使用 t-SNE 可视化单词嵌入
让我们可视化我们在上一节中生成的单词嵌入。 t-SNE 是在二维空间中显示高维数据的最流行的方法。我们将使用 scikit-learn 库中的方法并重用 TensorFlow 文档中给出的代码来绘制我们刚学过的嵌入词的图形。
TensorFlow 文档中的原始代码可从以下链接获得:https://github.com/tensorflow/tensorflow/blob/r1.3/tensorflow/examples/tutorials/word2vec/word2vec_basic.py.
以下是我们如何实现该程序:
- 创建
tsne模型:
tsne = TSNE(perplexity=30, n_components=2,
init='pca', n_iter=5000, method='exact')
- 将要显示的嵌入数限制为 500,否则,图形变得非常难以理解:
n_embeddings = 500
- 通过调用
tsne模型上的fit_transform()方法并将final_embeddings的第一个n_embeddings作为输入来创建低维表示。
low_dim_embeddings = tsne.fit_transform(
final_embeddings[:n_embeddings, :])
- 找到我们为图表选择的单词向量的文本表示:
labels = [ptb.id2word[i] for i in range(n_embeddings)]
- 最后,绘制嵌入图:
plot_with_labels(low_dim_embeddings, labels)
我们得到以下绘图:
 t-SNE visualization of embeddings for PTB data set
t-SNE visualization of embeddings for PTB data set
同样,从 text8 模型中,我们得到以下图:
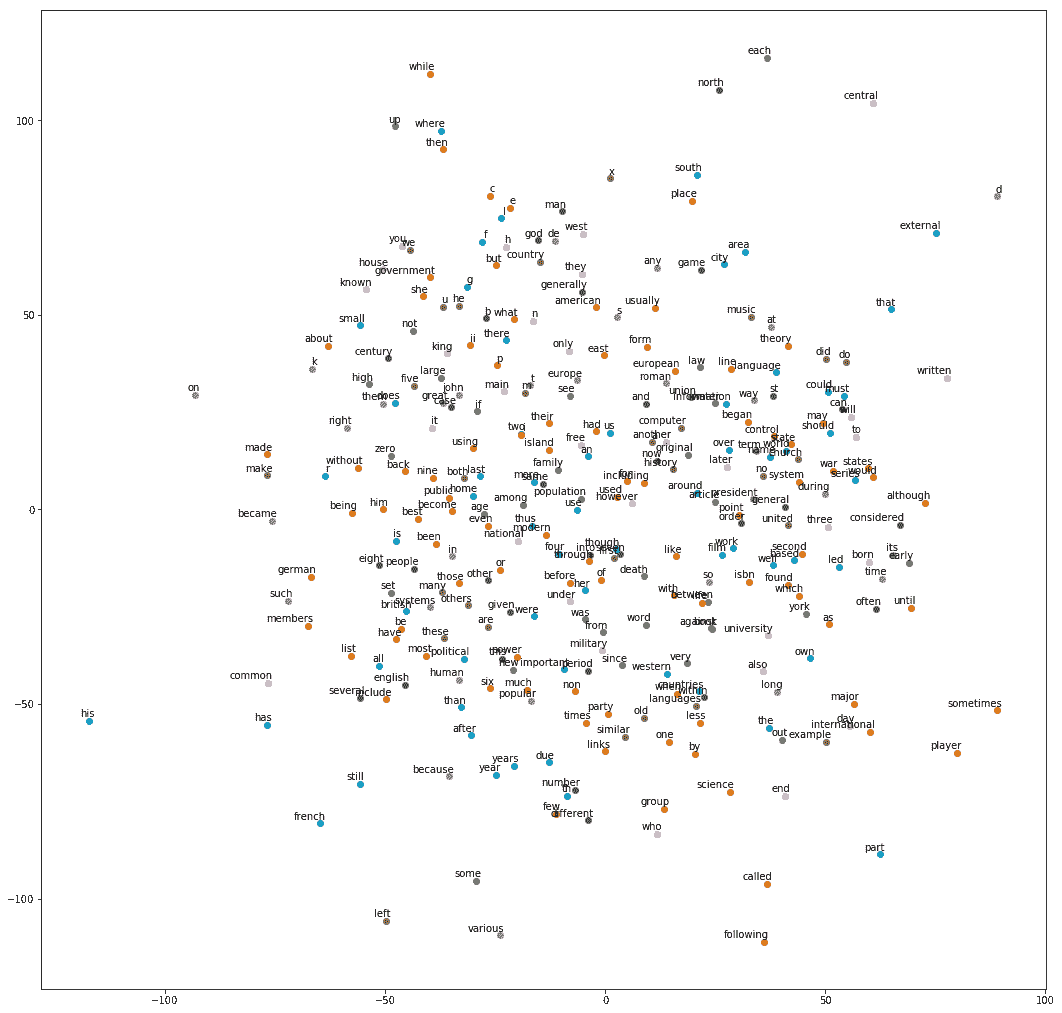 t-SNE visualization of embeddings for text8 data set
t-SNE visualization of embeddings for text8 data set