实现 Q-Learning
Q-Learning 是一种无模型的方法,可以找到可以最大化智能体奖励的最优策略。在最初的游戏过程中,智能体会为每对(状态,动作)学习 Q 值,也称为探索策略,如前面部分所述。一旦学习了 Q 值,那么最优策略将是在每个状态中选择具有最大 Q 值的动作,也称为利用策略。学习算法可以以局部最优解决方案结束,因此我们通过设置exploration_rate参数来继续使用探索策略。
Q-Learning 算法如下:
initialize Q(shape=[#s,#a]) to random values or zeroes
Repeat (for each episode)
observe current state s
Repeat
select an action a (apply explore or exploit strategy)
observe state s_next as a result of action a
update the Q-Table using bellman's equation
set current state s = s_next
until the episode ends or a max reward / max steps condition is reached
Until a number of episodes or a condition is reached
(such as max consecutive wins)
上述算法中的Q(s, )表示我们在前面部分中描述的 Q 函数。此函数的值用于选择操作而不是奖励,因此此函数表示奖励或折扣奖励。使用未来状态中 Q 函数的值更新 Q 函数的值。众所周知的贝尔曼方程捕获了这一更新:
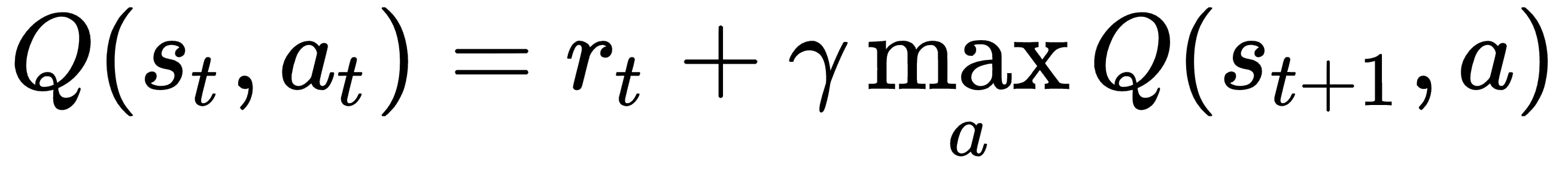
这基本上意味着在时间步骤 t,在状态 s 中,对于动作 a,最大未来奖励(Q)等于来自当前状态的奖励加上来自下一状态的最大未来奖励。
Q(s,a)可以实现为 Q 表或称为 Q 网络的神经网络。在这两种情况下,Q 表或 Q 网络的任务是基于给定输入的 Q 值提供最佳可能的动作。随着 Q 表变大,基于 Q 表的方法通常变得棘手,因此使神经网络成为通过 Q 网络逼近 Q 函数的最佳候选者。让我们看看这两种方法的实际应用。
您可以按照本书代码包中的 Jupyter 笔记本ch-13b_Reinforcement_Learning_DQN中的代码进行操作。