强化学习 101
强化学习由智能体从前一个时间步骤输入观察和奖励并以动作产生输出来描述,目标是最大化累积奖励。
智能体具有策略,值函数和模型:
智能体用于选择下一个动作的算法称为策略。在上一节中,我们编写了一个策略,它将采用一组参数 theta,并根据观察和参数之间的乘法返回下一个动作。该策略由以下等式表示:

S是一组状态,A是一组动作。策略是确定性的或随机性的。
确定性策略在每次运行中为相同状态返回相同的操作:
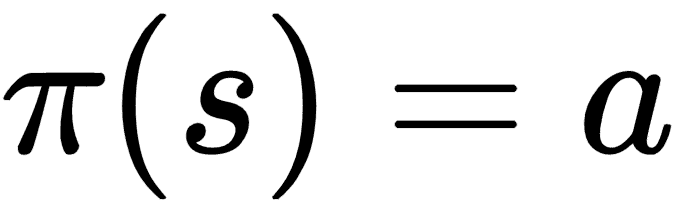
随机策略为每次运行中的相同状态返回相同操作的不同概率:

值函数根据当前状态中的所选动作预测长期奖励的数量。因此,值函数特定于智能体使用的策略。奖励表示行动的直接收益,而价值函数表示行动的累积或长期未来收益。奖励由环境返回,价值函数由智能体在每个时间步骤估计。
模型表示智能体在内部保存的环境。该模型可能是环境的不完美表示。智能体使用该模型来估计所选动作的奖励和下一个状态。
智能体的目标还可以是为马尔可夫决策过程(MDP)找到最优策略。 MDP 是从一个州到另一个州的观察,行动,奖励和过渡的数学表示。为简洁起见,我们将省略对 MDP 的讨论,并建议好奇的读者在互联网上搜索更深入 MDP 的资源。