深度强化学习
强化学习是一种学习形式,其中软件智能体观察环境并采取行动以最大化其对环境的奖励,如下图所示:
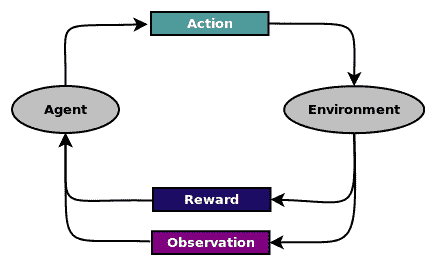
这个比喻可以用来表示现实生活中的情况,如下所示:
- 股票交易智能体观察交易信息,新闻,分析和其他形式信息,并采取行动买入或卖出交易,以便以短期利润或长期利润的形式最大化奖励。
- 保险智能体观察有关客户的信息,然后采取行动确定保险费金额,以便最大化利润并最大限度地降低风险。
- 类人机器人观察环境然后采取行动,例如步行,跑步或拾取物体,以便在实现目标方面最大化奖励。
强化学习已成功应用于许多应用,如广告优化,股票市场交易,自动驾驶汽车,机器人和游戏,仅举几例。
强化学习与监督学习不同,因为预先没有标签来调整模型的参数。该模型从运行中获得的奖励中学习。虽然短期奖励可以立即获得,但只有经过几个步骤才能获得长期奖励。这种现象也称为延迟反馈。
强化学习也与无监督学习不同,因为在无监督学习中没有可用的标签,而在强化学习中,反馈可用于奖励。
在本章中,我们将通过涵盖以下主题来了解强化学习及其在 TensorFlow 和 Keras 中的实现:
- OpenAI Gym 101
- 将简单的策略应用于 cartpole 游戏
- 强化学习 101
- Q 函数
- 探索和开发
- V 函数
- RL 技术
- RL 的简单神经网络策略
- 实现 Q-Learning
- Q-Learning 的初始化和离散化
- 使用 Q-Table 进行 Q-Learning
- 深度 Q 网络:使用 Q-Network 进行 Q-Learning
我们将在 OpenAI Gym 中演示我们的示例,让我们首先了解一下 OpenAI Gym。