使用 TensorFlow 中的再训练的 VGG16 进行图像分类
现在,我们将为 COCO 动物数据集再训练 VGG16 模型。让我们从定义三个占位符开始:
is_training占位符指定我们是否将模型用于训练或预测x_p是输入占位符,形状为(None, image_height, image_width, 3)y_p是输出占位符,形状为(None, 1)
is_training = tf.placeholder(tf.bool,name='is_training')
x_p = tf.placeholder(shape=(None,image_height, image_width,3),
dtype=tf.float32,name='x_p')
y_p = tf.placeholder(shape=(None,1),dtype=tf.int32,name='y_p')
正如我们在策略部分中所解释的那样,我们将从检查点文件中恢复除最后一层之外的层,这被称为 vgg/fc8 层:
with slim.arg_scope(vgg.vgg_arg_scope()):
logits, _ = vgg.vgg_16(x_p,num_classes=coco.n_classes,
is_training=is_training)
probabilities = tf.nn.softmax(logits)
# restore except last last layer fc8
fc7_variables=tf.contrib.framework.get_variables_to_restore(exclude=['vgg_16/fc8'])
fc7_init = tf.contrib.framework.assign_from_checkpoint_fn(
os.path.join(model_home, '{}.ckpt'.format(model_name)),
fc7_variables)
接下来,定义要初始化但未恢复的最后一个层的变量:
# fc8 layer
fc8_variables = tf.contrib.framework.get_variables('vgg_16/fc8')
fc8_init = tf.variables_initializer(fc8_variables)
正如我们在前面章节中所学到的,用tf.losses. sparse_softmax_cross_entropy()定义损失函数。
tf.losses.sparse_softmax_cross_entropy(labels=y_p, logits=logits)
loss = tf.losses.get_total_loss()
训练最后一层几个周期,然后训练整个网络几层。因此,定义两个单独的优化器和训练操作。
learning_rate = 0.001
fc8_optimizer = tf.train.GradientDescentOptimizer(learning_rate)
fc8_train_op = fc8_optimizer.minimize(loss, var_list=fc8_variables)
full_optimizer = tf.train.GradientDescentOptimizer(learning_rate)
full_train_op = full_optimizer.minimize(loss)
我们决定对两个优化器函数使用相同的学习率,但如果您决定进一步调整超参数,则可以定义单独的学习率。
像往常一样定义精度函数:
y_pred = tf.to_int32(tf.argmax(logits, 1))
n_correct_pred = tf.equal(y_pred, y_p)
accuracy = tf.reduce_mean(tf.cast(n_correct_pred, tf.float32))
最后,我们运行最后一层 10 个周期的训练,然后使用批量大小为 32 的 10 个周期的完整网络。我们还使用相同的会话来预测类:
fc8_epochs = 10
full_epochs = 10
coco.y_onehot = False
coco.batch_size = 32
coco.batch_shuffle = True
total_images = len(x_train_files)
n_batches = total_images // coco.batch_size
with tf.Session() as tfs:
fc7_init(tfs)
tfs.run(fc8_init)
for epoch in range(fc8_epochs):
print('Starting fc8 epoch ',epoch)
coco.reset_index()
epoch_accuracy=0
for batch in range(n_batches):
x_batch, y_batch = coco.next_batch()
images=np.array([coco.preprocess_for_vgg(x) \
for x in x_batch])
feed_dict={x_p:images,y_p:y_batch,is_training:True}
tfs.run(fc8_train_op, feed_dict = feed_dict)
feed_dict={x_p:images,y_p:y_batch,is_training:False}
batch_accuracy = tfs.run(accuracy,feed_dict=feed_dict)
epoch_accuracy += batch_accuracy
except Exception as ex:
epoch_accuracy /= n_batches
print('Train accuracy in epoch {}:{}'
.format(epoch,epoch_accuracy))
for epoch in range(full_epochs):
print('Starting full epoch ',epoch)
coco.reset_index()
epoch_accuracy=0
for batch in range(n_batches):
x_batch, y_batch = coco.next_batch()
images=np.array([coco.preprocess_for_vgg(x) \
for x in x_batch])
feed_dict={x_p:images,y_p:y_batch,is_training:True}
tfs.run(full_train_op, feed_dict = feed_dict )
feed_dict={x_p:images,y_p:y_batch,is_training:False}
batch_accuracy = tfs.run(accuracy,feed_dict=feed_dict)
epoch_accuracy += batch_accuracy
epoch_accuracy /= n_batches
print('Train accuracy in epoch {}:{}'
.format(epoch,epoch_accuracy))
# now run the predictions
feed_dict={x_p:images_test,is_training: False}
probs = tfs.run([probabilities],feed_dict=feed_dict)
probs=probs[0]
让我们看看打印我们的预测结果:
disp(images_test,id2label=coco.id2label,probs=probs,scale=True)
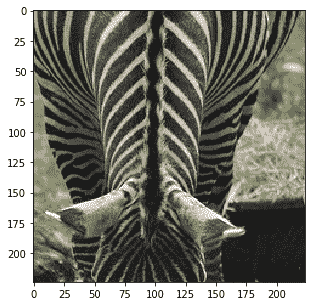
Probability 100.00% of [zebra]
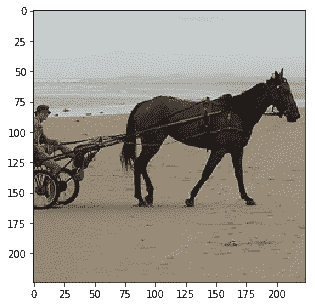
Probability 100.00% of [horse]
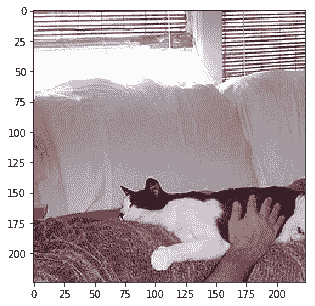
Probability 98.88% of [cat]
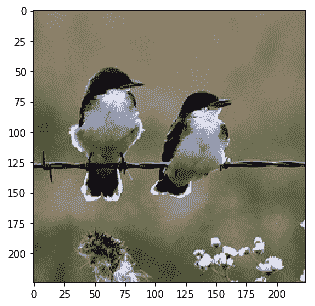
Probability 100.00% of [bird]
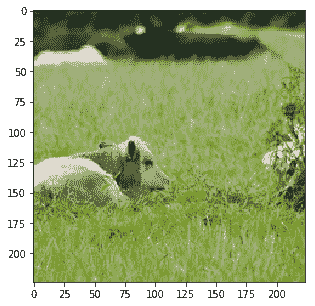
Probability 68.88% of [bear]
Probability 31.06% of [sheep]
Probability 0.02% of [dog]
Probability 0.02% of [bird]
Probability 0.01% of [horse]
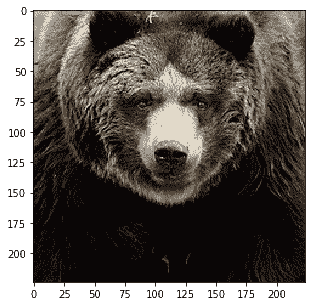
Probability 100.00% of [bear]
Probability 0.00% of [dog]
Probability 0.00% of [bird]
Probability 0.00% of [sheep]
Probability 0.00% of [cat]
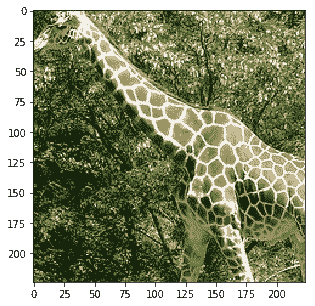
Probability 100.00% of [giraffe]

Probability 61.36% of [cat]
Probability 16.70% of [dog]
Probability 7.46% of [bird]
Probability 5.34% of [bear]
Probability 3.65% of [giraffe]
它正确识别了猫和长颈鹿,并将其他概率提高到 100%。它仍然犯了一些错误,因为最后一张照片被归类为猫,这实际上是裁剪后的噪音图片。我们会根据这些结果对您进行改进。