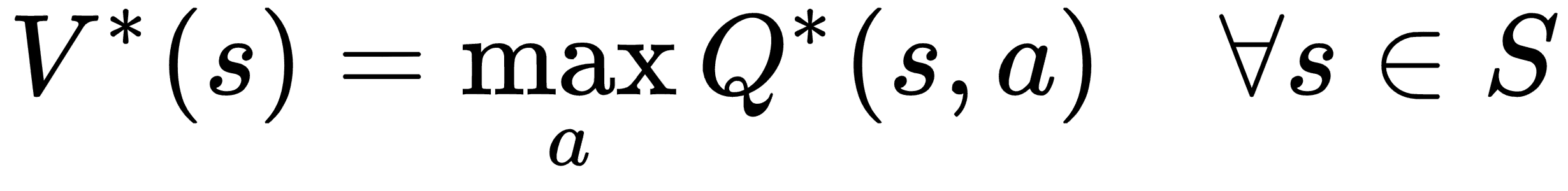V 函数(模型可用时学习优化)
如果事先知道模型,则智能体可以执行策略搜索以找到最大化值函数的最优策略。当模型可用时,智能体使用值函数,该函数可以朴素地定义为未来状态的奖励总和:
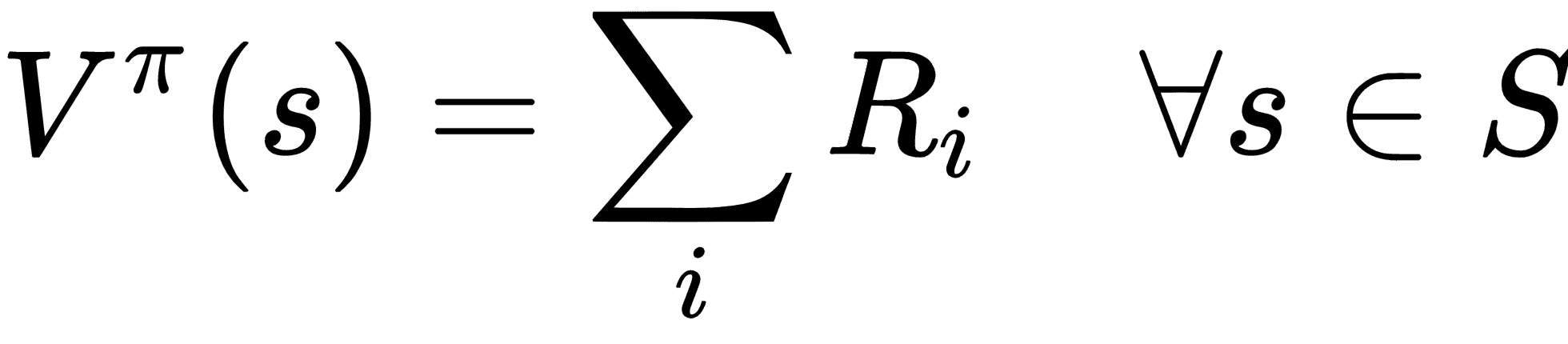
因此,使用策略p选择操作的时间步t的值将是:
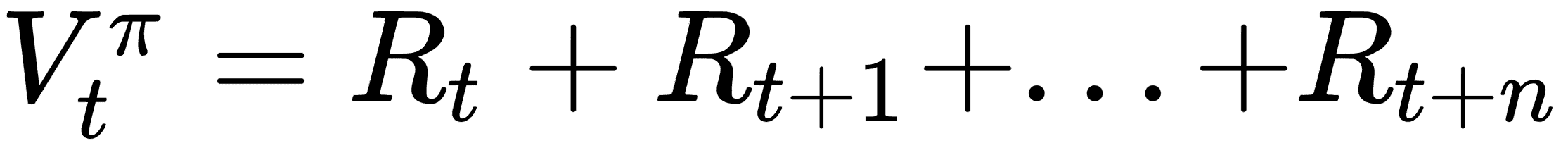
V是值,R是奖励,值函数估计在未来最多n个时间步长。
当智能体使用这种方法估计奖励时,它会平等地将所有行为视为奖励。在极点推车示例中,如果民意调查在步骤 50 处进行,则它将把直到第 50 步的所有步骤视为对跌倒的同等责任。因此,不是添加未来奖励,而是估计未来奖励的加权总和。通常,权重是提高到时间步长的折扣率。如果贴现率为零,则值函数变为上面讨论的幼稚函数,并且如果贴现率的值接近 1,例如 0.9 或 0.92,则与当前奖励相比,未来奖励的影响较小。
因此,现在行动a的时间步t的值将是:
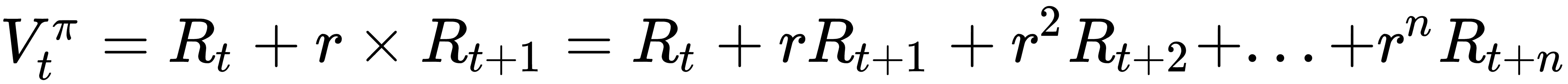
V是值,R是奖励,r是折扣率。
V 函数和 Q 函数之间的关系:
V*(s)是状态s下的最优值函数,其给出最大奖励,并且Q*(s,a)是状态s下的最佳 Q 函数,其通过选择动作a给出最大期望奖励。 因此,V*(s)是所有可能动作中所有最优 Q 函数Q*(s,a)的最大值: