Intro & Resources
Learning to Optimize Rewards
- Definitions: software agents make observations & take actions within an environment. In return they can receive rewards (positive or negative).
Policy Search
- Policy: the algorithm used by an agent to determine a next action.
OpenAI Gym (link:)
- A toolkit for various simulated environments.
!pip3 install --upgrade gym
Requirement already up-to-date: gym in /home/bjpcjp/anaconda3/lib/python3.5/site-packages
Requirement already up-to-date: requests>=2.0 in /home/bjpcjp/anaconda3/lib/python3.5/site-packages (from gym)
Requirement already up-to-date: pyglet>=1.2.0 in /home/bjpcjp/anaconda3/lib/python3.5/site-packages (from gym)
Requirement already up-to-date: six in /home/bjpcjp/anaconda3/lib/python3.5/site-packages (from gym)
Requirement already up-to-date: numpy>=1.10.4 in /home/bjpcjp/anaconda3/lib/python3.5/site-packages (from gym)
import gym
env = gym.make("CartPole-v0")
obs = env.reset()
obs
env.render()
[2017-04-27 13:05:47,311] Making new env: CartPole-v0
- make() creates environment
- reset() returns a 1st env't
- CartPole() - each observation = 1D numpy array (hposition, velocity, angle, angularvelocity)

img = env.render(mode="rgb_array")
img.shape
(1, 1, 3)
# what actions are possible?
# in this case: 0 = accelerate left, 1 = accelerate right
env.action_space
Discrete(2)
# pole is leaning right. let's go further to the right.
action = 1
obs, reward, done, info = env.step(action)
obs, reward, done, info
(array([-0.04061536, 0.1486962 , -0.01966318, -0.29249162]), 1.0, False, {})
- new observation:
- hpos = obs[0]<0
- velocity = obs[1]>0 = moving to the right
- angle = obs[2]>0 = leaning right
- ang velocity = obs[3]<0 = slowing down?
- reward = 1.0
- done = False (episode not over)
- info = (empty)
# example policy:
# (1) accelerate left when leaning left, (2) accelerate right when leaning right
# average reward over 500 episodes?
def basic_policy(obs):
angle = obs[2]
return 0 if angle < 0 else 1
totals = []
for episode in range(500):
episode_rewards = 0
obs = env.reset()
for step in range(1000): # 1000 steps max, we don't want to run forever
action = basic_policy(obs)
obs, reward, done, info = env.step(action)
episode_rewards += reward
if done:
break
totals.append(episode_rewards)
import numpy as np
np.mean(totals), np.std(totals), np.min(totals), np.max(totals)
(41.579999999999998, 8.5249985337242151, 25.0, 62.0)
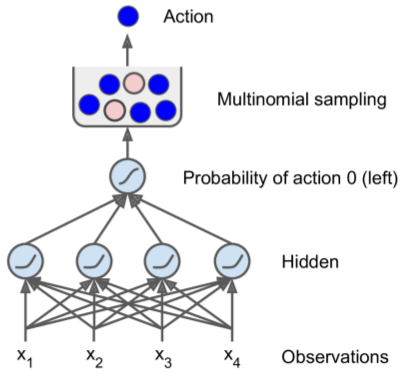
NN Policies
- observations as inputs - actions to be executed as outputs - determined by p(action)
- approach lets agent find best balance between exploring new actions & reusing known good actions.
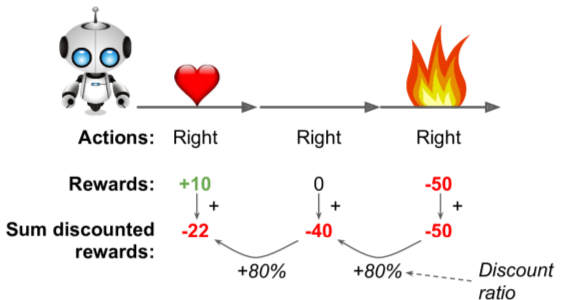
Evaluating Actions: Credit Assignment problem
- Reinforcement Learning (RL) training not like supervised learning.
- RL feedback is via rewards (often sparse & delayed)
- How to determine which previous steps were "good" or "bad"? (aka "credit assigmnment problem")
Common tactic: applying a discount rate to older rewards.
Use normalization across many episodes to increase score reliability.
| NN Policy | Discounts & Rewards |
|---|---|
 |
 |
import tensorflow as tf
from tensorflow.contrib.layers import fully_connected
# 1. Specify the neural network architecture
n_inputs = 4 # == env.observation_space.shape[0]
n_hidden = 4 # simple task, don't need more hidden neurons
n_outputs = 1 # only output prob(accelerating left)
initializer = tf.contrib.layers.variance_scaling_initializer()
# 2. Build the neural network
X = tf.placeholder(
tf.float32, shape=[None, n_inputs])
hidden = fully_connected(
X, n_hidden,
activation_fn=tf.nn.elu,
weights_initializer=initializer)
logits = fully_connected(
hidden, n_outputs,
activation_fn=None,
weights_initializer=initializer)
outputs = tf.nn.sigmoid(logits) # logistic (sigmoid) ==> return 0.0-1.0
# 3. Select a random action based on the estimated probabilities
p_left_and_right = tf.concat(
axis=1, values=[outputs, 1 - outputs])
action = tf.multinomial(
tf.log(p_left_and_right),
num_samples=1)
init = tf.global_variables_initializer()
Policy Gradient (PG) algorithms
- example: "reinforce" algo, 1992
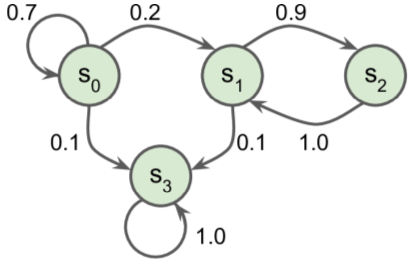
Markov Decision processes (MDPs)
- Markov chains = stochastic processes, no memory, fixed #states, random transitions
- Markov decision processes = similar to MCs - agent can choose action; transition probabilities depend on the action; transitions can return reward/punishment.
- Goal: find policy with maximum rewards over time.
| Markov Chain | Markov Decision Process |
|---|---|
 |
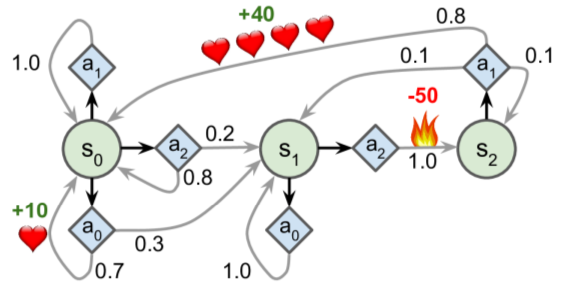 |
- Bellman Optimality Equation: a method to estimate optimal state value of any state s.
- Knowing optimal states = useful, but doesn't tell agent what to do. Q-Value algorithm helps solve this problem. Optimal Q-Value of a state-action pair = sum of discounted future rewards the agent can expect on average.
# Define MDP:
nan=np.nan # represents impossible actions
T = np.array([ # shape=[s, a, s']
[[0.7, 0.3, 0.0], [1.0, 0.0, 0.0], [0.8, 0.2, 0.0]],
[[0.0, 1.0, 0.0], [nan, nan, nan], [0.0, 0.0, 1.0]],
[[nan, nan, nan], [0.8, 0.1, 0.1], [nan, nan, nan]],
])
R = np.array([ # shape=[s, a, s']
[[10., 0.0, 0.0], [0.0, 0.0, 0.0], [0.0, 0.0, 0.0]],
[[10., 0.0, 0.0], [nan, nan, nan], [0.0, 0.0, -50.]],
[[nan, nan, nan], [40., 0.0, 0.0], [nan, nan, nan]],
])
possible_actions = [[0, 1, 2], [0, 2], [1]]
# run Q-Value Iteration algo
Q = np.full((3, 3), -np.inf)
for state, actions in enumerate(possible_actions):
Q[state, actions] = 0.0 # Initial value = 0.0, for all possible actions
learning_rate = 0.01
discount_rate = 0.95
n_iterations = 100
for iteration in range(n_iterations):
Q_prev = Q.copy()
for s in range(3):
for a in possible_actions[s]:
Q[s, a] = np.sum([
T[s, a, sp] * (R[s, a, sp] + discount_rate * np.max(Q_prev[sp]))
for sp in range(3)
])
print("Q: \n",Q)
print("Optimal action for each state:\n",np.argmax(Q, axis=1))
Q:
[[ 21.88646117 20.79149867 16.854807 ]
[ 1.10804034 -inf 1.16703135]
[ -inf 53.8607061 -inf]]
Optimal action for each state:
[0 2 1]
# change discount rate to 0.9, see how policy changes:
discount_rate = 0.90
for iteration in range(n_iterations):
Q_prev = Q.copy()
for s in range(3):
for a in possible_actions[s]:
Q[s, a] = np.sum([
T[s, a, sp] * (R[s, a, sp] + discount_rate * np.max(Q_prev[sp]))
for sp in range(3)
])
print("Q: \n",Q)
print("Optimal action for each state:\n",np.argmax(Q, axis=1))
Q:
[[ 1.89189499e+01 1.70270580e+01 1.36216526e+01]
[ 3.09979853e-05 -inf -4.87968388e+00]
[ -inf 5.01336811e+01 -inf]]
Optimal action for each state:
[0 0 1]
Temporal Difference Learning & Q-Learning
- In general - agent has no knowledge of transition probabilities or rewards
- Temporal Difference Learning (TD Learning) similar to value iteration, but accounts for this lack of knowlege.
Algorithm tracks running average of most recent awards & anticipated rewards.
Q-Learning algorithm adaptation of Q-Value Iteration where initial transition probabilities & rewards are unknown.
import numpy.random as rnd
learning_rate0 = 0.05
learning_rate_decay = 0.1
n_iterations = 20000
s = 0 # start in state 0
Q = np.full((3, 3), -np.inf) # -inf for impossible actions
for state, actions in enumerate(possible_actions):
Q[state, actions] = 0.0 # Initial value = 0.0, for all possible actions
for iteration in range(n_iterations):
a = rnd.choice(possible_actions[s]) # choose an action (randomly)
sp = rnd.choice(range(3), p=T[s, a]) # pick next state using T[s, a]
reward = R[s, a, sp]
learning_rate = learning_rate0 / (1 + iteration * learning_rate_decay)
Q[s, a] = learning_rate * Q[s, a] + (1 - learning_rate) * (reward + discount_rate * np.max(Q[sp]))
s = sp # move to next state
print("Q: \n",Q)
print("Optimal action for each state:\n",np.argmax(Q, axis=1))
Q:
[[ -inf 2.47032823e-323 -inf]
[ 0.00000000e+000 -inf 0.00000000e+000]
[ -inf 0.00000000e+000 -inf]]
Optimal action for each state:
[1 0 1]
Exploration Policies
- Q-Learning works only if exploration is thorough - not always possible.
- Better alternative: explore more interesting routes using a sigma probability
Approximate Q-Learning
- TODO
Ms Pac-Man with Deep Q-Learning
env = gym.make('MsPacman-v0')
obs = env.reset()
obs.shape, env.action_space
# action_space = 9 possible joystick actions
# observations = atari screenshots as 3D NumPy arrays
[2017-04-27 13:06:21,861] Making new env: MsPacman-v0
((210, 160, 3), Discrete(9))
mspacman_color = np.array([210, 164, 74]).mean()
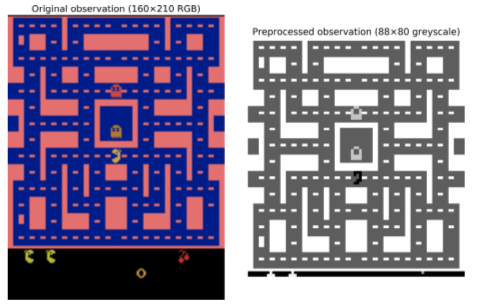
# crop image, shrink to 88x80 pixels, convert to grayscale, improve contrast
def preprocess_observation(obs):
img = obs[1:176:2, ::2] # crop and downsize
img = img.mean(axis=2) # to greyscale
img[img==mspacman_color] = 0 # improve contrast
img = (img - 128) / 128 - 1 # normalize from -1. to 1.
return img.reshape(88, 80, 1)
| Ms PacMan Observation | Deep-Q net |
|---|---|
 |
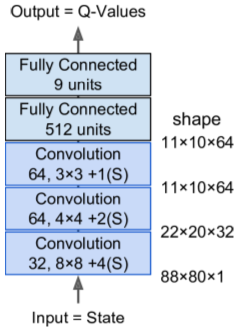 |
# Create DQN
# 3 convo layers, then 2 FC layers including output layer
from tensorflow.contrib.layers import convolution2d, fully_connected
input_height = 88
input_width = 80
input_channels = 1
conv_n_maps = [32, 64, 64]
conv_kernel_sizes = [(8,8), (4,4), (3,3)]
conv_strides = [4, 2, 1]
conv_paddings = ["SAME"]*3
conv_activation = [tf.nn.relu]*3
n_hidden_in = 64 * 11 * 10 # conv3 has 64 maps of 11x10 each
n_hidden = 512
hidden_activation = tf.nn.relu
n_outputs = env.action_space.n # 9 discrete actions are available
initializer = tf.contrib.layers.variance_scaling_initializer()
# training will need ***TWO*** DQNs:
# one to train the actor
# another to learn from trials & errors (critic)
# q_network is our net builder.
def q_network(X_state, scope):
prev_layer = X_state
conv_layers = []
with tf.variable_scope(scope) as scope:
for n_maps, kernel_size, stride, padding, activation in zip(
conv_n_maps,
conv_kernel_sizes,
conv_strides,
conv_paddings,
conv_activation):
prev_layer = convolution2d(
prev_layer,
num_outputs=n_maps,
kernel_size=kernel_size,
stride=stride,
padding=padding,
activation_fn=activation,
weights_initializer=initializer)
conv_layers.append(prev_layer)
last_conv_layer_flat = tf.reshape(
prev_layer,
shape=[-1, n_hidden_in])
hidden = fully_connected(
last_conv_layer_flat,
n_hidden,
activation_fn=hidden_activation,
weights_initializer=initializer)
outputs = fully_connected(
hidden,
n_outputs,
activation_fn=None,
weights_initializer=initializer)
trainable_vars = tf.get_collection(
tf.GraphKeys.TRAINABLE_VARIABLES,
scope=scope.name)
trainable_vars_by_name = {var.name[len(scope.name):]: var
for var in trainable_vars}
return outputs, trainable_vars_by_name
# create input placeholders & two DQNs
X_state = tf.placeholder(
tf.float32,
shape=[None, input_height, input_width,
input_channels])
actor_q_values, actor_vars = q_network(X_state, scope="q_networks/actor")
critic_q_values, critic_vars = q_network(X_state, scope="q_networks/critic")
copy_ops = [actor_var.assign(critic_vars[var_name])
for var_name, actor_var in actor_vars.items()]
# op to copy all trainable vars of critic DQN to actor DQN...
# use tf.group() to group all assignment ops together
copy_critic_to_actor = tf.group(*copy_ops)
# Critic DQN learns by matching Q-Value predictions
# to actor's Q-Value estimations during game play
# Actor will use a "replay memory" (5 tuples):
# state, action, next-state, reward, (0=over/1=continue)
# use normal supervised training ops
# occasionally copy critic DQN to actor DQN
# DQN normally returns one Q-Value for every poss. action
# only need Q-Value of action actually chosen
# So, convert action to one-hot vector [0...1...0], multiple by Q-values
# then sum over 1st axis.
X_action = tf.placeholder(
tf.int32, shape=[None])
q_value = tf.reduce_sum(
critic_q_values * tf.one_hot(X_action, n_outputs),
axis=1, keep_dims=True)
# training setup
tf.reset_default_graph()
y = tf.placeholder(
tf.float32, shape=[None, 1])
cost = tf.reduce_mean(
tf.square(y - q_value))
# non-trainable. minimize() op will manage incrementing it
global_step = tf.Variable(
0,
trainable=False,
name='global_step')
optimizer = tf.train.AdamOptimizer(learning_rate)
training_op = optimizer.minimize(cost, global_step=global_step)
init = tf.global_variables_initializer()
saver = tf.train.Saver()
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-54-ae5a849b8026> in <module>()
7
8 cost = tf.reduce_mean(
----> 9 tf.square(y - q_value))
10
11 # non-trainable. minimize() op will manage incrementing it
/home/bjpcjp/anaconda3/lib/python3.5/site-packages/tensorflow/python/ops/math_ops.py in binary_op_wrapper(x, y)
879
880 def binary_op_wrapper(x, y):
--> 881 with ops.name_scope(None, op_name, [x, y]) as name:
882 if not isinstance(y, sparse_tensor.SparseTensor):
883 y = ops.convert_to_tensor(y, dtype=x.dtype.base_dtype, name="y")
/home/bjpcjp/anaconda3/lib/python3.5/contextlib.py in __enter__(self)
57 def __enter__(self):
58 try:
---> 59 return next(self.gen)
60 except StopIteration:
61 raise RuntimeError("generator didn't yield") from None
/home/bjpcjp/anaconda3/lib/python3.5/site-packages/tensorflow/python/framework/ops.py in name_scope(name, default_name, values)
4217 if values is None:
4218 values = []
-> 4219 g = _get_graph_from_inputs(values)
4220 with g.as_default(), g.name_scope(n) as scope:
4221 yield scope
/home/bjpcjp/anaconda3/lib/python3.5/site-packages/tensorflow/python/framework/ops.py in _get_graph_from_inputs(op_input_list, graph)
3966 graph = graph_element.graph
3967 elif original_graph_element is not None:
-> 3968 _assert_same_graph(original_graph_element, graph_element)
3969 elif graph_element.graph is not graph:
3970 raise ValueError(
/home/bjpcjp/anaconda3/lib/python3.5/site-packages/tensorflow/python/framework/ops.py in _assert_same_graph(original_item, item)
3905 if original_item.graph is not item.graph:
3906 raise ValueError(
-> 3907 "%s must be from the same graph as %s." % (item, original_item))
3908
3909
ValueError: Tensor("Sum_1:0", shape=(?, 1), dtype=float32) must be from the same graph as Tensor("Placeholder:0", shape=(?, 1), dtype=float32).
# use a deque list to build the replay memory
from collections import deque
replay_memory_size = 10000
replay_memory = deque(
[], maxlen=replay_memory_size)
def sample_memories(batch_size):
indices = rnd.permutation(
len(replay_memory))[:batch_size]
cols = [[], [], [], [], []] # state, action, reward, next_state, continue
for idx in indices:
memory = replay_memory[idx]
for col, value in zip(cols, memory):
col.append(value)
cols = [np.array(col) for col in cols]
return (cols[0], cols[1], cols[2].reshape(-1, 1), cols[3], cols[4].reshape(-1, 1))
# create an actor
# use epsilon-greedy policy
# gradually decrease epsilon from 1.0 to 0.05 across 50K training steps
eps_min = 0.05
eps_max = 1.0
eps_decay_steps = 50000
def epsilon_greedy(q_values, step):
epsilon = max(eps_min, eps_max - (eps_max-eps_min) * step/eps_decay_steps)
if rnd.rand() < epsilon:
return rnd.randint(n_outputs) # random action
else:
return np.argmax(q_values) # optimal action
# training setup: the variables
n_steps = 100000 # total number of training steps
training_start = 1000 # start training after 1,000 game iterations
training_interval = 3 # run a training step every 3 game iterations
save_steps = 50 # save the model every 50 training steps
copy_steps = 25 # copy the critic to the actor every 25 training steps
discount_rate = 0.95
skip_start = 90 # skip the start of every game (it's just waiting time)
batch_size = 50
iteration = 0 # game iterations
checkpoint_path = "./my_dqn.ckpt"
done = True # env needs to be reset
# let's get busy
import os
with tf.Session() as sess:
# restore models if checkpoint file exists
if os.path.isfile(checkpoint_path):
saver.restore(sess, checkpoint_path)
# otherwise normally initialize variables
else:
init.run()
while True:
step = global_step.eval()
if step >= n_steps:
break
# iteration = total number of game steps from beginning
iteration += 1
if done: # game over, start again
obs = env.reset()
for skip in range(skip_start): # skip the start of each game
obs, reward, done, info = env.step(0)
state = preprocess_observation(obs)
# Actor evaluates what to do
q_values = actor_q_values.eval(feed_dict={X_state: [state]})
action = epsilon_greedy(q_values, step)
# Actor plays
obs, reward, done, info = env.step(action)
next_state = preprocess_observation(obs)
# Let's memorize what just happened
replay_memory.append((state, action, reward, next_state, 1.0 - done))
state = next_state
if iteration < training_start or iteration % training_interval != 0:
continue
# Critic learns
X_state_val, X_action_val, rewards, X_next_state_val, continues = (
sample_memories(batch_size))
next_q_values = actor_q_values.eval(
feed_dict={X_state: X_next_state_val})
max_next_q_values = np.max(
next_q_values, axis=1, keepdims=True)
y_val = rewards + continues * discount_rate * max_next_q_values
training_op.run(
feed_dict={X_state: X_state_val, X_action: X_action_val, y: y_val})
# Regularly copy critic to actor
if step % copy_steps == 0:
copy_critic_to_actor.run()
# And save regularly
if step % save_steps == 0:
saver.save(sess, checkpoint_path)
print("\n",np.average(y_val))
1.09000234097
1.35392784142
1.56906713688
2.5765440191
1.57079289043
1.75170834792
1.97005553639
1.97246688247
2.16126081383
1.550295331
1.75750140131
1.56052656734
1.7519523176
1.74495741558
1.95223849511
1.35289915931
1.56913152564
2.96387254691
1.76067311585
1.35536773229
1.54768545294
1.53594982147
1.56104325151
1.96987313104
2.35546155441
1.5688166486
3.08286282682
3.28864161086
3.2878398273
3.09510449028
3.09807873964
3.90697311211
3.07757974195
3.09214673901
3.28402029777
3.28337000942
3.4255889504
3.49763186431
2.85764229989
3.04482784653
2.68228099513
3.28635532999
3.29647485089
3.07898310328
3.10530596256
3.27691918874
3.09561720395
2.67830030346
3.09576807404
3.288335078
3.0956065948
5.21222548962
4.21721751595
4.7905973649
4.59864345837
4.39875211382
4.51839643717
4.59503188992
5.01186150789
4.77968219852
4.78787856865
4.20382899523
4.20432999897
5.0028930707
5.20069698572
4.80375980473
5.19750945711
4.20367767668
4.19593407536
4.40061367989
4.6054182477
4.79921974087
4.38844807434
4.20397897291
4.60095557356
4.59488785553
5.75924422598
5.75949315596
5.16320213652
5.36019721937
5.56076610899
5.16949163198
5.75895399189
5.96050115204
5.97032629395
---------------------------------------------------------------------------
KeyboardInterrupt Traceback (most recent call last)
<ipython-input-44-d0da605267f3> in <module>()
46
47 next_q_values = actor_q_values.eval(
---> 48 feed_dict={X_state: X_next_state_val})
49
50 max_next_q_values = np.max(
/home/bjpcjp/anaconda3/lib/python3.5/site-packages/tensorflow/python/framework/ops.py in eval(self, feed_dict, session)
579
580 """
--> 581 return _eval_using_default_session(self, feed_dict, self.graph, session)
582
583
/home/bjpcjp/anaconda3/lib/python3.5/site-packages/tensorflow/python/framework/ops.py in _eval_using_default_session(tensors, feed_dict, graph, session)
3795 "the tensor's graph is different from the session's "
3796 "graph.")
-> 3797 return session.run(tensors, feed_dict)
3798
3799
/home/bjpcjp/anaconda3/lib/python3.5/site-packages/tensorflow/python/client/session.py in run(self, fetches, feed_dict, options, run_metadata)
765 try:
766 result = self._run(None, fetches, feed_dict, options_ptr,
--> 767 run_metadata_ptr)
768 if run_metadata:
769 proto_data = tf_session.TF_GetBuffer(run_metadata_ptr)
/home/bjpcjp/anaconda3/lib/python3.5/site-packages/tensorflow/python/client/session.py in _run(self, handle, fetches, feed_dict, options, run_metadata)
963 if final_fetches or final_targets:
964 results = self._do_run(handle, final_targets, final_fetches,
--> 965 feed_dict_string, options, run_metadata)
966 else:
967 results = []
/home/bjpcjp/anaconda3/lib/python3.5/site-packages/tensorflow/python/client/session.py in _do_run(self, handle, target_list, fetch_list, feed_dict, options, run_metadata)
1013 if handle is None:
1014 return self._do_call(_run_fn, self._session, feed_dict, fetch_list,
-> 1015 target_list, options, run_metadata)
1016 else:
1017 return self._do_call(_prun_fn, self._session, handle, feed_dict,
/home/bjpcjp/anaconda3/lib/python3.5/site-packages/tensorflow/python/client/session.py in _do_call(self, fn, *args)
1020 def _do_call(self, fn, *args):
1021 try:
-> 1022 return fn(*args)
1023 except errors.OpError as e:
1024 message = compat.as_text(e.message)
/home/bjpcjp/anaconda3/lib/python3.5/site-packages/tensorflow/python/client/session.py in _run_fn(session, feed_dict, fetch_list, target_list, options, run_metadata)
1002 return tf_session.TF_Run(session, options,
1003 feed_dict, fetch_list, target_list,
-> 1004 status, run_metadata)
1005
1006 def _prun_fn(session, handle, feed_dict, fetch_list):
KeyboardInterrupt: