Sequence classification with LSTM
import tensorflow as tf
import tensorflow.examples.tutorials.mnist.input_data as input_data
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
print ("Packages imported")
mnist = input_data.read_data_sets("data/", one_hot=True)
trainimgs, trainlabels, testimgs, testlabels \
= mnist.train.images, mnist.train.labels, mnist.test.images, mnist.test.labels
ntrain, ntest, dim, nclasses \
= trainimgs.shape[0], testimgs.shape[0], trainimgs.shape[1], trainlabels.shape[1]
print ("MNIST loaded")
Packages imported
Extracting data/train-images-idx3-ubyte.gz
Extracting data/train-labels-idx1-ubyte.gz
Extracting data/t10k-images-idx3-ubyte.gz
Extracting data/t10k-labels-idx1-ubyte.gz
MNIST loaded
We will treat the MNIST image $\in \mathcal{R}^{28 \times 28}$ as $28$ sequences of a vector $\mathbf{x} \in \mathcal{R}^{28}$.
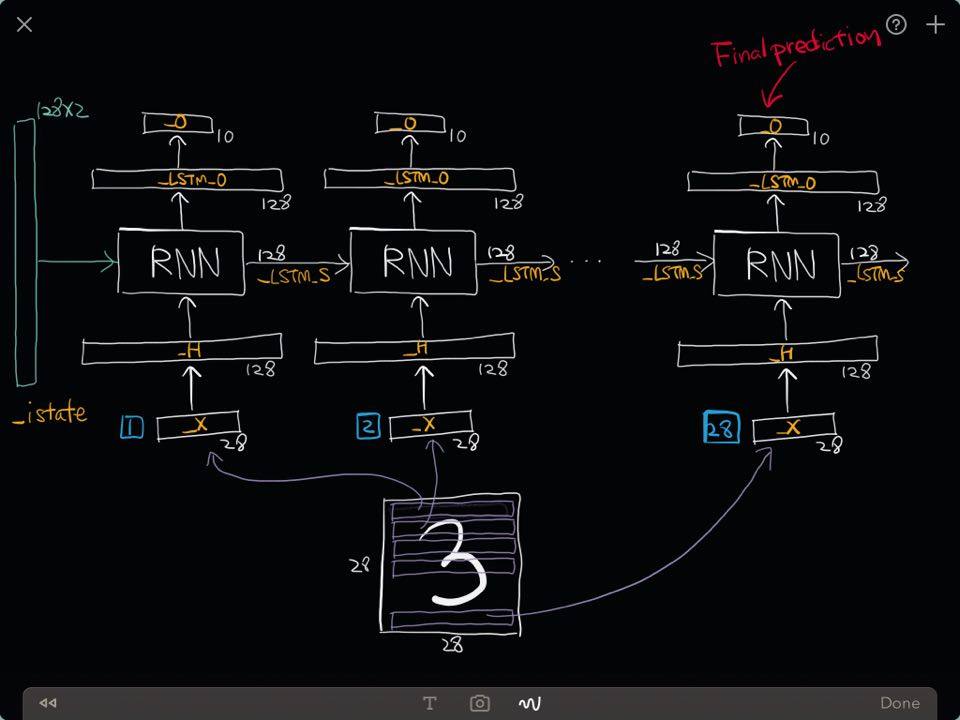
Our simple RNN consists of
- One input layer which converts a $28$ dimensional input to an $128$ dimensional hidden layer,
- One intermediate recurrent neural network (LSTM)
- One output layer which converts an $128$ dimensional output of the LSTM to $10$ dimensional output indicating a class label.
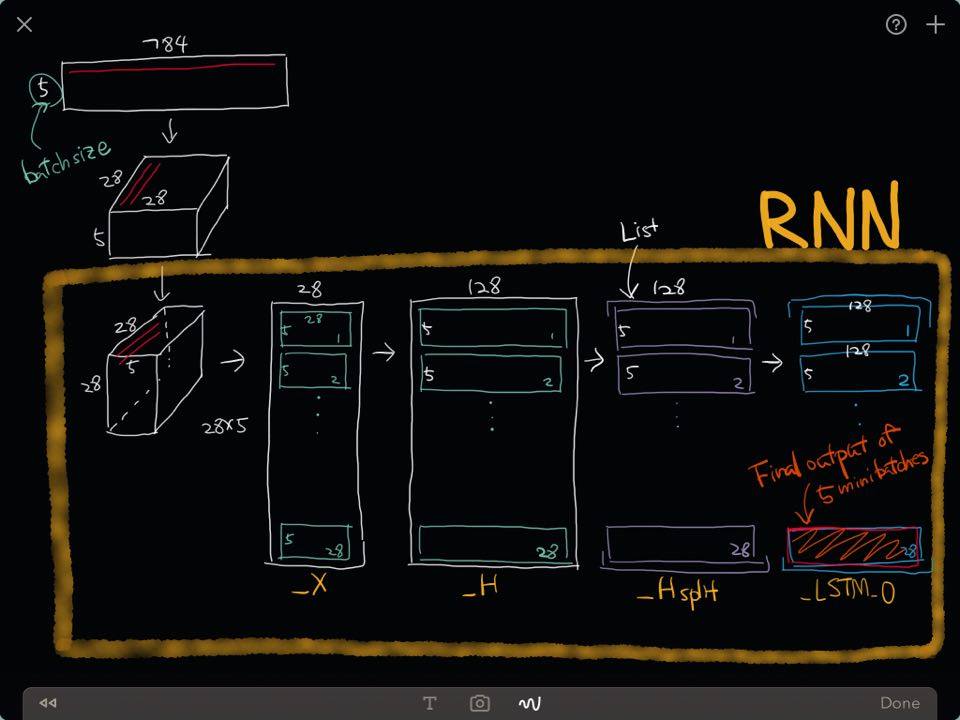
Contruct a Recurrent Neural Network
diminput = 28
dimhidden = 128
dimoutput = nclasses
nsteps = 28
weights = {
'hidden': tf.Variable(tf.random_normal([diminput, dimhidden])),
'out': tf.Variable(tf.random_normal([dimhidden, dimoutput]))
}
biases = {
'hidden': tf.Variable(tf.random_normal([dimhidden])),
'out': tf.Variable(tf.random_normal([dimoutput]))
}
def _RNN(_X, _istate, _W, _b, _nsteps, _name):
_X = tf.transpose(_X, [1, 0, 2])
_X = tf.reshape(_X, [-1, diminput])
_H = tf.matmul(_X, _W['hidden']) + _b['hidden']
_Hsplit = tf.split(0, _nsteps, _H)
with tf.variable_scope(_name):
lstm_cell = tf.nn.rnn_cell.BasicLSTMCell(dimhidden, forget_bias=1.0)
_LSTM_O, _LSTM_S = tf.nn.rnn(lstm_cell, _Hsplit, initial_state=_istate)
_O = tf.matmul(_LSTM_O[-1], _W['out']) + _b['out']
return {
'X': _X, 'H': _H, 'Hsplit': _Hsplit,
'LSTM_O': _LSTM_O, 'LSTM_S': _LSTM_S, 'O': _O
}
print ("Network ready")
Network ready
Out Network looks like this
Define functions
learning_rate = 0.001
x = tf.placeholder("float", [None, nsteps, diminput])
istate = tf.placeholder("float", [None, 2*dimhidden])
y = tf.placeholder("float", [None, dimoutput])
myrnn = _RNN(x, istate, weights, biases, nsteps, 'basic')
pred = myrnn['O']
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(pred, y))
optm = tf.train.AdamOptimizer(learning_rate).minimize(cost)
accr = tf.reduce_mean(tf.cast(tf.equal(tf.argmax(pred,1), tf.argmax(y,1)), tf.float32))
init = tf.initialize_all_variables()
print ("Network Ready!")
Network Ready!
Run!
training_epochs = 5
batch_size = 128
display_step = 1
sess = tf.Session()
sess.run(init)
summary_writer = tf.train.SummaryWriter('/tmp/tensorflow_logs', graph=sess.graph)
print ("Start optimization")
for epoch in range(training_epochs):
avg_cost = 0.
total_batch = int(mnist.train.num_examples/batch_size)
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
batch_xs = batch_xs.reshape((batch_size, nsteps, diminput))
feeds = {x: batch_xs, y: batch_ys, istate: np.zeros((batch_size, 2*dimhidden))}
sess.run(optm, feed_dict=feeds)
avg_cost += sess.run(cost, feed_dict=feeds)/total_batch
if epoch % display_step == 0:
print ("Epoch: %03d/%03d cost: %.9f" % (epoch, training_epochs, avg_cost))
feeds = {x: batch_xs, y: batch_ys, istate: np.zeros((batch_size, 2*dimhidden))}
train_acc = sess.run(accr, feed_dict=feeds)
print (" Training accuracy: %.3f" % (train_acc))
testimgs = testimgs.reshape((ntest, nsteps, diminput))
feeds = {x: testimgs, y: testlabels, istate: np.zeros((ntest, 2*dimhidden))}
test_acc = sess.run(accr, feed_dict=feeds)
print (" Test accuracy: %.3f" % (test_acc))
print ("Optimization Finished.")
Start optimization
Epoch: 000/005 cost: 0.479400075
Training accuracy: 0.992
Test accuracy: 0.922
Epoch: 001/005 cost: 0.136942688
Training accuracy: 0.969
Test accuracy: 0.959
Epoch: 002/005 cost: 0.081425477
Training accuracy: 0.984
Test accuracy: 0.951
Epoch: 003/005 cost: 0.061170839
Training accuracy: 0.969
Test accuracy: 0.973
Epoch: 004/005 cost: 0.047727333
Training accuracy: 0.992
Test accuracy: 0.973
Optimization Finished.
What we have done so far is to feed 28 sequences of vectors $ \mathbf{x} \in \mathcal{R}^{28}$.
What will happen if we feed first 25 sequences of $\mathbf{x}$?
nsteps2 = 25
testimgs = testimgs.reshape((ntest, nsteps, diminput))
testimgs_trucated = np.zeros(testimgs.shape)
testimgs_trucated[:, 28-nsteps2:] = testimgs[:, :nsteps2, :]
feeds = {x: testimgs_trucated, y: testlabels, istate: np.zeros((ntest, 2*dimhidden))}
test_acc = sess.run(accr, feed_dict=feeds)
print (" If we use %d seqs, test accuracy becomes %.3f" % (nsteps2, test_acc))
If we use 25 seqs, test accuracy becomes 0.766
What's going on inside the RNN?
batch_size = 5
xtest, _ = mnist.test.next_batch(batch_size)
print ("Shape of 'xtest' is %s" % (xtest.shape,))
Shape of 'xtest' is (5, 784)
xtest1 = xtest.reshape((batch_size, nsteps, diminput))
print ("Shape of 'xtest1' is %s" % (xtest1.shape,))
Shape of 'xtest1' is (5, 28, 28)
feeds = {x: xtest1, istate: np.zeros((batch_size, 2*dimhidden))}
rnnout_X = sess.run(myrnn['X'], feed_dict=feeds)
print ("Shape of 'rnnout_X' is %s" % (rnnout_X.shape,))
Shape of 'rnnout_X' is (140, 28)
rnnout_H = sess.run(myrnn['H'], feed_dict=feeds)
print ("Shape of 'rnnout_H' is %s" % (rnnout_H.shape,))
Shape of 'rnnout_H' is (140, 128)
rnnout_Hsplit = sess.run(myrnn['Hsplit'], feed_dict=feeds)
print ("Type of 'rnnout_Hsplit' is %s" % (type(rnnout_Hsplit)))
print ("Length of 'rnnout_Hsplit' is %s and the shape of each item is %s"
% (len(rnnout_Hsplit), rnnout_Hsplit[0].shape))
Type of 'rnnout_Hsplit' is <type 'list'>
Length of 'rnnout_Hsplit' is 28 and the shape of each item is (5, 128)
Output from the LSTM (List)
rnnout_LSTM_O = sess.run(myrnn['LSTM_O'], feed_dict=feeds)
print ("Type of 'rnnout_LSTM_O' is %s" % (type(rnnout_LSTM_O)))
print ("Length of 'rnnout_LSTM_O' is %s and the shape of each item is %s"
% (len(rnnout_LSTM_O), rnnout_LSTM_O[0].shape))
Type of 'rnnout_LSTM_O' is <type 'list'>
Length of 'rnnout_LSTM_O' is 28 and the shape of each item is (5, 128)
Final prediction
rnnout_O = sess.run(myrnn['O'], feed_dict=feeds)
print ("Shape of 'rnnout_O' is %s" % (rnnout_O.shape,))
Shape of 'rnnout_O' is (5, 10)