分布式执行策略
为了在多个设备或节点上分发单个模型的训练,有以下策略:
- 模型并行:将模型划分为多个子图,并将单独的图放在不同的节点或设备上。子图执行计算并根据需要交换变量。
- 数据并行:将数据分组并在多个节点或设备上运行相同的模型,并在主节点上组合参数。因此,工作节点在批量数据上训练模型并将参数更新发送到主节点,也称为参数服务器。
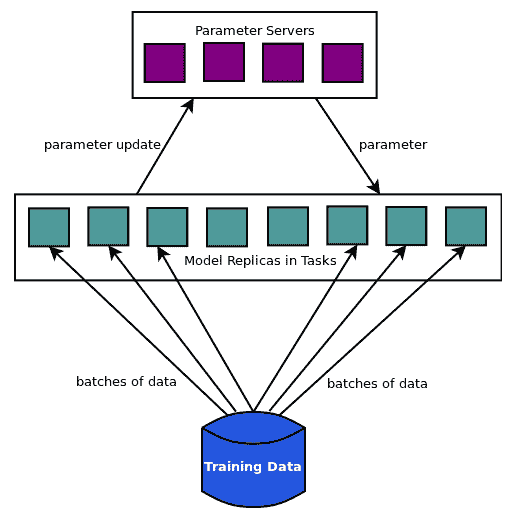
上图显示了数据并行方法,其中模型副本分批读取数据分区并将参数更新发送到参数服务器,参数服务器将更新的参数发送回模型副本以进行下一次批量计算的更新。
在 TensorFlow 中,有两种方法可以在数据并行策略下在多个节点/设备上实现模型的复制:
- 图中复制:在这种方法中,有一个客户端任务拥有模型参数,并将模型计算分配给多个工作任务。
- 图之间复制:在这种方法中,每个客户端任务都连接到自己的工作者以分配模型计算,但所有工作器都更新相同的共享模型。在此模型中,TensorFlow 会自动将一个工作器指定为主要工作器,以便模型参数仅由主要工作器初始化一次。
在这两种方法中,参数服务器上的参数可以通过两种不同的方式更新:
- 同步更新:在同步更新中,参数服务器等待在更新梯度之前从所有工作器接收更新。参数服务器聚合更新,例如通过计算所有聚合的平均值并将其应用于参数。更新后,参数将同时发送给所有工作器。这种方法的缺点是一个慢工作者可能会减慢每个人的更新速度。
- 异步更新:在异步更新中,工作器在准备好时将更新发送到参数服务器,然后参数服务器在接收更新时应用更新并将其发回。这种方法的缺点是,当工作器计算参数并发回更新时,参数可能已被其他工作器多次更新。这个问题可以通过几种方法来减轻,例如降低批量大小或降低学习率。令人惊讶的是,异步方法甚至可以工作,但实际上,它们确实有效!