使用 TensorFlow 进行经典机器学习
机器学习是计算机科学领域,涉及算法的研究,开发和应用,以使计算机器从数据中学习。计算机学习的模型用于进行预测和预测。机器学习研究人员和工程师通过构建模型然后使用这些模型进行预测来实现这一目标。现在众所周知,机器学习已成功地应用于各种领域,如自然语言理解,视频处理,图像识别,语音和视觉。
我们来谈谈模型。所有机器学习问题都以一种或另一种形式抽象为以下等式:
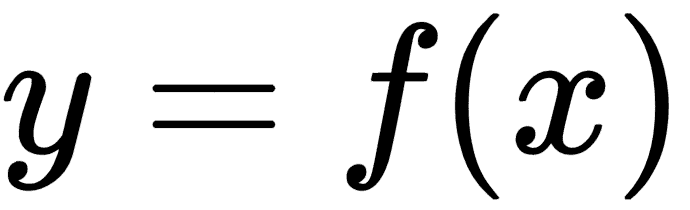
这里,y是输出或目标,x是输入或特征。如果x是一组特征,我们也将其称为特征向量,并用X表示。当我们说模型时,我们的意思是找到将特征映射到目标的函数f。因此,一旦我们找到f,我们就可以使用x的新值来预测y的值。
机器学习的核心是找到可用于从x的值预测y的函数f。正如您可能从高中数学周期回忆的那样,该线的等式如下:

我们可以重写前面的简单等式如下:
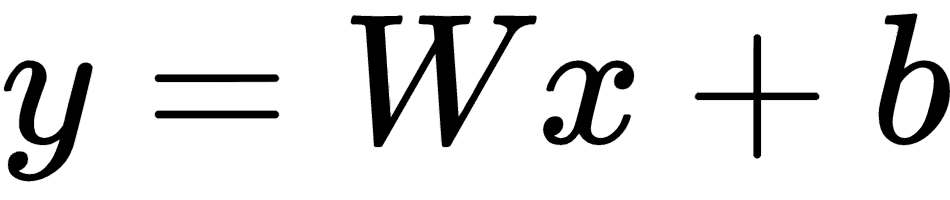
这里,W称为权重,b称为偏差。不要担心现在的权重和偏置,我们稍后会介绍它们。现在,您可以将W视为等效于m和b等效于c。因此,现在机器学习问题可以说是从X的当前值找到W和b的问题,这样该方程可用于预测y的值。
回归分析或回归建模是指用于估计变量之间关系的方法和技术。输入到回归模型的变量称为独立变量或预测变量或特征,而回归模型的输出变量称为因变量或目标。回归模型定义如下:
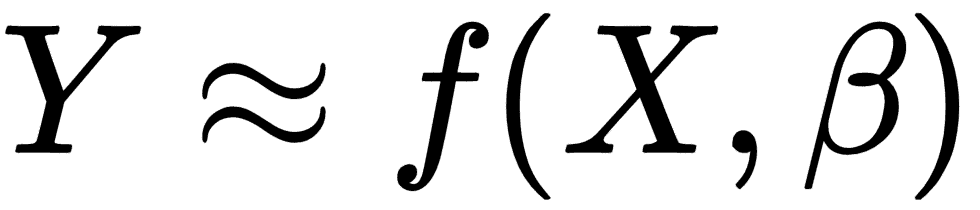
其中Y是目标变量,X是特征向量,β是参数向量
通常,我们使用一种非常简单的回归形式,称为简单线性回归来估计参数 β。
在机器学习问题中,我们必须从给定数据中学习模型参数 β0和β1,以便我们有一个估计模型,从X的未来值预测Y的值。我们对偏置使用β1,对权重项使用β0,分别用w和b代表它们。
因此模型如下:

分类是机器学习中的经典问题之一。正在考虑的数据可以属于一个或其他类别,例如,如果提供的图像是数据,则它们可以是猫或狗的图片。因此,在这种情况下,类别是猫和狗。分类是指识别或识别所考虑的数据或对象的标签或类别。分类属于监督机器学习的范畴。在分类问题中,提供具有特征或输入及其相应输出或标签的训练数据集。使用该训练数据集,训练模型;换句话说,计算模型的参数。然后将训练的模型用于新数据以找到其正确的标签。
分类问题可以有两种类型:两类或多类。两类意味着数据被分类为两个不同且不连续的标签,例如,患者患有癌症或患者没有癌症,图像是猫或狗。多类意味着数据将被分类到多个类别中,例如,电子邮件分类问题会将电子邮件分成社交媒体电子邮件,与工作相关的电子邮件,个人电子邮件,与家人相关的电子邮件,垃圾邮件,购物优惠电子邮件等等。 。另一个例子是数字图片的例子;每张图片可以标记在 0 到 9 之间,具体取决于图片所代表的数字。在本章中,我们将看到两种分类的示例。
在本章中,我们将进一步扩展以下主题:
- 回归
- 简单的线性回归
- 多元回归
- 正则化回归
- 套索正则化
- 岭正则化
- ElasticNet 正则化
- 分类
- 使用逻辑回归进行分类
- 二分类
- 多类分类