaled_housing_data_plus_bias[indices]
y_batch = housing.target.reshape(-1, 1)[indices]
return X_batch, y_batch
with tf.Session() as sess:
sess.run(init)
for epoch in range(n_epochs):
for batch_index in range(n_batches):
X_batch, y_batch = fetch_batch(
epoch, batch_index, batch_size)
sess.run(
training_op,
feed_dict={X: X_batch, y: y_batch})
best_theta = theta.eval()
print("Best theta: \n",best_theta)
m: 20640
n_batches: 207
Best theta:
[[ 2.07001591]
[ 0.82045609]
[ 0.1173173 ]
[-0.22739051]
[ 0.31134021]
[ 0.00353193]
[-0.01126994]
[-0.91643935]
[-0.87950081]]
Model Save/Restore
- Use a saver node once construction is complete.
- call save() method - pass it session and filepath info.
tf.reset_default_graph()
n_epochs = 1000
learning_rate = 0.01
X = tf.constant(
scaled_housing_data_plus_bias,
dtype=tf.float32, name="X")
y = tf.constant(
housing.target.reshape(-1, 1),
dtype=tf.float32, name="y")
theta = tf.Variable(
tf.random_uniform([n+1, 1], -1.0, 1.0, seed=42),
name="theta")
y_pred = tf.matmul(
X, theta, name="predictions")
error = y_pred - y
mse = tf.reduce_mean(
tf.square(error),
name="mse")
optimizer = tf.train.GradientDescentOptimizer(
learning_rate=learning_rate)
training_op = optimizer.minimize(mse)
init = tf.global_variables_initializer()
saver = tf.train.Saver()
# can specify which vars to save:
# saver = tf.train.Saver({"weights": theta})
with tf.Session() as sess:
sess.run(init)
for epoch in range(n_epochs):
if epoch % 100 == 0:
print("Epoch", epoch, "MSE =", mse.eval())
save_path = saver.save(sess, "/tmp/my_model.ckpt")
sess.run(training_op)
best_theta = theta.eval()
save_path = saver.save(sess, "my_model_final.ckpt")
print("Best theta:\n",best_theta)
# model restoration:
# 1) create Saver at end of construction phase
# 2) call saver.restore() at start of execution
Epoch 0 MSE = 2.75443
Epoch 100 MSE = 0.632222
Epoch 200 MSE = 0.57278
Epoch 300 MSE = 0.558501
Epoch 400 MSE = 0.549069
Epoch 500 MSE = 0.542288
Epoch 600 MSE = 0.537379
Epoch 700 MSE = 0.533822
Epoch 800 MSE = 0.531243
Epoch 900 MSE = 0.529371
Best theta:
[[ 2.06855249e+00]
[ 7.74078071e-01]
[ 1.31192386e-01]
[ -1.17845066e-01]
[ 1.64778143e-01]
[ 7.44078017e-04]
[ -3.91945094e-02]
[ -8.61356676e-01]
[ -8.23479772e-01]]
!cat checkpoint
model_checkpoint_path: "my_model_final.ckpt"
all_model_checkpoint_paths: "/tmp/my_model.ckpt"
all_model_checkpoint_paths: "my_model_final.ckpt"
Visualization - inside Jupyter
from IPython.display import clear_output, Image, display, HTML
def strip_consts(graph_def, max_const_size=32):
"""Strip large constant values from graph_def."""
strip_def = tf.GraphDef()
for n0 in graph_def.node:
n = strip_def.node.add()
n.MergeFrom(n0)
if n.op == 'Const':
tensor = n.attr['value'].tensor
size = len(tensor.tensor_content)
if size > max_const_size:
tensor.tensor_content = b"<stripped %d bytes>"%size
return strip_def
def show_graph(graph_def, max_const_size=32):
"""Visualize TensorFlow graph."""
if hasattr(graph_def, 'as_graph_def'):
graph_def = graph_def.as_graph_def()
strip_def = strip_consts(graph_def, max_const_size=max_const_size)
code = """
<script>
function load() {{
document.getElementById("{id}").pbtxt = {data};
}}
</script>
<link rel="import" href="https://tensorboard.appspot.com/tf-graph-basic.build.html" onload=load()>
<div style="height:600px">
<tf-graph-basic id="{id}"></tf-graph-basic>
</div>
""".format(data=repr(str(strip_def)), id='graph'+str(np.random.rand()))
# original was width=1200px, height=620px
iframe = """
<iframe seamless style="width:1200px;height:620px;border:0" srcdoc="{}"></iframe>
""".format(code.replace('"', '"'))
display(HTML(iframe))
show_graph(tf.get_default_graph())
<iframe seamless style="width:1200px;height:620px;border:0" srcdoc="
<script>
function load() {
document.getElementById("graph0.1784179106002547").pbtxt = 'node {\n name: "X"\n op: "Const"\n attr {\n key: "dtype"\n value {\n type: DT_FLOAT\n }\n }\n attr {\n key: "value"\n value {\n tensor {\n dtype: DT_FLOAT\n tensor_shape {\n dim {\n size: 20640\n }\n dim {\n size: 9\n }\n }\n tensor_content: "<stripped 743040 bytes>"\n }\n }\n }\n}\nnode {\n name: "y"\n op: "Const"\n attr {\n key: "dtype"\n value {\n type: DT_FLOAT\n }\n }\n attr {\n key: "value"\n value {\n tensor {\n dtype: DT_FLOAT\n tensor_shape {\n dim {\n size: 20640\n }\n dim {\n size: 1\n }\n }\n tensor_content: "<stripped 82560 bytes>"\n }\n }\n }\n}\nnode {\n name: "random_uniform/shape"\n op: "Const"\n attr {\n key: "dtype"\n value {\n type: DT_INT32\n }\n }\n attr {\n key: "value"\n value {\n tensor {\n dtype: DT_INT32\n tensor_shape {\n dim {\n size: 2\n }\n }\n tensor_content: "\\t\\000\\000\\000\\001\\000\\000\\000"\n }\n }\n }\n}\nnode {\n name: "random_uniform/min"\n op: "Const"\n attr {\n key: "dtype"\n value {\n type: DT_FLOAT\n }\n }\n attr {\n key: "value"\n value {\n tensor {\n dtype: DT_FLOAT\n tensor_shape {\n }\n float_val: -1.0\n }\n }\n }\n}\nnode {\n name: "random_uniform/max"\n op: "Const"\n attr {\n key: "dtype"\n value {\n type: DT_FLOAT\n }\n }\n attr {\n key: "value"\n value {\n tensor {\n dtype: DT_FLOAT\n tensor_shape {\n }\n float_val: 1.0\n }\n }\n }\n}\nnode {\n name: "random_uniform/RandomUniform"\n op: "RandomUniform"\n input: "random_uniform/shape"\n attr {\n key: "T"\n value {\n type: DT_INT32\n }\n }\n attr {\n key: "dtype"\n value {\n type: DT_FLOAT\n }\n }\n attr {\n key: "seed"\n value {\n i: 87654321\n }\n }\n attr {\n key: "seed2"\n value {\n i: 42\n }\n }\n}\nnode {\n name: "random_uniform/sub"\n op: "Sub"\n input: "random_uniform/max"\n input: "random_uniform/min"\n attr {\n key: "T"\n value {\n type: DT_FLOAT\n }\n }\n}\nnode {\n name: "random_uniform/mul"\n op: "Mul"\n input: "random_uniform/RandomUniform"\n input: "random_uniform/sub"\n attr {\n key: "T"\n value {\n type: DT_FLOAT\n }\n }\n}\nnode {\n name: "random_uniform"\n op: "Add"\n input: "random_uniform/mul"\n input: "random_uniform/min"\n attr {\n key: "T"\n value {\n type: DT_FLOAT\n }\n }\n}\nnode {\n name: "theta"\n op: "VariableV2"\n attr {\n key: "container"\n value {\n s: ""\n }\n }\n attr {\n key: "dtype"\n value {\n type: DT_FLOAT\n }\n }\n attr {\n key: "shape"\n value {\n shape {\n dim {\n size: 9\n }\n dim {\n size: 1\n }\n }\n }\n }\n attr {\n key: "shared_name"\n value {\n s: ""\n }\n }\n}\nnode {\n name: "theta/Assign"\n op: "Assign"\n input: "theta"\n input: "random_uniform"\n attr {\n key: "T"\n value {\n type: DT_FLOAT\n }\n }\n attr {\n key: "_class"\n value {\n list {\n s: "loc:@theta"\n }\n }\n }\n attr {\n key: "use_locking"\n value {\n b: true\n }\n }\n attr {\n key: "validate_shape"\n value {\n b: true\n }\n }\n}\nnode {\n name: "theta/read"\n op: "Identity"\n input: "theta"\n attr {\n key: "T"\n value {\n type: DT_FLOAT\n }\n }\n attr {\n key: "_class"\n value {\n list {\n s: "loc:@theta"\n }\n }\n }\n}\nnode {\n name: "predictions"\n op: "MatMul"\n input: "X"\n input: "theta/read"\n attr {\n key: "T"\n value {\n type: DT_FLOAT\n }\n }\n attr {\n key: "transpose_a"\n value {\n b: false\n }\n }\n attr {\n key: "transpose_b"\n value {\n b: false\n }\n }\n}\nnode {\n name: "sub"\n op: "Sub"\n input: "predictions"\n input: "y"\n attr {\n key: "T"\n value {\n type: DT_FLOAT\n }\n }\n}\nnode {\n name: "Square"\n op: "Square"\n input: "sub"\n attr {\n key: "T"\n value {\n type: DT_FLOAT\n }\n }\n}\nnode {\n name: "Const"\n op: "Const"\n attr {\n key: "dtype"\n value {\n type: DT_INT32\n }\n }\n attr {\n key: "value"\n value {\n tensor {\n dtype: DT_INT32\n tensor_shape {\n dim {\n size: 2\n }\n }\n tensor_content: "\\000\\000\\000\\000\\001\\000\\000\\000"\n }\n }\n }\n}\nnode {\n name: "mse"\n op: "Mean"\n input: "Square"\n input: "Const"\n attr {\n key: "T"\n value {\n type: DT_FLOAT\n }\n }\n attr {\n key: "Tidx"\n value {\n type: DT_INT32\n }\n }\n attr {\n key: "keep_dims"\n value {\n b: false\n }\n }\n}\nnode {\n name: "gradients/Shape"\n op: "Const"\n attr {\n key: "dtype"\n value {\n type: DT_INT32\n }\n }\n attr {\n key: "value"\n value {\n tensor {\n dtype: DT_INT32\n tensor_shape {\n dim {\n }\n }\n }\n }\n }\n}\nnode {\n name: "gradients/Const"\n op: "Const"\n attr {\n key: "dtype"\n value {\n type: DT_FLOAT\n }\n }\n attr {\n key: "value"\n value {\n tensor {\n dtype: DT_FLOAT\n tensor_shape {\n }\n float_val: 1.0\n }\n }\n }\n}\nnode {\n name: "gradients/Fill"\n op: "Fill"\n input: "gradients/Shape"\n input: "gradients/Const"\n attr {\n key: "T"\n value {\n type: DT_FLOAT\n }\n }\n}\nnode {\n name: "gradients/mse_grad/Reshape/shape"\n op: "Const"\n attr {\n key: "dtype"\n value {\n type: DT_INT32\n }\n }\n attr {\n key: "value"\n value {\n tensor {\n dtype: DT_INT32\n tensor_shape {\n dim {\n size: 2\n }\n }\n tensor_content: "\\001\\000\\000\\000\\001\\000\\000\\000"\n }\n }\n }\n}\nnode {\n name: "gradients/mse_grad/Reshape"\n op: "Reshape"\n input: "gradients/Fill"\n input: "gradients/mse_grad/Reshape/shape"\n attr {\n key: "T"\n value {\n type: DT_FLOAT\n }\n }\n attr {\n key: "Tshape"\n value {\n type: DT_INT32\n }\n }\n}\nnode {\n name: "gradients/mse_grad/Tile/multiples"\n op: "Const"\n attr {\n key: "dtype"\n value {\n type: DT_INT32\n }\n }\n attr {\n key: "value"\n value {\n tensor {\n dtype: DT_INT32\n tensor_shape {\n dim {\n size: 2\n }\n }\n tensor_content: "\\240P\\000\\000\\001\\000\\000\\000"\n }\n }\n }\n}\nnode {\n name: "gradients/mse_grad/Tile"\n op: "Tile"\n input: "gradients/mse_grad/Reshape"\n input: "gradients/mse_grad/Tile/multiples"\n attr {\n key: "T"\n value {\n type: DT_FLOAT\n }\n }\n attr {\n key: "Tmultiples"\n value {\n type: DT_INT32\n }\n }\n}\nnode {\n name: "gradients/mse_grad/Shape"\n op: "Const"\n attr {\n key: "dtype"\n value {\n type: DT_INT32\n }\n }\n attr {\n key: "value"\n value {\n tensor {\n dtype: DT_INT32\n tensor_shape {\n dim {\n size: 2\n }\n }\n tensor_content: "\\240P\\000\\000\\001\\000\\000\\000"\n }\n }\n }\n}\nnode {\n name: "gradients/mse_grad/Shape_1"\n op: "Const"\n attr {\n key: "dtype"\n value {\n type: DT_INT32\n }\n }\n attr {\n key: "value"\n value {\n tensor {\n dtype: DT_INT32\n tensor_shape {\n dim {\n }\n }\n }\n }\n }\n}\nnode {\n name: "gradients/mse_grad/Const"\n op: "Const"\n attr {\n key: "dtype"\n value {\n type: DT_INT32\n }\n }\n attr {\n key: "value"\n value {\n tensor {\n dtype: DT_INT32\n tensor_shape {\n dim {\n size: 1\n }\n }\n int_val: 0\n }\n }\n }\n}\nnode {\n name: "gradients/mse_grad/Prod"\n op: "Prod"\n input: "gradients/mse_grad/Shape"\n input: "gradients/mse_grad/Const"\n attr {\n key: "T"\n value {\n type: DT_INT32\n }\n }\n attr {\n key: "Tidx"\n value {\n type: DT_INT32\n }\n }\n attr {\n key: "keep_dims"\n value {\n b: false\n }\n }\n}\nnode {\n name: "gradients/mse_grad/Const_1"\n op: "Const"\n attr {\n key: "dtype"\n value {\n type: DT_INT32\n }\n }\n attr {\n key: "value"\n value {\n tensor {\n dtype: DT_INT32\n tensor_shape {\n dim {\n size: 1\n }\n }\n int_val: 0\n }\n }\n }\n}\nnode {\n name: "gradients/mse_grad/Prod_1"\n op: "Prod"\n input: "gradients/mse_grad/Shape_1"\n input: "gradients/mse_grad/Const_1"\n attr {\n key: "T"\n value {\n type: DT_INT32\n }\n }\n attr {\n key: "Tidx"\n value {\n type: DT_INT32\n }\n }\n attr {\n key: "keep_dims"\n value {\n b: false\n }\n }\n}\nnode {\n name: "gradients/mse_grad/Maximum/y"\n op: "Const"\n attr {\n key: "dtype"\n value {\n type: DT_INT32\n }\n }\n attr {\n key: "value"\n value {\n tensor {\n dtype: DT_INT32\n tensor_shape {\n }\n int_val: 1\n }\n }\n }\n}\nnode {\n name: "gradients/mse_grad/Maximum"\n op: "Maximum"\n input: "gradients/mse_grad/Prod_1"\n input: "gradients/mse_grad/Maximum/y"\n attr {\n key: "T"\n value {\n type: DT_INT32\n }\n }\n}\nnode {\n name: "gradients/mse_grad/floordiv"\n op: "FloorDiv"\n input: "gradients/mse_grad/Prod"\n input: "gradients/mse_grad/Maximum"\n attr {\n key: "T"\n value {\n type: DT_INT32\n }\n }\n}\nnode {\n name: "gradients/mse_grad/Cast"\n op: "Cast"\n input: "gradients/mse_grad/floordiv"\n attr {\n key: "DstT"\n value {\n type: DT_FLOAT\n }\n }\n attr {\n key: "SrcT"\n value {\n type: DT_INT32\n }\n }\n}\nnode {\n name: "gradients/mse_grad/truediv"\n op: "RealDiv"\n input: "gradients/mse_grad/Tile"\n input: "gradients/mse_grad/Cast"\n attr {\n key: "T"\n value {\n type: DT_FLOAT\n }\n }\n}\nnode {\n name: "gradients/Square_grad/mul/x"\n op: "Const"\n input: "^gradients/mse_grad/truediv"\n attr {\n key: "dtype"\n value {\n type: DT_FLOAT\n }\n }\n attr {\n key: "value"\n value {\n tensor {\n dtype: DT_FLOAT\n tensor_shape {\n }\n float_val: 2.0\n }\n }\n }\n}\nnode {\n name: "gradients/Square_grad/mul"\n op: "Mul"\n input: "gradients/Square_grad/mul/x"\n input: "sub"\n attr {\n key: "T"\n value {\n type: DT_FLOAT\n }\n }\n}\nnode {\n name: "gradients/Square_grad/mul_1"\n op: "Mul"\n input: "gradients/mse_grad/truediv"\n input: "gradients/Square_grad/mul"\n attr {\n key: "T"\n value {\n type: DT_FLOAT\n }\n }\n}\nnode {\n name: "gradients/sub_grad/Shape"\n op: "Const"\n attr {\n key: "dtype"\n value {\n type: DT_INT32\n }\n }\n attr {\n key: "value"\n value {\n tensor {\n dtype: DT_INT32\n tensor_shape {\n dim {\n size: 2\n }\n }\n tensor_content: "\\240P\\000\\000\\001\\000\\000\\000"\n }\n }\n }\n}\nnode {\n name: "gradients/sub_grad/Shape_1"\n op: "Const"\n attr {\n key: "dtype"\n value {\n type: DT_INT32\n }\n }\n attr {\n key: "value"\n value {\n tensor {\n dtype: DT_INT32\n tensor_shape {\n dim {\n size: 2\n }\n }\n tensor_content: "\\240P\\000\\000\\001\\000\\000\\000"\n }\n }\n }\n}\nnode {\n name: "gradients/sub_grad/BroadcastGradientArgs"\n op: "BroadcastGradientArgs"\n input: "gradients/sub_grad/Shape"\n input: "gradients/sub_grad/Shape_1"\n attr {\n key: "T"\n value {\n type: DT_INT32\n }\n }\n}\nnode {\n name: "gradients/sub_grad/Sum"\n op: "Sum"\n input: "gradients/Square_grad/mul_1"\n input: "gradients/sub_grad/BroadcastGradientArgs"\n attr {\n key: "T"\n value {\n type: DT_FLOAT\n }\n }\n attr {\n key: "Tidx"\n value {\n type: DT_INT32\n }\n }\n attr {\n key: "keep_dims"\n value {\n b: false\n }\n }\n}\nnode {\n name: "gradients/sub_grad/Reshape"\n op: "Reshape"\n input: "gradients/sub_grad/Sum"\n input: "gradients/sub_grad/Shape"\n attr {\n key: "T"\n value {\n type: DT_FLOAT\n }\n }\n attr {\n key: "Tshape"\n value {\n type: DT_INT32\n }\n }\n}\nnode {\n name: "gradients/sub_grad/Sum_1"\n op: "Sum"\n input: "gradients/Square_grad/mul_1"\n input: "gradients/sub_grad/BroadcastGradientArgs:1"\n attr {\n key: "T"\n value {\n type: DT_FLOAT\n }\n }\n attr {\n key: "Tidx"\n value {\n type: DT_INT32\n }\n }\n attr {\n key: "keep_dims"\n value {\n b: false\n }\n }\n}\nnode {\n name: "gradients/sub_grad/Neg"\n op: "Neg"\n input: "gradients/sub_grad/Sum_1"\n attr {\n key: "T"\n value {\n type: DT_FLOAT\n }\n }\n}\nnode {\n name: "gradients/sub_grad/Reshape_1"\n op: "Reshape"\n input: "gradients/sub_grad/Neg"\n input: "gradients/sub_grad/Shape_1"\n attr {\n key: "T"\n value {\n type: DT_FLOAT\n }\n }\n attr {\n key: "Tshape"\n value {\n type: DT_INT32\n }\n }\n}\nnode {\n name: "gradients/sub_grad/tuple/group_deps"\n op: "NoOp"\n input: "^gradients/sub_grad/Reshape"\n input: "^gradients/sub_grad/Reshape_1"\n}\nnode {\n name: "gradients/sub_grad/tuple/control_dependency"\n op: "Identity"\n input: "gradients/sub_grad/Reshape"\n input: "^gradients/sub_grad/tuple/group_deps"\n attr {\n key: "T"\n value {\n type: DT_FLOAT\n }\n }\n attr {\n key: "_class"\n value {\n list {\n s: "loc:@gradients/sub_grad/Reshape"\n }\n }\n }\n}\nnode {\n name: "gradients/sub_grad/tuple/control_dependency_1"\n op: "Identity"\n input: "gradients/sub_grad/Reshape_1"\n input: "^gradients/sub_grad/tuple/group_deps"\n attr {\n key: "T"\n value {\n type: DT_FLOAT\n }\n }\n attr {\n key: "_class"\n value {\n list {\n s: "loc:@gradients/sub_grad/Reshape_1"\n }\n }\n }\n}\nnode {\n name: "gradients/predictions_grad/MatMul"\n op: "MatMul"\n input: "gradients/sub_grad/tuple/control_dependency"\n input: "theta/read"\n attr {\n key: "T"\n value {\n type: DT_FLOAT\n }\n }\n attr {\n key: "transpose_a"\n value {\n b: false\n }\n }\n attr {\n key: "transpose_b"\n value {\n b: true\n }\n }\n}\nnode {\n name: "gradients/predictions_grad/MatMul_1"\n op: "MatMul"\n input: "X"\n input: "gradients/sub_grad/tuple/control_dependency"\n attr {\n key: "T"\n value {\n type: DT_FLOAT\n }\n }\n attr {\n key: "transpose_a"\n value {\n b: true\n }\n }\n attr {\n key: "transpose_b"\n value {\n b: false\n }\n }\n}\nnode {\n name: "gradients/predictions_grad/tuple/group_deps"\n op: "NoOp"\n input: "^gradients/predictions_grad/MatMul"\n input: "^gradients/predictions_grad/MatMul_1"\n}\nnode {\n name: "gradients/predictions_grad/tuple/control_dependency"\n op: "Identity"\n input: "gradients/predictions_grad/MatMul"\n input: "^gradients/predictions_grad/tuple/group_deps"\n attr {\n key: "T"\n value {\n type: DT_FLOAT\n }\n }\n attr {\n key: "_class"\n value {\n list {\n s: "loc:@gradients/predictions_grad/MatMul"\n }\n }\n }\n}\nnode {\n name: "gradients/predictions_grad/tuple/control_dependency_1"\n op: "Identity"\n input: "gradients/predictions_grad/MatMul_1"\n input: "^gradients/predictions_grad/tuple/group_deps"\n attr {\n key: "T"\n value {\n type: DT_FLOAT\n }\n }\n attr {\n key: "_class"\n value {\n list {\n s: "loc:@gradients/predictions_grad/MatMul_1"\n }\n }\n }\n}\nnode {\n name: "GradientDescent/learning_rate"\n op: "Const"\n attr {\n key: "dtype"\n value {\n type: DT_FLOAT\n }\n }\n attr {\n key: "value"\n value {\n tensor {\n dtype: DT_FLOAT\n tensor_shape {\n }\n float_val: 0.009999999776482582\n }\n }\n }\n}\nnode {\n name: "GradientDescent/update_theta/ApplyGradientDescent"\n op: "ApplyGradientDescent"\n input: "theta"\n input: "GradientDescent/learning_rate"\n input: "gradients/predictions_grad/tuple/control_dependency_1"\n attr {\n key: "T"\n value {\n type: DT_FLOAT\n }\n }\n attr {\n key: "_class"\n value {\n list {\n s: "loc:@theta"\n }\n }\n }\n attr {\n key: "use_locking"\n value {\n b: false\n }\n }\n}\nnode {\n name: "GradientDescent"\n op: "NoOp"\n input: "^GradientDescent/update_theta/ApplyGradientDescent"\n}\nnode {\n name: "init"\n op: "NoOp"\n input: "^theta/Assign"\n}\nnode {\n name: "save/Const"\n op: "Const"\n attr {\n key: "dtype"\n value {\n type: DT_STRING\n }\n }\n attr {\n key: "value"\n value {\n tensor {\n dtype: DT_STRING\n tensor_shape {\n }\n string_val: "model"\n }\n }\n }\n}\nnode {\n name: "save/SaveV2/tensor_names"\n op: "Const"\n attr {\n key: "dtype"\n value {\n type: DT_STRING\n }\n }\n attr {\n key: "value"\n value {\n tensor {\n dtype: DT_STRING\n tensor_shape {\n dim {\n size: 1\n }\n }\n string_val: "theta"\n }\n }\n }\n}\nnode {\n name: "save/SaveV2/shape_and_slices"\n op: "Const"\n attr {\n key: "dtype"\n value {\n type: DT_STRING\n }\n }\n attr {\n key: "value"\n value {\n tensor {\n dtype: DT_STRING\n tensor_shape {\n dim {\n size: 1\n }\n }\n string_val: ""\n }\n }\n }\n}\nnode {\n name: "save/SaveV2"\n op: "SaveV2"\n input: "save/Const"\n input: "save/SaveV2/tensor_names"\n input: "save/SaveV2/shape_and_slices"\n input: "theta"\n attr {\n key: "dtypes"\n value {\n list {\n type: DT_FLOAT\n }\n }\n }\n}\nnode {\n name: "save/control_dependency"\n op: "Identity"\n input: "save/Const"\n input: "^save/SaveV2"\n attr {\n key: "T"\n value {\n type: DT_STRING\n }\n }\n attr {\n key: "_class"\n value {\n list {\n s: "loc:@save/Const"\n }\n }\n }\n}\nnode {\n name: "save/RestoreV2/tensor_names"\n op: "Const"\n attr {\n key: "dtype"\n value {\n type: DT_STRING\n }\n }\n attr {\n key: "value"\n value {\n tensor {\n dtype: DT_STRING\n tensor_shape {\n dim {\n size: 1\n }\n }\n string_val: "theta"\n }\n }\n }\n}\nnode {\n name: "save/RestoreV2/shape_and_slices"\n op: "Const"\n attr {\n key: "dtype"\n value {\n type: DT_STRING\n }\n }\n attr {\n key: "value"\n value {\n tensor {\n dtype: DT_STRING\n tensor_shape {\n dim {\n size: 1\n }\n }\n string_val: ""\n }\n }\n }\n}\nnode {\n name: "save/RestoreV2"\n op: "RestoreV2"\n input: "save/Const"\n input: "save/RestoreV2/tensor_names"\n input: "save/RestoreV2/shape_and_slices"\n attr {\n key: "dtypes"\n value {\n list {\n type: DT_FLOAT\n }\n }\n }\n}\nnode {\n name: "save/Assign"\n op: "Assign"\n input: "theta"\n input: "save/RestoreV2"\n attr {\n key: "T"\n value {\n type: DT_FLOAT\n }\n }\n attr {\n key: "_class"\n value {\n list {\n s: "loc:@theta"\n }\n }\n }\n attr {\n key: "use_locking"\n value {\n b: true\n }\n }\n attr {\n key: "validate_shape"\n value {\n b: true\n }\n }\n}\nnode {\n name: "save/restore_all"\n op: "NoOp"\n input: "^save/Assign"\n}\n';
}
</script>
<link rel="import" href="https://tensorboard.appspot.com/tf-graph-basic.build.html" onload=load()>
<div style="height:600px">
<tf-graph-basic id="graph0.1784179106002547"></tf-graph-basic>
</div>
"></iframe>
Visualization - using TensorBoard
- Start TensorBoard: $ tensorboard --logdir tf_logs/ (starts on localhost:6006)
tf.reset_default_graph()
# Need a logging directory for TB data
# with timestamps to avoid mixing runs together
from datetime import datetime
now = datetime.utcnow().strftime("%Y%m%d%H%M%S")
root_logdir = "tf_logs"
logdir = "{}/run-{}/".format(root_logdir, now)
n_epochs = 1000
learning_rate = 0.01
X = tf.placeholder(
tf.float32,
shape=(None, n + 1),
name="X")
y = tf.placeholder(
tf.float32,
shape=(None, 1),
name="y")
theta = tf.Variable(
tf.random_uniform([n + 1, 1], -1.0, 1.0, seed=42),
name="theta")
y_pred = tf.matmul(
X, theta, name="predictions")
error = y_pred - y
mse = tf.reduce_mean(
tf.square(error),
name="mse")
optimizer = tf.train.GradientDescentOptimizer(
learning_rate=learning_rate)
training_op = optimizer.minimize(mse)
init = tf.global_variables_initializer()
mse_summary = tf.summary.scalar('MSE', mse)
# FileWriter - creates logdir if not already present,
# then writes graph def to a binary logfile.
summary_writer = tf.summary.FileWriter(
logdir,
tf.get_default_graph())
n_epochs = 10
batch_size = 100
n_batches = int(np.ceil(m / batch_size))
with tf.Session() as sess:
sess.run(init)
for epoch in range(n_epochs):
for batch_index in range(n_batches):
X_batch, y_batch = fetch_batch(
epoch,
batch_index,
batch_size)
# evaluate mse_summary on periodic basis,
# eg every 10 minibatches.
# adds summary for addition to events file.
if batch_index % 10 == 0:
summary_str = mse_summary.eval(
feed_dict={X: X_batch, y: y_batch})
step = epoch * n_batches + batch_index
summary_writer.add_summary(
summary_str,
step)
sess.run(
training_op,
feed_dict={X: X_batch, y: y_batch})
best_theta = theta.eval()
summary_writer.flush()
summary_writer.close()
print("Best theta:")
print(best_theta)
Best theta:
[[ 2.07001591]
[ 0.82045609]
[ 0.1173173 ]
[-0.22739051]
[ 0.31134021]
[ 0.00353193]
[-0.01126994]
[-0.91643935]
[-0.87950081]]
#!ls tf_logs/run*
Name Scopes
- Graphs can contain thousands of nodes. name scopes group related nodes to aid visualization.
tf.reset_default_graph()
now = datetime.utcnow().strftime("%Y%m%d%H%M%S")
root_logdir = "tf_logs"
logdir = "{}/run-{}/".format(root_logdir, now)
n_epochs = 1000
learning_rate = 0.01
X = tf.placeholder(
tf.float32,
shape=(None, n + 1),
name="X")
y = tf.placeholder(
tf.float32,
shape=(None, 1),
name="y")
theta = tf.Variable(
tf.random_uniform([n + 1, 1], -1.0, 1.0, seed=42),
name="theta")
y_pred = tf.matmul(
X, theta,
name="predictions")
##### Name Scope
with tf.name_scope('loss') as scope:
error = y_pred - y
mse = tf.reduce_mean(tf.square(error), name="mse")
#####
optimizer = tf.train.GradientDescentOptimizer(
learning_rate=learning_rate)
training_op = optimizer.minimize(mse)
init = tf.global_variables_initializer()
mse_summary = tf.summary.scalar(
'MSE', mse)
summary_writer = tf.summary.FileWriter(
logdir, tf.get_default_graph())
n_epochs = 10
batch_size = 100
n_batches = int(np.ceil(m / batch_size))
with tf.Session() as sess:
sess.run(init)
for epoch in range(n_epochs):
for batch_index in range(n_batches):
X_batch, y_batch = fetch_batch(
epoch,
batch_index,
batch_size)
if batch_index % 10 == 0:
summary_str = mse_summary.eval(
feed_dict={X: X_batch, y: y_batch})
step = epoch * n_batches + batch_index
summary_writer.add_summary(
summary_str,
step)
sess.run(
training_op,
feed_dict={X: X_batch, y: y_batch})
best_theta = theta.eval()
summary_writer.flush()
summary_writer.close()
print("Best theta:")
print(best_theta)
Best theta:
[[ 2.07001591]
[ 0.82045609]
[ 0.1173173 ]
[-0.22739051]
[ 0.31134021]
[ 0.00353193]
[-0.01126994]
[-0.91643935]
[-0.87950081]]
In TensorBoard:
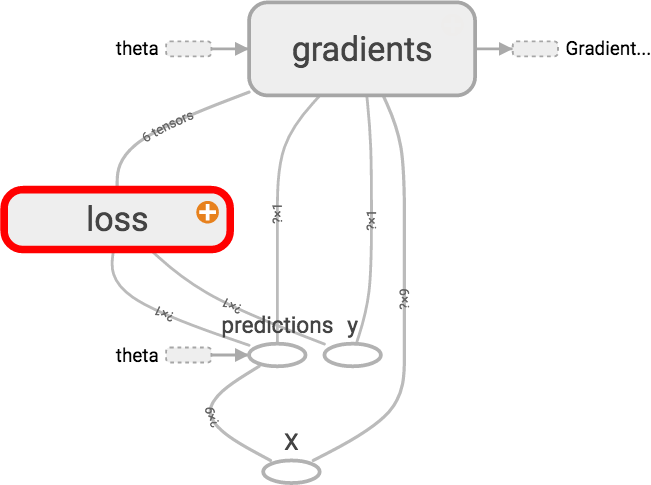
Modularity
- ex: create graph, adds two ReLU nodes
- output: result if >0, 0 otherwise
# UGLY
tf.reset_default_graph()
n_features = 3
X = tf.placeholder(
tf.float32,
shape=(None, n_features),
name="X")
w1 = tf.Variable(
tf.random_normal(
(n_features, 1)),
name="weights1")
w2 = tf.Variable(
tf.random_normal(
(n_features, 1)),
name="weights2")
b1 = tf.Variable(
0.0, name="bias1")
b2 = tf.Variable(
0.0, name="bias2")
linear1 = tf.add(
tf.matmul(X, w1), b1, name="linear1")
linear2 = tf.add(
tf.matmul(X, w2), b2, name="linear2")
relu1 = tf.maximum(
linear1, 0, name="relu1")
relu2 = tf.maximum(
linear2, 0, name="relu2")
output = tf.add_n([relu1, relu2], name="output")
# better -- you can create functions that build ReLUs!
tf.reset_default_graph()
def relu(X):
w_shape = int(
X.get_shape()[1]), 1
w = tf.Variable(
tf.random_normal(w_shape),
name="weights")
b = tf.Variable(
0.0,
name="bias")
linear = tf.add(
tf.matmul(X, w),
b,
name="linear")
return tf.maximum(linear, 0, name="relu")
n_features = 3
X = tf.placeholder(
tf.float32,
shape=(None, n_features),
name="X")
relus = [relu(X) for i in range(5)]
output = tf.add_n(
relus,
name="output")
summary_writer = tf.summary.FileWriter(
"logs/relu1",
tf.get_default_graph())
Sharing Variables
- Simplest option: define it first, then share it as parameter to all functions that need it.
# better, with name scopes
tf.reset_default_graph()
def relu(X):
with tf.name_scope("relu"):
w_shape = int(
X.get_shape()[1]), 1
w = tf.Variable(
tf.random_normal(w_shape), name="weights")
b = tf.Variable(
0.0, name="bias")
linear = tf.add(
tf.matmul(X, w), b, name="linear")
return tf.maximum(
linear, 0, name="max")
n_features = 3
X = tf.placeholder(
tf.float32,
shape=(None, n_features),
name="X")
relus = [relu(X) for i in range(5)]
output = tf.add_n(
relus, name="output")
summary_writer = tf.summary.FileWriter(
"logs/relu2",
tf.get_default_graph())
summary_writer.close()
!ls logs
relu1 relu2 relu6
tf.reset_default_graph()
def relu(X, threshold):
with tf.name_scope("relu"):
w_shape = int(X.get_shape()[1]), 1
w = tf.Variable(tf.random_normal(w_shape), name="weights")
b = tf.Variable(0.0, name="bias")
linear = tf.add(tf.matmul(X, w), b, name="linear")
return tf.maximum(linear, threshold, name="max")
threshold = tf.Variable(0.0, name="threshold")
X = tf.placeholder(tf.float32, shape=(None, n_features), name="X")
relus = [relu(X, threshold) for i in range(5)]
output = tf.add_n(relus, name="output")
tf.reset_default_graph()
def relu(X):
with tf.name_scope("relu"):
if not hasattr(relu, "threshold"):
relu.threshold = tf.Variable(0.0, name="threshold")
w_shape = int(X.get_shape()[1]), 1
w = tf.Variable(tf.random_normal(w_shape), name="weights")
b = tf.Variable(0.0, name="bias")
linear = tf.add(tf.matmul(X, w), b, name="linear")
return tf.maximum(linear, relu.threshold, name="max")
X = tf.placeholder(tf.float32, shape=(None, n_features), name="X")
relus = [relu(X) for i in range(5)]
output = tf.add_n(relus, name="output")
tf.reset_default_graph()
def relu(X):
with tf.variable_scope("relu", reuse=True):
threshold = tf.get_variable("threshold", shape=(), initializer=tf.constant_initializer(0.0))
w_shape = int(X.get_shape()[1]), 1
w = tf.Variable(tf.random_normal(w_shape), name="weights")
b = tf.Variable(0.0, name="bias")
linear = tf.add(tf.matmul(X, w), b, name="linear")
return tf.maximum(linear, threshold, name="max")
X = tf.placeholder(tf.float32, shape=(None, n_features), name="X")
with tf.variable_scope("relu"):
threshold = tf.get_variable("threshold", shape=(), initializer=tf.constant_initializer(0.0))
relus = [relu(X) for i in range(5)]
output = tf.add_n(relus, name="output")
summary_writer = tf.summary.FileWriter("logs/relu6", tf.get_default_graph())
summary_writer.close()