Word2vec basic
import collections
import math
import os
import random
import zipfile
import numpy as np
from six.moves import urllib
from six.moves import xrange
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
import tensorflow as tf
%matplotlib inline
print ("Packages loaded")
Packages loaded
1. Download the text and make corpus (set of words)
Download (or reuse) the text file that we will use
folder_dir = "data"
file_name = "text8.zip"
file_path = os.path.join(folder_dir, file_name)
url = 'http://mattmahoney.net/dc/'
if not os.path.exists(file_path):
print ("No file found. Start downloading")
downfilename, _ = urllib.request.urlretrieve(
url + file_name, file_path)
print ("'%s' downloaded" % (downfilename))
else:
print ("File already exists")
File already exists
Check we have correct data
statinfo = os.stat(file_path)
expected_bytes = 31344016
if statinfo.st_size == expected_bytes:
print ("I guess we have correct file at '%s'" % (file_path))
else:
print ("Something's wrong with the file at '%s'" % (file_path))
I guess we have correct file at 'data/text8.zip'
Unzip the file
def read_data(filename):
with zipfile.ZipFile(filename) as f:
data = f.read(f.namelist()[0]).split()
return data
words = read_data(file_path)
print ("Type of 'words' is %s / Length is %d "
% (type(words), len(words)))
print ("'words' look like \n %s" %(words[0:100]))
Type of 'words' is <type 'list'> / Length is 17005207
'words' look like
['anarchism', 'originated', 'as', 'a', 'term', 'of', 'abuse', 'first', 'used', 'against', 'early', 'working', 'class', 'radicals', 'including', 'the', 'diggers', 'of', 'the', 'english', 'revolution', 'and', 'the', 'sans', 'culottes', 'of', 'the', 'french', 'revolution', 'whilst', 'the', 'term', 'is', 'still', 'used', 'in', 'a', 'pejorative', 'way', 'to', 'describe', 'any', 'act', 'that', 'used', 'violent', 'means', 'to', 'destroy', 'the', 'organization', 'of', 'society', 'it', 'has', 'also', 'been', 'taken', 'up', 'as', 'a', 'positive', 'label', 'by', 'self', 'defined', 'anarchists', 'the', 'word', 'anarchism', 'is', 'derived', 'from', 'the', 'greek', 'without', 'archons', 'ruler', 'chief', 'king', 'anarchism', 'as', 'a', 'political', 'philosophy', 'is', 'the', 'belief', 'that', 'rulers', 'are', 'unnecessary', 'and', 'should', 'be', 'abolished', 'although', 'there', 'are', 'differing']
2. Make a dictionary with fixed length (using UNK token)
Count the words
vocabulary_size = 50000
count = [['UNK', -1]]
count.extend(collections.Counter(words)
.most_common(vocabulary_size - 1))
print ("Type of 'count' is %s / Length is %d " % (type(count), len(count)))
print ("'count' looks like \n %s" % (count[0:10]))
Type of 'count' is <type 'list'> / Length is 50000
'count' looks like
[['UNK', -1], ('the', 1061396), ('of', 593677), ('and', 416629), ('one', 411764), ('in', 372201), ('a', 325873), ('to', 316376), ('zero', 264975), ('nine', 250430)]
Make a dictionary
dictionary = dict()
for word, _ in count:
dictionary[word] = len(dictionary)
print ("Type of 'dictionary' is %s / Length is %d "
% (type(dictionary), len(dictionary)))
Type of 'dictionary' is <type 'dict'> / Length is 50000
Make a reverse dictionary
reverse_dictionary = dict(zip(dictionary.values(), dictionary.keys()))
print ("Type of 'reverse_dictionary' is %s / Length is %d "
% (type(reverse_dictionary), len(reverse_dictionary)))
Type of 'reverse_dictionary' is <type 'dict'> / Length is 50000
Make data
data = list()
unk_count = 0
for word in words:
if word in dictionary:
index = dictionary[word]
else:
index = 0
unk_count += 1
data.append(index)
count[0][1] = unk_count
'dictionary' converts word to index
'reverse_dictionary' converts index to word
print ("Most common words (+UNK) are: %s" % (count[:5]))
Most common words (+UNK) are: [['UNK', 418391], ('the', 1061396), ('of', 593677), ('and', 416629), ('one', 411764)]
Data (in indices)
print ("Sample data: %s" % (data[:10]))
Sample data: [5239, 3084, 12, 6, 195, 2, 3137, 46, 59, 156]
Convert to char (which we can read)
print ("Sample data corresponds to\n__________________")
for i in range(10):
print ("%d->%s" % (data[i], reverse_dictionary[data[i]]))
Sample data corresponds to
__________________
5239->anarchism
3084->originated
12->as
6->a
195->term
2->of
3137->abuse
46->first
59->used
156->against
Batch-generating function for skip-gram model
- Skip-gram (one word to one word) => Can generate more training data
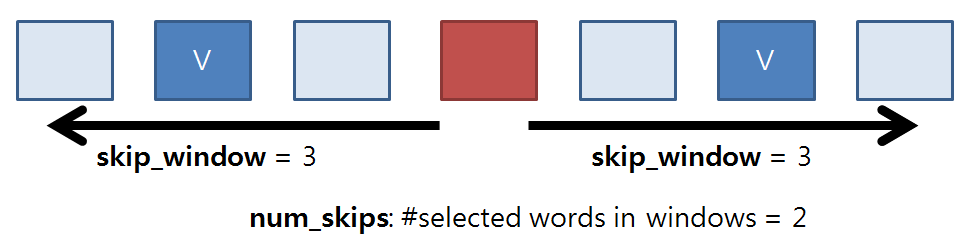
data_index = 0
def generate_batch(batch_size, num_skips, skip_window):
global data_index
assert batch_size % num_skips == 0
assert num_skips <= 2 * skip_window
batch = np.ndarray(shape=(batch_size), dtype=np.int32)
labels = np.ndarray(shape=(batch_size, 1), dtype=np.int32)
span = 2 * skip_window + 1
buffer = collections.deque(maxlen=span)
for _ in range(span):
buffer.append(data[data_index])
data_index = (data_index + 1) % len(data)
for i in range(batch_size // num_skips):
target = skip_window
targets_to_avoid = [ skip_window ]
for j in range(num_skips):
while target in targets_to_avoid:
target = random.randint(0, span - 1)
targets_to_avoid.append(target)
batch[i * num_skips + j] = buffer[skip_window]
labels[i * num_skips + j, 0] = buffer[target]
buffer.append(data[data_index])
data_index = (data_index + 1) % len(data)
return batch, labels
Examples for generating batch and labels
data_index = 0
batch, labels = generate_batch(batch_size=8, num_skips=2, skip_window=1)
print ("Type of 'batch' is %s / Length is %d "
% (type(batch), len(batch)))
print ("Type of 'labels' is %s / Length is %d "
% (type(labels), len(labels)))
Type of 'batch' is <type 'numpy.ndarray'> / Length is 8
Type of 'labels' is <type 'numpy.ndarray'> / Length is 8
print ("'batch' looks like \n %s" % (batch))
'batch' looks like
[3084 3084 12 12 6 6 195 195]
print ("'labels' looks like \n %s" % (labels))
'labels' looks like
[[5239]
[ 12]
[3084]
[ 6]
[ 195]
[ 12]
[ 2]
[ 6]]
for i in range(8):
print ("%d -> %d"
% (batch[i], labels[i, 0])),
print ("\t%s -> %s"
% (reverse_dictionary[batch[i]]
, reverse_dictionary[labels[i, 0]]))
3084 -> 5239 originated -> anarchism
3084 -> 12 originated -> as
12 -> 3084 as -> originated
12 -> 6 as -> a
6 -> 195 a -> term
6 -> 12 a -> as
195 -> 2 term -> of
195 -> 6 term -> a
3. Build a Skip-Gram Model
batch_size = 128
embedding_size = 128
skip_window = 1
num_skips = 2
print ("Parameters ready")
Parameters ready
valid_size = 32
valid_window = 200
valid_examples = np.random.choice(valid_window, valid_size, replace=False)
print (valid_examples)
[ 31 89 64 57 122 178 173 13 50 176 12 188 0 19 168 44 59 130
126 75 187 161 10 194 119 131 5 69 150 165 6 70]
Define network
train_inputs = tf.placeholder(tf.int32, shape=[batch_size])
train_labels = tf.placeholder(tf.int32, shape=[batch_size, 1])
valid_dataset = tf.constant(valid_examples, dtype=tf.int32)
with tf.variable_scope("EMBEDDING"):
with tf.device('/cpu:0'):
embeddings = tf.Variable(
tf.random_uniform([vocabulary_size, embedding_size]
, -1.0, 1.0))
embed = tf.nn.embedding_lookup(embeddings, train_inputs)
with tf.variable_scope("NCE_WEIGHT"):
nce_weights = tf.Variable(
tf.truncated_normal([vocabulary_size, embedding_size],
stddev=1.0 / math.sqrt(embedding_size)))
nce_biases = tf.Variable(tf.zeros([vocabulary_size]))
print ("Network ready")
Network ready
Define functions
with tf.device('/cpu:0'):
num_sampled = 64
loss = tf.reduce_mean(
tf.nn.nce_loss(nce_weights, nce_biases, embed
, train_labels, num_sampled, vocabulary_size))
optm = tf.train.GradientDescentOptimizer(1.0).minimize(loss)
norm = tf.sqrt(tf.reduce_sum(tf.square(embeddings), 1, keep_dims=True))
normalized_embeddings = embeddings / norm
valid_embeddings = tf.nn.embedding_lookup(normalized_embeddings
, valid_dataset)
siml = tf.matmul(valid_embeddings, normalized_embeddings
, transpose_b=True)
print ("Functions Ready")
Functions Ready
4. Train a Skip-Gram Model
sess = tf.Session()
sess.run(tf.initialize_all_variables())
summary_writer = tf.train.SummaryWriter('/tmp/tf_logs/word2vec', graph=sess.graph)
average_loss = 0
num_steps = 100001
for iter in xrange(num_steps):
batch_inputs, batch_labels = generate_batch(batch_size, num_skips, skip_window)
feed_dict = {train_inputs : batch_inputs, train_labels : batch_labels}
_, loss_val = sess.run([optm, loss], feed_dict=feed_dict)
average_loss += loss_val
if iter % 2000 == 0:
average_loss /= 2000
print ("Average loss at step %d is %.3f" % (iter, average_loss))
if iter % 10000 == 0:
siml_val = sess.run(siml)
for i in xrange(valid_size):
valid_word = reverse_dictionary[valid_examples[i]]
top_k = 6
nearest = (-siml_val[i, :]).argsort()[1:top_k+1]
log_str = "Nearest to '%s':" % valid_word
for k in xrange(top_k):
close_word = reverse_dictionary[nearest[k]]
log_str = "%s '%s'," % (log_str, close_word)
print(log_str)
final_embeddings = sess.run(normalized_embeddings)
Average loss at step 0 is 0.141
Nearest to 'an': 'yorktown', 'fux', 'katydids', 'leary', 'interruption', 'detox',
Nearest to 'called': 'wong', 'germaine', 'electrophilic', 'kilpatrick', 'alkenes', 'retained',
Nearest to 'american': 'mq', 'reef', 'guang', 'seas', 'puma', 'rq',
Nearest to 'who': 'scarred', 'directory', 'spate', 'denison', 'incensed', 'adipose',
Nearest to 'c': 'chapman', 'charlize', 'lading', 'ethnographers', 'stingray', 'vainly',
Nearest to 'set': 'emptive', 'menelik', 'headed', 'unsubstantiated', 'churchyard', 'horticultural',
Nearest to 'different': 'unreleased', 'arameans', 'psychologist', 'earmarked', 'phylum', 'ayer',
Nearest to 'eight': 'specificity', 'leftover', 'fulfil', 'urgell', 'oak', 'columba',
Nearest to 'all': 'transport', 'linspire', 'eo', 'donatello', 'georgi', 'picturesque',
Nearest to 'do': 'megabits', 'condorcet', 'landau', 'coincidental', 'ransom', 'proper',
Nearest to 'as': 'yesterday', 'hw', 'solace', 'modeled', 'hats', 'conant',
Nearest to 'law': 'gleaned', 'fickle', 'expressive', 'gory', 'diem', 'threatens',
Nearest to 'UNK': 'probate', 'guests', 'determines', 'dave', 'ubiquity', 'inks',
Nearest to 'by': 'parton', 'mccann', 'mahoney', 'diasporas', 'benefiting', 'nieuwe',
Nearest to 'large': 'towers', 'multiculturalism', 'endowment', 'enhancing', 'brainwashing', 'eia',
Nearest to 'their': 'ecc', 'somber', 'quaternary', 'schopenhauer', 'trombone', 'brethren',
Nearest to 'used': 'shrunk', 'fixtures', 'ultraviolet', 'volley', 'hab', 'spiced',
Nearest to 'british': 'equinox', 'shandy', 'socialism', 'revert', 'zeeland', 'progs',
Nearest to 'x': 'callous', 'envoys', 'gamecube', 'unintelligent', 'rosicrucian', 'participated',
Nearest to 'd': 'francesco', 'schumacher', 'creighton', 'tubas', 'indulgence', 'dip',
Nearest to 'king': 'circumscribed', 'niacin', 'inter', 'bluescreen', 'catapult', 'farnese',
Nearest to 'based': 'oj', 'odi', 'fubar', 'jogaila', 'enables', 'refrigerated',
Nearest to 'two': 'orbits', 'hostel', 'skeleton', 'factories', 'borghese', 'panned',
Nearest to 'international': 'da', 'confidential', 'hiv', 'rhythmic', 'incipient', 'talkie',
Nearest to 'him': 'reelection', 'trivia', 'counters', 'lsch', 'visual', 'seaport',
Nearest to 'year': 'overwhelming', 'astaire', 'conclude', 'donner', 'honky', 'objects',
Nearest to 'in': 'events', 'golem', 'elbert', 'lung', 'rsc', 'coordinated',
Nearest to 'may': 'sur', 'formalized', 'inasmuch', 'telekinetic', 'bisexual', 'duchamp',
Nearest to 'g': 'aruban', 'africans', 'jason', 'perutz', 'stun', 'hahn',
Nearest to 'de': 'compactification', 'brugge', 'disarming', 'plotted', 'env', 'fielder',
Nearest to 'a': 'ally', 'motorola', 'concrete', 'catcher', 'necks', 'mortimer',
Nearest to 'than': 'karts', 'gwynedd', 'hesse', 'agglutinative', 'there', 'ensues',
Average loss at step 2000 is 114.071
Average loss at step 4000 is 52.629
Average loss at step 6000 is 33.005
Average loss at step 8000 is 23.590
Average loss at step 10000 is 17.952
Nearest to 'an': 'the', 'overseas', 'protein', 'interruption', 'victoriae', 'mya',
Nearest to 'called': 'gland', 'within', 'gb', 'much', 'retained', 'consists',
Nearest to 'american': 'olympics', 'methadone', 'linguistic', 'technologically', 'while', 'spider',
Nearest to 'who': 'and', 'directory', 'named', 'attacked', 'mode', 'ruth',
Nearest to 'c': 'victoriae', 'accounts', 'mathbf', 'reginae', 'austin', 'passion',
Nearest to 'set': 'reginae', 'shortcuts', 'animals', 'few', 'members', 'majority',
Nearest to 'different': 'mya', 'unreleased', 'cl', 'phylum', 'psychologist', 'reginae',
Nearest to 'eight': 'nine', 'zero', 'six', 'reginae', 'agave', 'vs',
Nearest to 'all': 'transport', 'beginning', 'bestseller', 'cl', 'waugh', 'lindbergh',
Nearest to 'do': 'vs', 'proper', 'assistant', 'symbols', 'reflect', 'christian',
Nearest to 'as': 'in', 'for', 'and', 'by', 'irish', 'asterism',
Nearest to 'law': 'collapse', 'cc', 'soviet', 'accordion', 'badges', 'kyoto',
Nearest to 'UNK': 'and', 'alpina', 'mengele', 'the', 'reginae', 'one',
Nearest to 'by': 'in', 'and', 'as', 'at', 'gland', 'was',
Nearest to 'large': 'towers', 'gland', 'fricatives', 'conducted', 'greatest', 'charlie',
Nearest to 'their': 'reginae', 'schopenhauer', 'afghani', 'the', 'sabotage', 'implicit',
Nearest to 'used': 'spiced', 'mystery', 'mathbf', 'sacred', 'mining', 'fixtures',
Nearest to 'british': 'anatomy', 'socialism', 'equinox', 'victoriae', 'astor', 'five',
Nearest to 'x': 'phi', 'right', 'participated', 'modern', 'countries', 'video',
Nearest to 'd': 'finalist', 'avoid', 'tubing', 'vs', 'francesco', 'schumacher',
Nearest to 'king': 'inter', 'thompson', 'negligible', 'moves', 'alpina', 'wisconsin',
Nearest to 'based': 'reginae', 'chemist', 'dim', 'directory', 'traditionally', 'agave',
Nearest to 'two': 'one', 'reginae', 'vs', 'austin', 'gollancz', 'three',
Nearest to 'international': 'da', 'hiv', 'confidential', 'access', 'six', 'robots',
Nearest to 'him': 'infectious', 'trivia', 'spontaneous', 'seaport', 'directors', 'visual',
Nearest to 'year': 'conclude', 'objects', 'overwhelming', 'clear', 'responsibility', 'vs',
Nearest to 'in': 'and', 'of', 'mya', 'with', 'on', 'by',
Nearest to 'may': 'sur', 'cannot', 'tubing', 'formalized', 'individualist', 'faure',
Nearest to 'g': 'eight', 'aruban', 'jason', 'africans', 'i', 'am',
Nearest to 'de': 'publicly', 'oxus', 'prize', 'shortly', 'course', 'aa',
Nearest to 'a': 'the', 'austin', 'UNK', 'and', 'reginae', 'alpina',
Nearest to 'than': 'karts', 'community', 'hesse', 'there', 'racial', 'caves',
Average loss at step 12000 is 13.873
Average loss at step 14000 is 11.914
Average loss at step 16000 is 9.810
Average loss at step 18000 is 8.702
Average loss at step 20000 is 7.841
Nearest to 'an': 'the', 'protein', 'overseas', 'their', 'interruption', 'counterexample',
Nearest to 'called': 'within', 'gland', 'hiroshima', 'litigants', 'dasyprocta', 'clan',
Nearest to 'american': 'and', 'methadone', 'olympics', 'while', 'technologically', 'certainty',
Nearest to 'who': 'and', 'attacked', 'also', 'ruth', 'named', 'agouti',
Nearest to 'c': 'eight', 'victoriae', 'accounts', 'one', 'blog', 'chapman',
Nearest to 'set': 'reginae', 'shortcuts', 'astoria', 'headquarters', 'members', 'few',
Nearest to 'different': 'unreleased', 'mya', 'cl', 'agouti', 'psychologist', 'truetype',
Nearest to 'eight': 'nine', 'six', 'zero', 'five', 'seven', 'three',
Nearest to 'all': 'bestseller', 'beginning', 'transport', 'waugh', 'cl', 'lindbergh',
Nearest to 'do': 'condorcet', 'vs', 'proper', 'assistant', 'reflect', 'symbols',
Nearest to 'as': 'and', 'for', 'by', 'was', 'is', 'in',
Nearest to 'law': 'agouti', 'threatens', 'collapse', 'clem', 'sumer', 'soviet',
Nearest to 'UNK': 'agouti', 'alpina', 'victoriae', 'reginae', 'dasyprocta', 'and',
Nearest to 'by': 'was', 'and', 'in', 'from', 'as', 'with',
Nearest to 'large': 'towers', 'aquila', 'enhancing', 'gland', 'fricatives', 'additions',
Nearest to 'their': 'the', 'reginae', 'his', 'afghani', 'a', 'this',
Nearest to 'used': 'spiced', 'mystery', 'haliotis', 'mining', 'ultraviolet', 'algol',
Nearest to 'british': 'equinox', 'anatomy', 'astor', 'socialism', 'victoriae', 'vivian',
Nearest to 'x': 'actaeon', 'envoys', 'four', 'agouti', 'apatosaurus', 'eight',
Nearest to 'd': 'b', 'and', 'francesco', 'finalist', 'asphyxia', 'one',
Nearest to 'king': 'circumscribed', 'inter', 'niacin', 'iphigenia', 'four', 'moves',
Nearest to 'based': 'chemist', 'charlie', 'encryption', 'reginae', 'competitions', 'dim',
Nearest to 'two': 'one', 'three', 'five', 'nine', 'six', 'four',
Nearest to 'international': 'da', 'UNK', 'hiv', 'confidential', 'aloe', 'length',
Nearest to 'him': 'seaport', 'spontaneous', 'infectious', 'trivia', 'directors', 'marine',
Nearest to 'year': 'conclude', 'five', 'overwhelming', 'responsibility', 'objects', 'subkey',
Nearest to 'in': 'and', 'with', 'of', 'on', 'mya', 'from',
Nearest to 'may': 'sur', 'cannot', 'can', 'seleucid', 'agouti', 'tubing',
Nearest to 'g': 'agouti', 'aruban', 'eight', 'jason', 'i', 'dasyprocta',
Nearest to 'de': 'fita', 'marischal', 'publicly', 'shortly', 'electrophoresis', 'winner',
Nearest to 'a': 'the', 'agouti', 'reginae', 'victoriae', 'and', 'afghani',
Nearest to 'than': 'community', 'karts', 'hesse', 'caves', 'eight', 'ensues',
Average loss at step 22000 is 7.241
5. Visualize the embeding
def plot_with_labels(low_dim_embs, labels, filename='tsne.png'):
assert low_dim_embs.shape[0] >= len(labels), "More labels than embeddings"
plt.figure(figsize=(18, 18))
for i, label in enumerate(labels):
x, y = low_dim_embs[i,:]
plt.scatter(x, y)
plt.annotate(label,
xy=(x, y),
xytext=(5, 2),
textcoords='offset points',
ha='right',
va='bottom')
plt.show()
tsne = TSNE(perplexity=30, n_components=2, init='pca', n_iter=5000)
plot_only = 500
low_dim_embs = tsne.fit_transform(final_embeddings[:plot_only,:])
labels = [reverse_dictionary[i] for i in xrange(plot_only)]
plot_with_labels(low_dim_embs, labels)