生成性对抗网络 101
如下图所示,Generative Adversarial Networks(通常称为 GAN)有两个同步工作模型,用于学习和训练复杂数据,如图像,视频或音频文件:
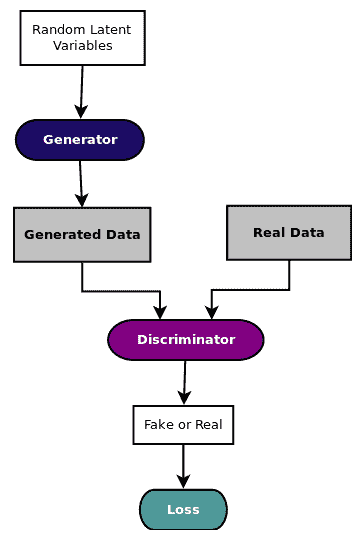
直观地,生成器模型从随机噪声开始生成数据,但是慢慢地学习如何生成更真实的数据。生成器输出和实际数据被馈送到判别器,该判别器学习如何区分假数据和真实数据。
因此,生成器和判别器都发挥对抗性游戏,其中生成器试图通过生成尽可能真实的数据来欺骗判别器,并且判别器试图不通过从真实数据中识别伪数据而被欺骗,因此判别器试图最小化分类损失。两个模型都以锁步方式进行训练。
在数学上,生成模型G(z)学习概率分布p(z),使得判别器D(G(z), x)无法在概率分布p(z)和p(x)之间进行识别。 GAN 的目标函数可以通过下面描述值函数V的等式来描述,(来自 https://papers.nips.cc/paper/5423-generative-adversarial-nets.pdf ):
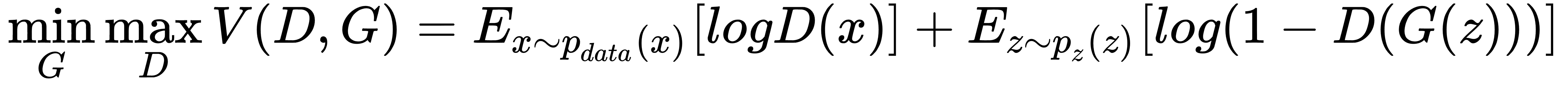
可以在以下链接中找到 IAN Goodfellow 在 NIPS 2016 上关于 GAN 的开创性教程:
https://arxiv.org/pdf/1701.00160.pdf.
这个描述代表了一个简单的 GAN(在文献中也称为香草 GAN),由 Goodfellow 在此链接提供的开创性论文中首次介绍: https://arxiv.org/abs/1406.2661 。从那时起,在基于 GAN 推导不同架构并将其应用于不同应用领域方面进行了大量研究。
例如,在条件 GAN 中,为生成器和判别器网络提供标签,使得条件 GAN 的目标函数可以通过以下描述值函数V的等式来描述:
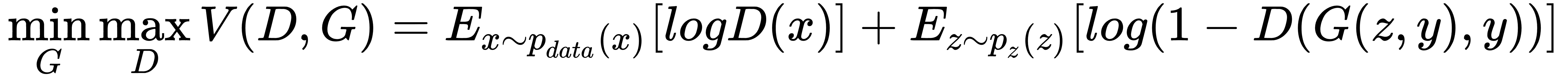
描述条件 GAN 的原始论文位于以下链接: https://arxiv.org/abs/1411.1784。
应用中使用的其他几种衍生产品及其原始论文,如文本到图像,图像合成,图像标记,样式转移和图像转移等,如下表所示:
| GAN 衍生物 | 原始文件 | 演示申请 |
|---|---|---|
| StackGAN | https://arxiv.org/abs/1710.10916 | 文字到图像 |
| StackGAN ++ | https://arxiv.org/abs/1612.03242 | 逼真的图像合成 |
| DCGAN | https://arxiv.org/abs/1511.06434 | 图像合成 |
| HR-DCGAN | https://arxiv.org/abs/1711.06491 | 高分辨率图像合成 |
| 有条件的 GAN | https://arxiv.org/abs/1411.1784 | 图像标记 |
| InfoGAN | https://arxiv.org/abs/1606.03657 | 风格识别 |
| Wasserstein GAN | https://arxiv.org/abs/1701.07875https://arxiv.org/abs/1704.00028 | 图像生成 |
| 耦合 GAN | https://arxiv.org/abs/1606.07536 | 图像转换,域适应 |
| BEGAN | https://arxiv.org/abs/1703.10717 | Image Generation |
| DiscoGAN | https://arxiv.org/abs/1703.05192 | 风格转移 |
| CycleGAN | https://arxiv.org/abs/1703.10593 | Style Transfer |
让我们练习使用 MNIST 数据集创建一个简单的 GAN。在本练习中,我们将使用以下函数将 MNIST 数据集标准化为介于[-1,+ 1]之间:
def norm(x):
return (x-0.5)/0.5
我们还定义了 256 维的随机噪声,用于测试生成器模型:
n_z = 256
z_test = np.random.uniform(-1.0,1.0,size=[8,n_z])
显示将在本章所有示例中使用的生成图像的函数:
def display_images(images):
for i in range(images.shape[0]): plt.subplot(1, 8, i + 1)
plt.imshow(images[i])
plt.axis('off')
plt.tight_layout()
plt.show()