实现 TF-IDF
由于我们可以为每个单词选择嵌入,我们可能会决定更改某些单词的加权。一种这样的策略是增加有用的单词和减轻过度常见或罕见单词的权重。我们将在此秘籍中探索的嵌入是尝试实现此目的。
做好准备
TF-IDF 是一个缩写,代表文本频率 - 反向文档频率。该术语基本上是每个单词的文本频率和反向文档频率的乘积。
在前面的秘籍中,我们介绍了词袋方法,它为句子中每个单词的出现赋值为 1。这可能并不理想,因为每个类别的句子(前一个秘籍中的垃圾邮件和火腿)很可能具有the,and和其他单词的相同频率,而诸如 V iagra和sale之类的单词]可能应该更加重视查明文本是否是垃圾邮件。
首先,我们要考虑词频。在这里,我们考虑单个条目中单词出现的频率。这部分(TF)的目的是找到在每个条目中看起来很重要的术语。
但是the和and等词可能会在每个条目中频繁出现。我们希望减轻这些单词的重要性,因此将前面的文本频率(TF)乘以整个文档频率的倒数可能有助于找到重要的单词。然而,由于文本集(语料库)可能非常大,因此通常采用逆文档频率的对数。这为我们留下了每个文档条目中每个单词的 TF-IDF 的以下公式:
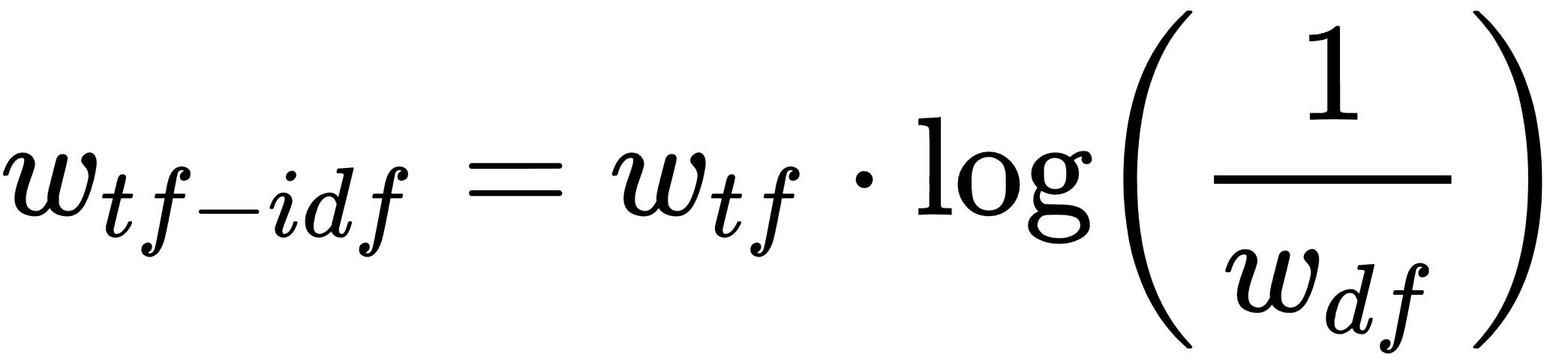
这里w<sub>tf</sub>是文档中的单词频率,w<sub>df</sub> 是所有文档中这些单词的总频率。有意义的是,TF-IDF 的高值可能表示在确定文档内容时非常重要的单词。
创建 TF-IDF 向量要求我们将所有文本加载到内存中,并在开始训练模型之前计算每个单词的出现次数。因此,它没有在 TensorFlow 中完全实现,因此我们将使用 scikit-learn 来创建我们的 TF-IDF 嵌入,但是使用 TensorFlow 来适应逻辑模型。
操作步骤
我们将按如下方式处理秘籍:
- 我们将从加载必要的库开始。这次,我们正在为我们的文本加载 scikit-learn TF-IDF 预处理库。使用以下代码执行此操作:
import tensorflow as tf
import matplotlib.pyplot as plt
import csv
import numpy as np
import os
import string
import requests
import io
import nltk
from zipfile import ZipFile
from sklearn.feature_extraction.text import TfidfVectorizer
- 我们将开始一个图会话,并为我们的词汇表声明我们的批量大小和最大特征尺寸:
sess = tf.Session()
batch_size= 200
max_features = 1000
- 接下来,我们将从 Web 或我们的
temp数据文件夹中加载数据(如果我们之前已保存过)。使用以下代码执行此操作:
save_file_name = os.path.join('temp','temp_spam_data.csv')
if os.path.isfile(save_file_name):
text_data = []
with open(save_file_name, 'r') as temp_output_file:
reader = csv.reader(temp_output_file)
for row in reader:
text_data.append(row)
else:
zip_url = 'http://archive.ics.uci.edu/ml/machine-learning-databases/00228/smsspamcollection.zip'
r = requests.get(zip_url)
z = ZipFile(io.BytesIO(r.content))
file = z.read('SMSSpamCollection')
# Format Data
text_data = file.decode()
text_data = text_data.encode('ascii',errors='ignore')
text_data = text_data.decode().split('\n')
text_data = [x.split('\t') for x in text_data if len(x)>=1]
# And write to csv
with open(save_file_name, 'w') as temp_output_file:
writer = csv.writer(temp_output_file)
writer.writerows(text_data)
texts = [x[1] for x in text_data]
target = [x[0] for x in text_data]
# Relabel 'spam' as 1, 'ham' as 0
target = [1\. if x=='spam' else 0\. for x in target]
- 就像前面的秘籍一样,我们将通过将所有内容转换为小写,删除标点符号并删除数字来减少词汇量:
# Lower case
texts = [x.lower() for x in texts]
# Remove punctuation
texts = [''.join(c for c in x if c not in string.punctuation) for x in texts]
# Remove numbers
texts = [''.join(c for c in x if c not in '0123456789') for x in texts]
# Trim extra whitespace
texts = [' '.join(x.split()) for x in texts]
- 为了使用 scikt-learn 的 TF-IDF 处理函数,我们必须告诉它如何标记我们的句子。通过这个,我们只是指如何将句子分解为相应的单词。我们已经为我们构建了一个很好的标记器:
nltk软件包可以很好地将句子分解为相应的单词:
def tokenizer(text):
words = nltk.word_tokenize(text)
return words
# Create TF-IDF of texts
tfidf = TfidfVectorizer(tokenizer=tokenizer, stop_words='english', max_features=max_features)
sparse_tfidf_texts = tfidf.fit_transform(texts)
- 接下来,我们将数据集分解为测试和训练集。使用以下代码执行此操作:
train_indices = np.random.choice(sparse_tfidf_texts.shape[0], round(0.8*sparse_tfidf_texts.shape[0]), replace=False)
test_indices = np.array(list(set(range(sparse_tfidf_texts.shape[0])) - set(train_indices)))
texts_train = sparse_tfidf_texts[train_indices]
texts_test = sparse_tfidf_texts[test_indices]
target_train = np.array([x for ix, x in enumerate(target) if ix in train_indices])
target_test = np.array([x for ix, x in enumerate(target) if ix in test_indices])
- 现在我们声明我们的逻辑回归模型变量和我们的数据占位符:
A = tf.Variable(tf.random_normal(shape=[max_features,1]))
b = tf.Variable(tf.random_normal(shape=[1,1]))
# Initialize placeholders
x_data = tf.placeholder(shape=[None, max_features], dtype=tf.float32)
y_target = tf.placeholder(shape=[None, 1], dtype=tf.float32)
- 我们现在可以声明模型操作和损失函数。请记住,逻辑回归的 sigmoid 部分在我们的损失函数中。使用以下代码执行此操作:
model_output = tf.add(tf.matmul(x_data, A), b)
loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=model_output, labels=y_target))
- 我们将预测和精度函数添加到图中,以便在我们的模型训练时我们可以看到训练和测试集的准确率:
prediction = tf.round(tf.sigmoid(model_output))
predictions_correct = tf.cast(tf.equal(prediction, y_target), tf.float32)
accuracy = tf.reduce_mean(predictions_correct)
- 然后我们将声明一个优化器并初始化我们的图变量:
my_opt = tf.train.GradientDescentOptimizer(0.0025)
train_step = my_opt.minimize(loss)
# Intitialize Variables
init = tf.global_variables_initializer()
sess.run(init)
- 我们现在将训练我们的模型超过 10,000 代,并记录每 100 代的测试/训练损失和准确率,每 500 代打印一次。使用以下代码执行此操作:
train_loss = []
test_loss = []
train_acc = []
test_acc = []
i_data = []
for i in range(10000):
rand_index = np.random.choice(texts_train.shape[0], size=batch_size)
rand_x = texts_train[rand_index].todense()
rand_y = np.transpose([target_train[rand_index]])
sess.run(train_step, feed_dict={x_data: rand_x, y_target: rand_y})
# Only record loss and accuracy every 100 generations
if (i+1)%100==0:
i_data.append(i+1)
train_loss_temp = sess.run(loss, feed_dict={x_data: rand_x, y_target: rand_y})
train_loss.append(train_loss_temp)
test_loss_temp = sess.run(loss, feed_dict={x_data: texts_test.todense(), y_target: np.transpose([target_test])})
test_loss.append(test_loss_temp)
train_acc_temp = sess.run(accuracy, feed_dict={x_data: rand_x, y_target: rand_y})
train_acc.append(train_acc_temp)
test_acc_temp = sess.run(accuracy, feed_dict={x_data: texts_test.todense(), y_target: np.transpose([target_test])})
test_acc.append(test_acc_temp)
if (i+1)%500==0:
acc_and_loss = [i+1, train_loss_temp, test_loss_temp, train_acc_temp, test_acc_temp]
acc_and_loss = [np.round(x,2) for x in acc_and_loss]
print('Generation # {}. Train Loss (Test Loss): {:.2f} ({:.2f}). Train Acc (Test Acc): {:.2f} ({:.2f})'.format(*acc_and_loss))
- 这导致以下输出:
Generation # 500\. Train Loss (Test Loss): 0.69 (0.73). Train Acc (Test Acc): 0.62 (0.57)
Generation # 1000\. Train Loss (Test Loss): 0.62 (0.63). Train Acc (Test Acc): 0.68 (0.66)
...
Generation # 9500\. Train Loss (Test Loss): 0.39 (0.45). Train Acc (Test Acc): 0.89 (0.85)
Generation # 10000\. Train Loss (Test Loss): 0.48 (0.45). Train Acc (Test Acc): 0.84 (0.85)
以下是绘制训练和测试装置的准确率和损耗的绘图:
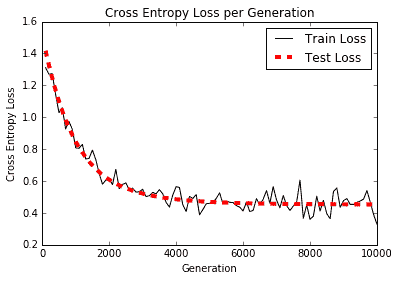
图 2:根据 TF-IDF 值构建的物流垃圾邮件模型的交叉熵损失
训练和测试精度图如下:
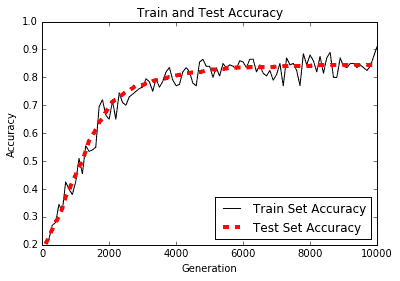
图 3:根据 TF-IDF 值构建的逻辑垃圾邮件模型的训练和测试集精度
工作原理
使用模型的 TF-IDF 值增加了我们对先前的词袋模型的预测,从 80%的准确率到接近 90%的准确率。我们通过使用 scikit-learn 的 TF-IDF 词汇处理函数并使用这些 TF-IDF 值进行逻辑回归来实现这一目标。
更多
虽然我们可能已经解决了重要性这个问题,但我们还没有解决字序问题。词袋和 TF-IDF 都没有考虑句子中的单词的顺序特征。我们将在接下来的几节中尝试解决这个问题,这将向我们介绍 word2vec 技术。