使用 CBOW 嵌入
在这个秘籍中,我们将实现 word2vec 的 CBOW(连续词袋)方法。它与Skip-Gram方法非常相似,除了我们预测来自环境词周围窗口的单个目标词。
做好准备
在这个秘籍中,我们将实现 word2vec 的CBOW方法。它与Skip-Gram方法非常相似,只是我们预测来自环境词周围窗口的单个目标词。
在前面的示例中,我们将窗口和目标的每个组合视为一组配对的输入和输出,但是使用 CBOW,我们将周围的窗口嵌入添加到一起以获得一个嵌入来预测目标字嵌入:
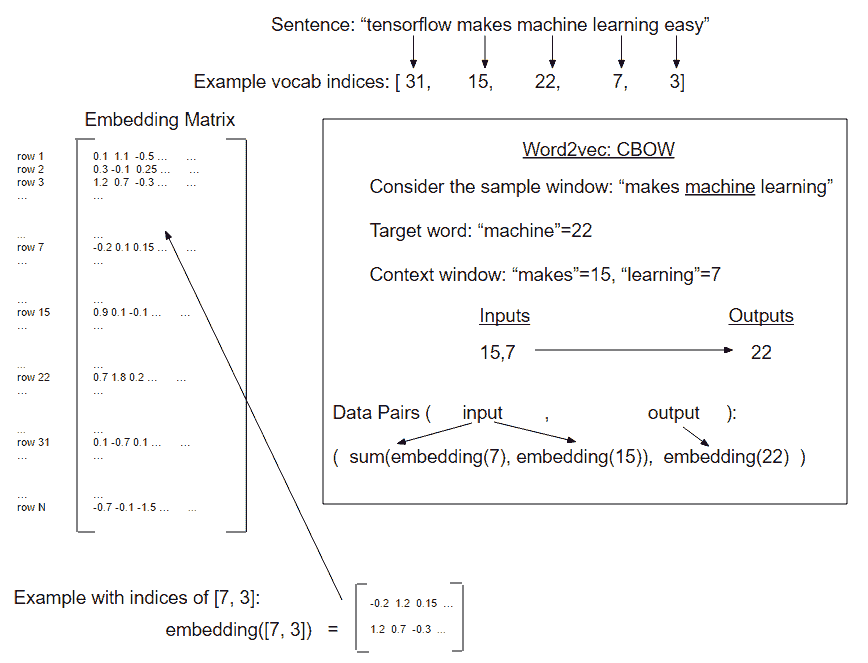
图 5:如何在一个例子的窗口上创建 CBOW 嵌入数据的描述(每侧窗口大小= 1)
大多数代码都保持不变,除了我们需要改变我们创建嵌入的方式以及如何从句子生成数据。
为了使代码更易于阅读,我们已将所有主要函数移动到同一目录中名为text_helpers.py的单独文件中。此函数保存数据加载,文本正则化,字典创建和批量生成函数。除非另有说明,否则这些函数与使用 Skip-Gram Embeddings 秘籍中显示的完全相同。
操作步骤
我们将按如下方式处理秘籍:
- 我们将首先加载必要的库,包括前面提到的
text_helpers.py脚本,我们将把我们的函数用于文本加载和操作。然后我们将开始一个图会话:
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
import random
import os
import pickle
import string
import requests
import collections
import io
import tarfile
import urllib.request
import text_helpers
from nltk.corpus import stopwords
sess = tf.Session()
- 我们要确保在开始保存之前存在临时数据和参数保存文件夹。使用以下代码检查:
# Make a saving directory if it doesn't exist
data_folder_name = 'temp'
if not os.path.exists(data_folder_name):
os.makedirs(data_folder_name)
- 然后我们将声明模型的参数,这与我们在上一个秘籍中对
Skip-Gram方法所做的类似:
# Declare model parameters
batch_size = 500
embedding_size = 200
vocabulary_size = 2000
generations = 50000
model_learning_rate = 0.001
num_sampled = int(batch_size/2
window_size = 3
# Add checkpoints to training
save_embeddings_every = 5000
print_valid_every = 5000
print_loss_every = 100
# Declare stop words
stops = stopwords.words('english')
# We pick some test words. We are expecting synonyms to appear
valid_words = ['love', 'hate', 'happy', 'sad', 'man', 'woman']
- 我们已将数据加载和文本正则化函数移动到我们在开始时导入的单独文件中,此文件在 github 仓库中都可用, https://github.com/nfmcclure/tensorflow_cookbook/tree/master/ 07_Natural_Language_Processing / 05_Working_With_CBOW_Embeddings 和 Packt 仓库, https://github.com/PacktPublishing/TensorFlow-Machine-Learning-Cookbook-Second-Edition 。现在我们可以打电话给他们我们也只想要包含三个或更多单词的评论。使用以下代码:
texts, target = text_helpers.load_movie_data(data_folder_name) texts = text_helpers.normalize_text(texts, stops) # Texts must contain at least 3 words target = [target[ix] for ix, x in enumerate(texts) if len(x.split()) > 2] texts = [x for x in texts if len(x.split()) > 2]
- 现在我们将创建我们的词汇词典,这将帮助我们查找单词。当我们想要打印出最接近我们验证集的单词时,我们还需要一个反向字典来查找索引中的单词:
word_dictionary = text_helpers.build_dictionary(texts,
vocabulary_size)
word_dictionary_rev = dict(zip(word_dictionary.values(), word_dictionary.keys()))
text_data = text_helpers.text_to_numbers(texts, word_dictionary)
# Get validation word keys
valid_examples = [word_dictionary[x] for x in valid_words]
- 接下来,我们将初始化我们想要拟合的单词嵌入,并声明模型数据占位符。使用以下代码执行此操作:
embeddings = tf.Variable(tf.random_uniform([vocabulary_size, embedding_size], -1.0, 1.0))
# Create data/target placeholders
x_inputs = tf.placeholder(tf.int32, shape=[batch_size,
2*window_size])
y_target = tf.placeholder(tf.int32, shape=[batch_size, 1])
valid_dataset = tf.constant(valid_examples, dtype=tf.int32)
- 我们现在可以创建一种处理嵌入一词的方法。由于 CBOW 模型添加了上下文窗口的嵌入,我们将创建一个循环并将所有嵌入添加到窗口中:
# Lookup the word embeddings and
# Add together window embeddings:
embed = tf.zeros([batch_size, embedding_size])
for element in range(2*window_size):
embed += tf.nn.embedding_lookup(embeddings, x_inputs[:, element])
- 我们将使用 TensorFlow 中内置的噪声对比误差损失函数,因为我们的分类输出太稀疏,无法使 softmax 收敛,如下所示:
# NCE loss parameters
nce_weights = tf.Variable(tf.truncated_normal([vocabulary_size,
embedding_size], stddev=1.0 / np.sqrt(embedding_size)))
nce_biases = tf.Variable(tf.zeros([vocabulary_size]))
# Declare loss function (NCE)
loss = tf.reduce_mean(tf.nn.nce_loss(weights=nce_weights,
biases=nce_biases,
inputs=embed,
labels=y_target,
num_sampled=num_sampled,
num_classes=vocabulary_size))
- 就像我们在 Skip-Gram 秘籍中所做的那样,我们将使用余弦相似性来打印离我们的验证字数据集最近的单词,以了解我们的嵌入如何工作。使用以下代码执行此操作:
norm = tf.sqrt(tf.reduce_sum(tf.square(embeddings), 1, keepdims=True))
normalized_embeddings = embeddings / norm
valid_embeddings = tf.nn.embedding_lookup(normalized_embeddings, valid_dataset)
similarity = tf.matmul(valid_embeddings, normalized_embeddings, transpose_b=True)
- 要保存嵌入,我们必须加载 TensorFlow
train.Saver方法。这个方法默认保存整个图,但是我们可以给它一个参数来保存嵌入变量,我们也可以给它一个特定的名称。在这里,我们给它的名称与图中的变量名称相同:
saver = tf.train.Saver({"embeddings": embeddings})
- 我们现在将声明我们的优化函数并初始化我们的模型变量。使用以下代码执行此操作:
optimizer = tf.train.GradientDescentOptimizer(learning_rate=model_learning_rate).minimize(loss)
init = tf.global_variables_initializer()
sess.run(init)
- 最后,我们可以遍历我们的训练步骤,打印出损失,并将我们指定的嵌入和字典保存到:
loss_vec = []
loss_x_vec = []
for i in range(generations):
batch_inputs, batch_labels = text_helpers.generate_batch_data(text_data, batch_size, window_size, method='cbow')
feed_dict = {x_inputs : batch_inputs, y_target : batch_labels}
# Run the train step
sess.run(optimizer, feed_dict=feed_dict)
# Return the loss
if (i+1) % print_loss_every == 0:
loss_val = sess.run(loss, feed_dict=feed_dict)
loss_vec.append(loss_val)
loss_x_vec.append(i+1)
print('Loss at step {} : {}'.format(i+1, loss_val))
# Validation: Print some random words and top 5 related words
if (i+1) % print_valid_every == 0:
sim = sess.run(similarity, feed_dict=feed_dict)
for j in range(len(valid_words)):
valid_word = word_dictionary_rev[valid_examples[j]]
top_k = 5 # number of nearest neighbors
nearest = (-sim[j, :]).argsort()[1:top_k+1]
log_str = "Nearest to {}:".format(valid_word)
for k in range(top_k):
close_word = word_dictionary_rev[nearest[k]]
print_str = '{} {},'.format(log_str, close_word)
print(print_str)
# Save dictionary + embeddings
if (i+1) % save_embeddings_every == 0:
# Save vocabulary dictionary
with open(os.path.join(data_folder_name,'movie_vocab.pkl'), 'wb') as f:
pickle.dump(word_dictionary, f)
# Save embeddings
model_checkpoint_path = os.path.join(os.getcwd(),data_folder_name,'cbow_movie_embeddings.ckpt')
save_path = saver.save(sess, model_checkpoint_path)
print('Model saved in file: {}'.format(save_path))
- 这导致以下输出:
Loss at step 100 : 62.04829025268555
Loss at step 200 : 33.182334899902344
...
Loss at step 49900 : 1.6794960498809814
Loss at step 50000 : 1.5071022510528564
Nearest to love: clarity, cult, cliched, literary, memory,
Nearest to hate: bringing, gifted, almost, next, wish,
Nearest to happy: ensemble, fall, courage, uneven, girls,
Nearest to sad: santa, devoid, biopic, genuinely, becomes,
Nearest to man: project, stands, none, soul, away,
Nearest to woman: crush, even, x, team, ensemble,
Model saved in file: .../temp/cbow_movie_embeddings.ckpt
text_helpers.py文件中除了一个函数之外的所有函数都具有直接来自上一个秘籍的函数。我们将通过添加cbow方法对generate_batch_data()函数稍加补充,如下所示:
elif method=='cbow':
batch_and_labels = [(x[:y] + x[(y+1):], x[y]) for x,y in zip(window_sequences, label_indices)]
# Only keep windows with consistent 2*window_size
batch_and_labels = [(x,y) for x,y in batch_and_labels if len(x)==2*window_size]
batch, labels = [list(x) for x in zip(*batch_and_labels)]
工作原理
此秘籍与使用 Skip-Gram 创建嵌入非常相似。主要区别在于我们如何生成数据并组合嵌入。
对于这个秘籍,我们加载数据,正则化文本,创建词汇词典,使用字典查找嵌入,组合嵌入,并训练神经网络来预测目标词。
更多
值得注意的是,CBOW方法训练周围窗口的累加嵌入以预测目标字。这样做的一个结果是来自 word2vec 的CBOW方法具有Skip-Gram方法缺乏的平滑效果,并且认为这对于较小的文本数据集可能是优选的是合理的。